مدلهای یادگیری ماشین نقش قابلتوجهی در بسیاری از صنایع و کاربردها ایفا میکنند. بهگونهای که باعث تغییر رویکرد ما برای قلبهبر مسائل پیچیده و اتخاذ تصمیمات آگاهانه شدهاند. کاربرد مدلهای یادگیری ماشین تنها به یک زمینه محدود نشده و از امور مالی و فروشگاهی گرفته تا پژوهشهای علمی و بازاریابی مورد استفاده قرار میگیرند. از جمله ویژگیهای متمایزکننده این مدلها میتوان به قابلیت تفسیر حجم بالای داده، شناسایی الگو و ارائه اطلاعات ارزشمند اشاره کرد. در این مطلب از مجله فرادرس به بررسی مفهوم یادگیری ماشین و همچنین معرفی برخی از رایجترین انواع مدل های یادگیری ماشین میپردازیم. مدلهایی که به دانشمندان علم داده این امکان را میدهند تا درک مناسبی از دیتاستهای بزرگ بهدست آورده و شرکتها نیز با کشف زودهنگام رویدادها، قادر به حفظ مزیت رقابتی خود خواهند بود.


در این مطلب، ابتدا با مفهوم یادگیری ماشین و همچنین مدلهای یادگیری ماشین آشنا میشویم. سپس به این پرسش پاسخ میدهیم که دلیل استفاده از مدلهای یادگیری ماشین چیست و در انتهای این مطلب از مجله فرادرس نیز ۸ مورد از کاربردیترین انواع مدل های یادگیری ماشین را معرفی میکنیم.
مفهوم یادگیری ماشین
یادگیری ماشین یا ماشین لرنینگ زیرشاخهای از هوش مصنوعی است که کامپیوترها را قادر میسازد تا بدون نیاز به کدنویسی، از تجربیات کسب شده خود یاد بگیرند. به بیان ساده، یادگیری ماشین بخشی از هوش مصنوعی است. بنابراین در حالی که میتوان همه مدلهای یادگیری ماشین را مدل هوشمند در نظر گرفت، برعکس این موضوع، گزاره همیشه درستی نیست. برخلاف روشهای قدیمی که از معادلات از پیش تعیین شده برای یادگیری استفاده میکنند، مدلهای یادگیری ماشین تنها و بهطور مستقیم از طریق دادههای ورودی آموزش میبینند.

منظور از مدل در یادگیری ماشین چیست؟
هر مدل در یادگیری ماشین یک الگوریتم است که پارامترهای آن بهواسطه نوعی فرایند یادگیری آماری مشخص یا آموزش دیدهاند. در عمل، مدل یادگیری ماشین یک برنامه کامپیوتری است که برای اجرای وظایف محول شده به آن نیازی به راهنمایی مستقیم انسان ندارد. در روشهای برنامهنویسی سنتی، فرد توسعهدهنده با مشخص کردن قواعدی که کامپیوتر هنگام اجرا ملزم به پیروی از آنها است، بهاصطلاح برنامهای مینویسد. اما در یادگیری ماشین از کامپیوتر خواسته میشود یک الگوریتم یادگیری را تا زمان تولید مجموعهای از قواعد منطبقبر هدف، با دیتاستی مشخص اجرا کند. این مجموعه قواعد در حقیقت همان مدل یادگیری ماشین بوده و طی این فرایند آموزش میبیند. مجموعه فرادرس دوره آموزشی کوتاه و رایگانی را با عنوان فیلم آموزش یادگیری ماشین با پایتون منتشر کرده است که برای آشنایی اولیه با مفاهیمی همچون مدل در یادگیری ماشین میتوانید آن را از طریق لینک زیر مشاهده کنید:

یادگیری ماشین و همچنین مدلهای یادگیری از این جهت بسیار موثر هستند که پس از آموزش و بدون راهنمایی، میتوانند از آموختههای خود برای حل مسائل متفاوتی استفاده میکنند. علاوهبر آن، گروهی از مدلها تحت عنوان مدلهای مولد، میتوانند نحوه تولید دادههای جدید را نیز یاد بگیرند. مدلهای DALL-E، Midjourney و Stable Diffusion از جمله این مدلهای پرطرفدار هستند که برای تولید تصاویر هنری و خلاقانه از آنها استفاده میشود.
آموزش نحوه انتخاب مدل در یادگیری ماشین با فرادرس

یکی از گامهای کلیدی در پروژههای یادگیری ماشین، انتخاب مدل مناسب است. اما قبل از پرداختن به این مرحله، لازم است تا مفاهیم پایه و اساسی یادگیری ماشین را به درستی فرا بگیریم. مفاهیمی همچون روشهای کلاسیک، انواع الگوریتمهای یادگیری ماشین و اصول نظری که پایه و اساس این حوزه را شکل میدهند. داشتن درکی عمیق از این مبانی نه تنها برای انتخاب درست مدل ضروری است، بلکه برای پیادهسازی موفق مدلها با استفاده از ابزارها و زبانهای برنامهنویسی مرتبط مانند پایتون نیز الزامی خواهد بود.
پس از کسب مهارت در مفاهیم پایه، باید به سراغ فرایند انتخاب مدل مناسب برای هر مسئله یادگیری ماشین برویم. انتخاب مدل نامناسب میتواند منجر به نتایج نادرست، افت عملکرد و در نهایت شکست پروژه شود. برای این انتخاب باید عواملی مانند ماهیت مسئله، نوع و کیفیت دادهها، محدودیتهای موجود و معیارهای ارزیابی را در نظر گرفت. همچنین لازم است تا بین مدلهای مختلف یادگیری ماشین از جمله خطی و غیرخطی، ساده و پیچیده تصمیمگیری کنید. فرایندی که نیازمند دانش تخصصی و تجربه کافی در حوزه یادگیری ماشین است.
برای کسب مهارت در مفاهیم اولیه یادگیری ماشین، پیادهسازی با زبان برنامهنویسی پایتون و انتخاب مدل، پلتفرم آموزشی فرادرس، مجموعه جامعی از فیلمهای آموزشی را تهیه کرده است که مشاهده آنها را به ترتیبی که در ادامه آمده است به شما پیشنهاد میکنیم:
با گذراندن این دورهها، شما نه تنها با مبانی یادگیری ماشین آشنا میشوید، بلکه توانایی پیادهسازی مدلها با پایتون و انتخاب مدل مناسب برای هر مسئله را نیز کسب خواهید کرد. این امر برای موفقیت در پروژههای آینده شما در حوزه یادگیری ماشین بسیار حیاتی است.
دلیل استفاده از مدل های یادگیری ماشین چیست؟
روزانه سازمانهای بسیاری از انواع مدل های یادگیری ماشین برای افزایش درآمد و رشد کسبوکار خود استفاده میکنند. یادگیری ماشین کاربردهای متنوعی دارد. برای مثال سرویسهای اشتراکمحور مانند Netflix و Spotify از یادگیری ماشین برای پیشنهاد محتوا بر اساس فعالیتهای پیشین کاربر بهره میبرند. از آنجا که تجربه کاربری بهتر، از جمله موارد مهمی است که افراد را به تمدید اشتراک خود ترغیب میکند، سیستمهای توصیهگر باعث بالا رفتن ارزش چنین کسبوکارهایی میشوند. بهطور مشابه ممکن است یک سرویسدهنده خدمات تلفن همراه از یادگیری ماشین برای تجزیه و تحلیل دیدگاه کاربران و ارائه خدماتی مطابق با نیاز بازار استفاده کند.

معرفی انواع مدل های یادگیری ماشین
انواع مدل های یادگیری ماشین را میتوان به دو گروه «نظارت شده» و «نظارت نشده» تقسیم کرد. مهمترین تفاوت میان این دو گروه در نوع دادههای ورودی و خروجی است. به این صورت که ورودی الگوریتمهای نظارت شده را دادههای برچسبدار تشکیل میدهند و الگوریتمهای نظارت نشده از دادههای خام و دیتاستهای بدون برچسب برای آموزش استفاده میکنند. در ادامه این بخش، به معرفی مدلهای «رگرسیون»، «طبقهبندی» و «مبتنیبر درخت» از الگوریتمهای نظارت شده و مدل یادگیری ماشین «خوشهبندی» از گروه الگوریتمهای نظارت نشده میپردازیم.
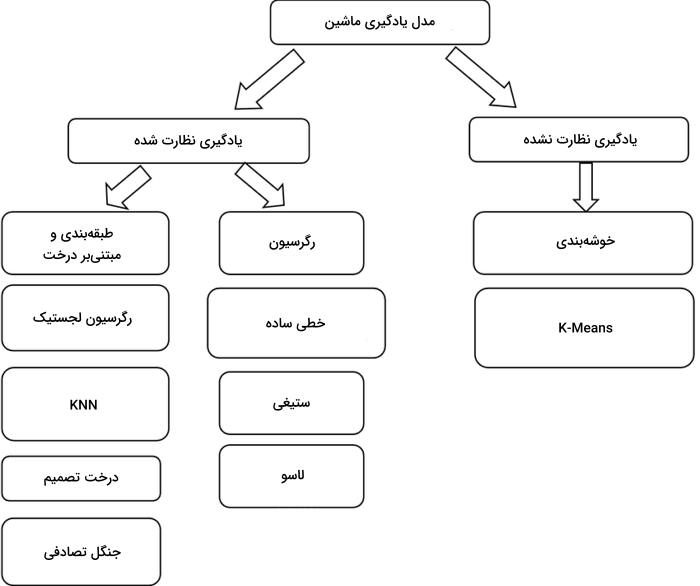
مدل های رگرسیون
الگوریتمهای رگرسیونی، برای پیشبینی مقادیر خروجی پیوسته از متغیرهای ورودی مستقل، مورد استفاده قرار میگیرند. به عنوان مثال جدول زیر را در نظر بگیرید:
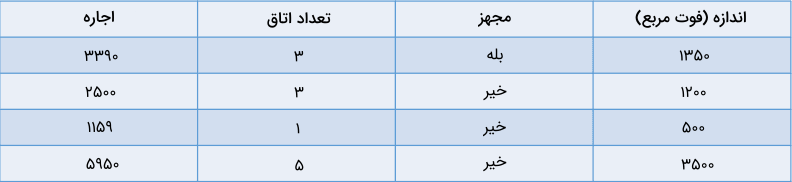
در این مثال میخواهیم «اجارهخانه» را به دلار و بر اساس «اندازه»، «تعداد اتاق» و «مجهز بودن یا نبودن» آن پیشبینی کنیم. عددی و پیوسته بودن متغیر وابسته یا همان اجارهخانه، این مسئله را در گروه مسائل رگرسیونی قرار میدهد. بهطور دقیقتر، چنین مسائلی که تعداد متغیرهای ورودی زیادی دارند را رگرسیون «چندمتغیره» مینامند.
معیار های رگرسیونی
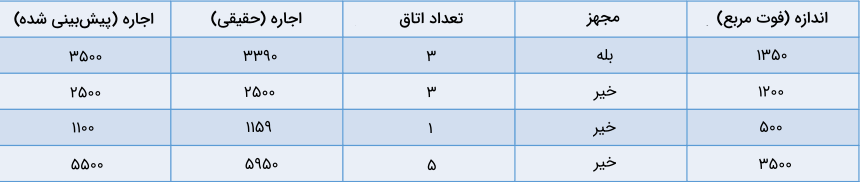
یکی از اشتباهات رایج افراد مبتدی در حوزه علم داده این است که ارزیابی مدلهای رگرسیونی را با معیاری مانند «دقت» یا Accuracy انجام میدهند. اما همانطور که بیشتر در ادامه توضیح میدهیم، دقت، معیاری مناسب برای سنجش عملکرد انواع مدلهای طبقهبندی است. از طرف دیگر، سنجش مدلهای رگرسیونی با استفاده از معیارهایی مانند «میانگین قدرمطلق خطا» (MAE)، «میانگین مربعات خطا» (MSE) و «جذر میانگین مربعات خطا» (RMSE) انجام میشود. با همان مثال «اجارهخانه» ادامه میدهیم و پس از اضافه کردن ستونی شامل مقادیر پیشبینی شده، معیارهای مختلف رگرسیونی را با هم مقایسه میکنیم:
۱. میانگین قدرمطلق خطا
در معیار میانگین قدرمطلق خطا یا MAE ابتدا از مقادیر پیشبینی شده و حقیقی تفاضل گرفته میشود و پس از محاسبه حاصل جمع تمام نمونهها، نتیجه بهدست آمده بر تعداد کل نمونه دادهها تقسیم میشود. فرمول محاسبه MAE مانند زیر است:
برای محاسبه MAE در مثال اجارهخانه مانند زیر عمل میکنیم:
بهطور تقریبی، میانگین قدرمطلق خطای بین قیمتهای حقیقی و پیشبینی شده خانهها برابر با ۱۵۵ دلار است.
۲. میانگین مربعات خطا
محاسبه معیار MSE یک مدل شباهت زیادی با MAE داشته و مانند نمونه انجام میشود:
توجه داشته باشید که در MAE میانگین قدرمطلق تفاضلِ مقادیر حقیقی و پیشبینی شده محاسبه میشود اما در MSE، از مربع تفاضل مقادیر حقیقی و پیشبینی شده میانگین گرفته میشود. برای بهدست آوردن MSE در مثال اجارهخانه مانند زیر عمل میکنیم:
۳. جذر میانگین مربعات خطا
همانطور که از عنوان آن نیز مشخص است، معیار RMSE با جذر گرفتن از میانگین مربعات خطا بهدست میآید. محاسبه RMSE یک دیتاست بهجای MSE این مزیت را دارد که واحد خطای نهایی با متغیرهای پیشبینی شده یکسان است. در مثال اجارهخانه، محاسبه معیار RMSE به شرح زیر است:
برخلاف MSE، نتیجه حاصل شده در این روش قابل تفسیر بوده و مقدار نهایی یعنی ۲۳۳/۵، به «دلار» یا همان واحد قیمت اجارهخانهها محاسبه شده است. حالا و پس از آشنایی با مفهوم رگرسیون، در ادامه این بخش نگاهی به انواع مدل های یادگیری ماشین رگرسیونی میاندازیم.
رگرسیون خطی ساده
رگرسیون خطی، روشی ساده و خطی برای نشان دادن ارتباط میان یک متغیر وابسته و یک یا چند متغیر مستقل است. هدف از این الگوریتم پیدا کردن خطی است که بهترین پوشش یا برازش را بر دادهها داشته باشد. در تصویر زیر نمایی از نحوه کارکرد مدل رگرسیون خطی ساده را مشاهده میکنید:

نمودار بهتصویر کشیده شده، ارتباط میان قیمت و اندازه خانهها را نشان میدهد. خطوطی که با رنگهای آبی، سبز و نارنجی ترسیم شدهاند، بیانگر انواع مختلف مدلهای رگرسیونی هستند که هر کدام دامنه متفاوتی از نمونهها را پوشش میدهد. خطی با بیشترین پوشش از نمونهها را به اصطلاح «بهترین برازش» (Best Fit) مینامند.
بهترین برازش
تنها با نگاه کردن به نمودار فوق متوجه میشویم که خط نارنجی بیشترین نزدیکی را با نمونهها دارد. پس میتوانیم خط نارنجی را همان بهترین برازش در نظر بگیریم. اما اگر بخواهیم کمی دقیقتر به بررسی نحوه یافتن خطی با بهترین برازش بپردازیم، ابتدا باید معادله خط صاف را بهخاطر بیاوریم:
در این عبارت، حرف و به ترتیب نماد «شیب خط» و «عرض از مبدأ» هستند. از آنجا که بینهایت مقدار برای و وجود دارد، میتوان نتیجه گرفت که بینهایت خط نیز قابل ترسیم است. از بهترین برازش با عنوان «خط رگرسیونی حداقل مربعات» نیز یاد میشود که با کمینهسازی معیار MSE بهدست میآید. در مطلب زیر از مجله فرادرس، بهطور مفصل درباره معادله خط توضیح دادهایم:
رگرسیون ستیغی
رویکردی توسعه یافته از رگرسیون خطی که در بخش قبل آن را بررسی کردیم. از «رگرسیون ستیغی» (Ridge Regression) برای کمینه نگه داشتن پارامترهای (ضرایب) مدل استفاده میشود. یکی از معیاب مدل رگرسیون خطی ساده این است که امکان دارد ضرایب، بیش از حد بزرگ شده و حساسیت مدل نسبت به ورودیها افزایش یابد. مشکلی که در نهایت به «بیشبرازش» منجر میشود. برای درک بهتر مفهوم بیشبرازش، نمودار زیر را در نظر داشته باشید:

در نمودار فوق، خط (مدل) بهطور کامل بر نقاط داده برازش بوده و معیار MSE برابر با صفر است. در حالی که بهترین برازش نسبت به نمونههای مجموعه آموزشی حاصل شده است، به احتمال زیاد مدل نتواند این عملکرد عالی را در مقابل دادههای جدید نیز از خود به نمایش بگذارد. رخدادی که بیشبرازش نام داشته و مطلب کاملتری در مورد آن از مجله فرادرس منتشر شده که میتوانید با مراجعه به لینک زیر آن را مطالعه کنید:
به بیان ساده، مدلی که پیچیدگی زیادی داشته باشد، جزییات نامرتبطی را با نمونههای جدید و کاربردی از مجموعه آموزشی یاد میگیرد. در نتیجه با وجود اینکه عملکرد مدل نسبت به مجموعه آموزشی قابل توجه خواهد بود، در مقابل دادههای جدید بسیار ضعیف عمل میکند. مدلهای رگرسیون خطی با ضرایب بزرگ، در معرض بیشبرازش قرار دارند. رگرسیون ستیغی یک تکنیک «منظمسازی» است که با افزودن هزینهای اضافه به تابع زیان، الگوریتم را جریمه و مجبور به انتخاب ضرایب کوچکتر میکند. همانگونه که در بخش قبل نیز یاد گرفتیم، عبارت زیر همان تابع زیانی است که در رگرسیون خطی ساده قصد کمینه کردن آن را داریم:
در رگرسیون ستیغی اما یک «مقدار جریمه» (Penalty Term) نیز به تابع اضافه میشود:
مطابق با آنچه که در عبارت فوق مشاهده میکنید، مقدار «لامبدا» (Lambda) که با نماد مشخص شده است، در پارامترهای مدل ضرب میشود. از آنجا که این مدل یک پارامتر () دارد، مقدار جریمه تنها بر همین پارامتر اعمال شده است. اما اگر با چندین متغیر مستقل مواجه باشیم، مقدار لامبدا در مجموع مربعات پارامترها ضرب میشود. این جریمه به نوعی مدل را بهخاطر انتخاب ضرایب بزرگ تنبیه میکند. در حقیقت ضرایب به اندازهای کوچک میشوند که مقدار متغیرهای کماهمیت در آموزش مدل به صفر میل کند. در نتیجه از «واریانس» مدل کاسته شده و احتمال رخداد بیشبرازش نیز کاهش مییابد.
مقدار بهینه لامبدا برای رگرسیون ستیغی
توجه دارید که اگر لامبدا برابر با صفر باشد، در واقع هیچ اثری نداشته و مقدار جریمه حذف میشود. اما هر چقدر لامبدا بزرگتر باشد، جریمه سنگینتر شده و ضرایب مدل به صفر نزدیکتر میشوند. هنگام انتخاب مقدار لامبدا، باید میان سادگی و برازشی قابل قبول توازن برقرار کنید. اگر مقدار لامبدا بیش از حد زیاد باشد، احتمال وقوع مشکل «کمبرازش» افزایش مییابد. از طرف دیگر، انتخاب مقدار نزدیک به صفر برای لامبدا نیز به مدلی بسیار پیچیده ختم میشود.
رگرسیون لاسو
در این تکنیک نیز مانند رگرسیون ستیغی، مقدار جریمهای مشخص برای کاهش ضرایب مدل به تابع زیان اضافه میشود. در «رگرسیون لاسو» تابع زیان به شکل زیر است:
تفاوت رگرسیون لاسو با روش قبلی در این است که بهجای مربع ضرایب، مقدار لامبدا در قدرمطلق پارامترها ضرب میشود. مهمترین تفاوت رگرسیون ستیغی و لاسو در کمترین مقداری است که ضرایب میتوانند به خود بگیرند. در رگرسیون ستیغی ضرایب هر چقدر هم که به صفر نزدیک باشند اما برابر با صفر نمیشوند. اما در رگرسیون لاسو ممکن است ضرایب مدل مقداری برابر با صفر داشته باشند.
برابری ضریب یک متغیر مستقل با صفر به این معناست که میتوان آن ویژگی را از فرایند آموزش مدل حذف کرد. به این صورت فضای ویژگی کاهش یافته و تفسیر الگوریتم یادگیری نیز سادهتر میشود. بهخاطر چنین قابلیتی، میتوان از رگرسیون لاسو به عنوان یک تکنیک «انتخاب ویژگی» نیز استفاده کرد. زیرا متغیرهای کماهمیت مقداری برابر با صفر داشته و نقشی در آموزش مدل ندارند.
ساخت مدل های یادگیری ماشین رگرسیونی در پایتون
پس از آشنایی با یکی از انواع مدل های یادگیری ماشین، در این بخش بهطور مختصر از نحوه پیادهسازی سه مدل رگرسیون خطی، ستیغی و لاسو با کمک زبان برنامهنویسی پایتون و کتابخانه Scikit-learn میگوییم.
۱. رگرسیون خطی
ابتدا کلاس LinearRegression
را بارگذاری کرده و سپس شیئی با نام lr_model
از آن میسازیم:
1from sklearn.linear_model import LinearRegression
2
3
4lr_model = LinearRegression()برای برازش مدل بر روی مجموعه آموزشی، متد fit()
را فراخوانی میکنیم:
1lr_model.fit(X_train, y_train)دقت داشته باشید که متغیر X_train
شامل متغیرهای مستقل دیتاست یا همان ویژگیها و متغیر y_train
از متغیر وابسته یا همان پاسخها تشکیل شده است.
۲. رگرسیون ستیغی
در اینجا ابتدا کلاس Ridge
را بارگذاری و شیئی تحت عنوان ri_model
از آن تعریف میکنیم:
1from sklearn.linear_model import Ridge
2
3
4ri_model = Ridge(alpha=1.0)با تعیین پارامتر alpha
در کلاس Ridge
مقدار جریمه یا لامبدا مشخص میشود.
۳. رگرسیون لاسو
برای پیادهسازی رگرسیون لاسو، ابتدا کلاس Lasso
را از کتابخانه Scikit-learn فراخوانی و سپس متغیری با نام la_model
از آن میسازیم:
1from sklearn.linear_model import Lasso
2
3
4la_model = Lasso(alpha=1.0)پارامتر alpha
در کلاس Lasso
نقش معیار لامبدا را داشته و برازش هر دو روش ستیغی و لاسو نیز مانند رگرسیون خطی با فراخوانی تابع fit()
انجام میشود.
مدل های طبقه بندی
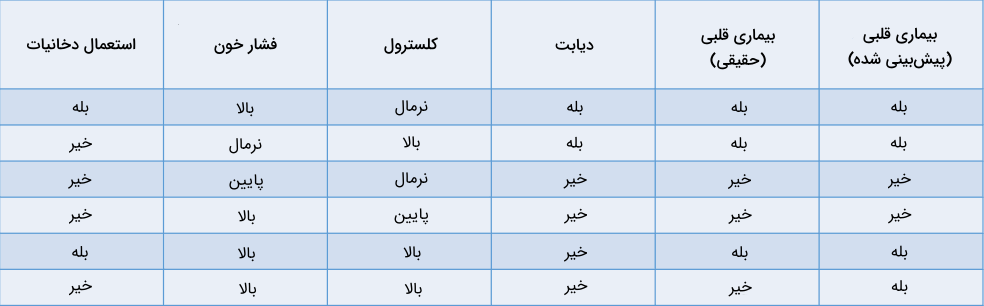
از انواع مدل های یادگیری ماشین طبقهبندی برای پیشبینی مقادیر گسسته از متغیرهای مستقل استفاده میکنیم. در اینجا متغیر وابسته همیشه یک «کلاس» یا «دسته» است. به عنوان مثال، پیشبینی احتمال مبتلا شدن افراد به بیماری قلبی بر اساس عوامل پرخطر، نوعی مسئله طبقهبندی است:
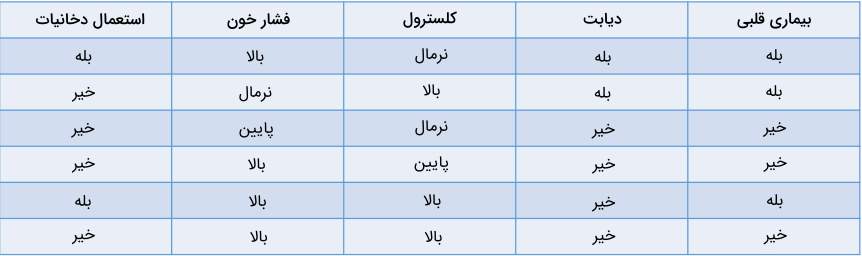
جدول بالا نشاندهنده یک مسئله طبقهبندی با چهار متغیر مستقل و یک متغیر وابسته یا همان احتمال ابتلا به بیماری قلبی است. از آنجا که تنها دو مقدار «بله» یا «خیر» برای خروجی قابل پیشبینی است، چنین مسئلهای را طبقهبندی «دودویی» یا «باینری» مینامند. تشخیص اسپم یا عادی بودن ایمیلها، احتمال ریزش مشتری و تصمیمگیری برای اهدای وام، همه از جمله مثالهای طبقهبندی دودویی هستند. از طرف دیگر، مسائل طبقهبندی «چندکلاسه» از بیش از دو خروجی محتمل تشکیل شدهاند. برای مثال میتوان به مسائلی همچون پیشبینی آبوهوا یا تشخیص گونههای جانوری اشاره کرد.
معیار های طبقه بندی
راه و روشهای بسیاری برای ارزیابی یک مدل طبقهبندی وجود دارد. در حالی که دقت یا Accuracy بیشترین استفاده را در سنجش مدلهای یادگیری ماشین دارد، ممکن است همیشه بهترین و قابل اتکاترین گزینه نباشد. در ادامه قصد داریم تا مطابق با دیتاست زیر، برخی از روشهای ارزیابی را در الگوریتمهای طبقهبندی بررسی کنیم:
۱. دقت
معیار دقت را میتوان به عنوان نسبتی از پیشبینیهای درست مدل یادگیری ماشین تعریف کرد. فرمول محاسبه این معیار به شرح زیر است:
در مورد مثال ما، معیار دقت برابر با ۴۶ یا ۰/۶۷ خواهد بود. در مثال بالا:
- تعداد پیشبینیهای صحیح: Number of Correct Predictions
- تعداد مشاهده: Number of Observations
۲. صحت
از معیار «صحت» (Precision) برای سنجش کیفیت پیشبینیهای مثبت مدل استفاده و مانند زیر تعریف میشود:
دقت مدل برابر با ۲۴ یا ۰/۵ است.
۳. بازیابی
معیار «بازیابی» (Recall) را برای ارزیابی کیفیت پیشبینیهای منفی مدل بهکار میگیرند و نحوه محاسبه آن به شرح زیر است:
معیار بازیابی مساوی با ۲/۲ یا ۱ خواهد بود.
برای درک بهتر تفاوت دو معیار دقت و بازیابی، مثال نوعی بیماری را در نظر بگیرید که درصد کمی از افراد را درگیر میکند. یعنی تنها ۵ درصد از مراجعهکنندگان بیمارستان را افرادی مبتلا به این بیماری تشکیل میدهند. اگر مدلی طراحی کنیم که پیشبینی آن نشان دهد هیچکس درگیر این بیماری نیست، دقتی برابر با ۹۵ درصد خواهد داشت. علیرغم دقت بسیار بالا، میدانیم که مدل در کار خود موفق نبوده و نتوانسته بیماران را بهدرستی شناسایی کند. در چنین شرایطی است که معیارهای دیگر مانند صحت و بازیابی برای سنجش توانایی مدل در تشخیص افراد بیمار مورد استفاده قرار میگیرند.
مقدار به اصطلاح «قابل قبول» معیارهای صحت و بازیابی به نوع مسئله بستگی دارد. در مورد مسئله پیشبینی بیماری، مطلوب است همه بیماران شناسایی شوند. حتی اگر تعدادی را به اشتباه بیمار دستهبندی کنیم. در واقع مدل را بهگونهای طراحی میکنیم که بازیابی بیشتری نسبت به صحت داشته باشد. در مثالی دیگر، اگر بخواهیم مدلی طراحی کنیم که از ورود کاربران مشکوک به وبسایت فروشگاهی جلوگیری کند، بهتر است معیار صحت، بیشتر از بازیابی باشد. چرا که محدود کردن دسترسی کاربران عادی باعث افت فروش میشود.
اغلب از معیاری با عنوان «امتیاز F1» یا F1-score برای یافتن «میانگین همساز» (Harmonic Mean) دو شاخص صحت و بازیابی کمک میگیریم. به بیان سادهتر معیار F1-score با میانگین گرفتن از صحت و بازیابی، یک معیار واحد را نتیجه میدهد. همچنین «سطح زیر نمودار» یکی دیگر از معیارهای پرکاربرد برای سنجش عملکرد مدلهای طبقهبندی است. سطح زیر نمودار یک الگوریتم، توانایی آن در جداسازی کلاس مثبت از منفی را به نمایش میگذارد. پس از آشنایی با یکی از انواع مدل های یادگیری ماشین یعنی مدل های طبقهبندی، در ادامه این بخش به معرفی و بررسی نحوه کارکرد انواع مختلف این مدلها میپردازیم.
رگرسیون لجستیک
یک مدل ساده طبقهبندی که احتمال وقوع یک رخداد را پیشبینی میکند. مثال زیر را از یک مدل رگرسیون لجستیک در نظر بگیرید:

این نمودار تابع لجستیکی را نشان میدهد که ایمیلها را بر اساس میزان تکرار کلیدواژههای منفی در متن، به دو گروه «عادی» و «اسپم» تقسیم میکند. برخلاف رگرسیون خطی، در رگرسیون لجستیک مدل به شکل یک منحنی که شبیه به حرف S انگلیسی است ترسیم میشود. تابعی که لجستیک نام داشته و فرمول محاسبه آن به شرح زیر است:
در حالی که تابع خطی فاقد حد بالا و پایین است، دامنه تابع لجستیک از ۰ تا ۱ متغیر است. در واقع پیشبینی نهایی مدل در بازه ۰ تا ۱ قرار داشته و کلاسی که هر نمونه داده به آن تعلق دارد را مشخص میکند. اگر مجدد به مثال ایمیلهای اسپم برگردیم، ایمیلی که فاقد کلیدواژههای مشکوک باشد، احتمال اسپم بودن پایینی داشته که چیزی نزدیک به ۰ است. اما احتمال اسپم بودن ایمیلی که شامل تعداد زیادی کلیدواژه مشکوک است بالا و به ۱ نزدیک است. چنین احتمالی در انتها به یک خروجی طبقهبندی شده تبدیل میشود:

نقاط دادهای که با رنگ قرمز مشخص شدهاند به احتمال بیشتر از ۰/۵ درصد اسپم هستند. بنابراین به عنوان «اسپم» طبقهبندی شده و مدل رگرسیون لجستیک خروجی برابر با ۱ را برمیگرداند. نقاط داده با احتمال کمتر از ۰/۵ به رنگ سبز مشخص شده و پس از قرار گرفتن در کلاس «عادی»، خروجی برابر با ۰ حاصل میشود. برای مسائل طبقهبندی دودویی به این شکل، مقدار پیشفرض حدآستانه مساوی ۰/۵ خواهد بود. به این معنی که نقاط داده با احتمال بیش از ۰/۵، بهطور خودکار برچسبی برابر با ۱ دریافت میکنند. بسته به مسئله و دیتاستی که در اختیار دارید، مقدار این حدآستانه برای دستیابی به نتایج بهتر قابل تغییر است.
بهخاطر دارید که در رگرسیون خطی برای یافتن بهترین برازش، حاصل جمع مربع خطای بین مقادیر حقیقی و پیشبینی شده را کمینه میکردیم. در رگرسیون لجستیک اما، محاسبه ضرایب مدل با استفاده از تکنیکی تحت عنوان «تخمین حداکثر درستنمایی» انجام میشود.
K-نزدیک ترین همسایه
در روش «K-نزدیکترین همسایه» یا KNN، نقاط داده بر اساس گروهی که کمترین فاصله را با آن دارند طبقهبندی میشوند. نمودار زیر مثالی ساده از نحوه عملکرد الگوریتم KNN است:

در نمودار فوق دو کلاس با نامهای A و B مشخص شدهاند. مثلث مشکی بیانگر نمونه داده جدیدی است که باید در یکی از این دو کلاس قرار بگیرد. مراحل اجرای الگوریتم KNN را میتوان در ۴ قدم خلاصه کرد:
- قدم ۱: ابتدا مدل همه دادههای آموزشی را ذخیره میکند.
- قدم ۲: سپس فاصله میان داده جدید با همه نمونههای دیتاست محاسبه میشود.
- قدم ۳: مدل یادگیری، دیتاست را بر اساس فاصله نمونهها با داده جدید مرتب میکند.
- قدم ۴: بسته به مقدار متغیر ، داده جدید در کلاس نزدیکترین همسایه به خود قرار میگیرد.
در نمودار قبلی، متغیر مقداری برابر با ۱ دارد. یعنی در هر مرحله تنها به یکی از نزدیکترین نمونهها به مثلث مشکی (داده جدید) نگاه کرده و آن را در همان کلاس قرار میدهیم. از آنجا که مثلث مشکی به نقطه آبی رنگ نزدیکتر است، داده جدید را در کلاس B طبقهبندی میکنیم. اما حالا مقدار متغیر را به ۳ و ۷ تغییر میدهیم:

توجه کنید که پس از تغییر مقدار متغیر به ۳، نمونه داده جدید بین دو کلاس A و B قرار گرفته است. در این موقعیت، کلاسی انتخاب میشود که بیشترین تعداد نمونه نزدیک را داشته باشد. ۲ مورد از نزدیکترین همسایهها آبی و ۱ نمونه سبز است. بنابراین نمونه داده جدید به کلاس B تعلق میگیرد. اما پس از تغییر مقدار به عدد ۷ شرایط کمی متفاوت است. حالا از ۷ همسایه، ۲ نمونه آبی و ۵ نمونه دیگر به رنگ سبز هستند. در نتیجه اینبار نمونه جدید در کلاس A طبقهبندی میشود. تغییر مقدار در انتخاب کلاس نمونههای جدید تاثیر مستقیم دارد. اگر این مقدار بیش از حد کوچک باشد، شاید «نمونههای پرت» (Outliers) به عنوان پاسخ تشخیص داده شوند و در صورتی که از حدی فراتر رفته و بزرگتر باشد، امکان نادیده گرفتن کلاسهایی با جمعیت پایین وجود دارد.
ساخت مدل های یادگیری ماشین طبقه بندی در پایتون
در این بخش با بهرهگیری از زبان برنامهنویسی پایتون و کتابخانه Scikit-learn، نحوه پیادهسازی دو مدل رگرسیون لجستیک و KNN را بهطور مختصر شرح میدهیم.
۱. رگرسیون لجستیک
برای پیادهسازی رگرسیون لجستیک به کلاس LogisticRegression
نیاز داریم و در ادامه باید شیئی از این کلاس تعریف کنیم:
1from sklearn.linear_model import LogisticRegression
2
3
4log_reg = LogisticRegression()۲. KNN
کتابخانه Scikit-learn کلاسی با عنوان KNeighborsClassifier
برای پیادهسازی الگوریتم KNN در اختیار ما قرار میدهد. مشابه با سایر الگوریتمها، از این کلاس نیز متغیری با نام knn
میسازیم:
1from sklearn.neighbors import KNeighborsClassifier
2
3
4knn = KNeighborsClassifier()مدل های مبتنی بر درخت
مدلهای مبتنیبر درخت از دیگر انواع مدل های یادگیری ماشین نظارت شده هستند که برای پیشبینی از ساختاری «درختمانند» استفاده میکنند. الگوریتمهایی که هم در مسائل طبقهبندی و هم رگرسیون کاربرد دارند. در این بخش از مطلب مجله فرادرس، با دو مورد از رایجترین مدلهای مبتنیبر درخت یعنی «درخت تصمیم» و «جنگل تصادفی» آشنا میشویم. برای یادگیری بیشتر درباره الگوریتم درخت تصمیم میتوانید فیلم آموزش درخت تصمیم در یادگیری ماشین فرادرس را که لینک آن در ادامه آورده شده است مشاهده کنید:
درخت تصمیم
از درخت تصمیم به عنوان سادهترین نوع الگوریتمهای مبتنیبر درخت یاد میشود. با استفاده از این مدل، دیتاست را تا جایی بر اساس پارامترها (ویژگیها) تقسیم میکنیم که تصمیم نهایی حاصل شود. در تصویر زیر مثالی ساده را از نحوه کارکرد درخت تصمیم برای بررسی احتمال قبولی دانشآموزان ملاحظه میکنید:

درخت تصمیم تا جایی بر سر هر گره یا Node تقسیم میشود که دیگر امکان تقسیم بیشتر وجود نداشته و خروجی بهدست بیاید. در این مورد، اگر دانشآموز بهطور هفتگی مطالعه نداشته باشد «مردود» میشود. اگر هر هفته مطالعه داشته باشد اما تکالیفش را انجام ندهد، همچنان نمره قبولی کسب نمیکند. اما اگر مطالعه هفتگی داشته و تکالیفش را نیز به موقع انجام دهد «قبول» میشود. توجه کنید که در مثال فوق، اولین تقسیم درخت بر اساس متغیر «مطالعه هفتگی» انجام شده و در صورتی که پاسخ منفی باشد، فرایند تقسیم به پایان رسیده و دانشآموز مردود خواهد شد. در قدم اول، درخت تصمیم بر اساس معیاری به نام «آنتروپی»، یک متغیر را برای تقسیم انتخاب میکند. فرایند تقسیم تا زمانی ادامه مییابد که همه نمونههای داده در کلاس یکسانی قرار بگیرند.
روشهای بسیاری برای ساخت درخت تصمیم وجود دارند که در همه آنها باید ویژگیهایی برای تقسیم انتخاب شوند. این ساختار مبتنیبر معیاری با عنوان «بهره اطلاعاتی» (Information Gain) بنا شده است. بهترین درخت تصمیم، درختی است که بالاترین بهره اطلاعاتی را داشته باشد. برای کسب اطلاعات بیشتر درباره الگوریتم درخت تصمیم، مطالعه مطلب زیر را از مجله فرادرس به شما پیشنهاد میکنیم:
از جمله مزایای الگوریتم درخت تصمیم میتوان به قابلیت تفسیرپذیری بالا آن اشاره کرد. درک این الگوریتم چندان دشوار نبوده و به راحتی با دنبال کردن هر قدم و تقسیمهای انجام شده، متوجه چگونگی بهدست آمدن نتیجه نهایی میشویم. با این حال باید به میزان رشد درخت نیز دقت داشته باشیم. در غیر اینصورت امکان وقوع مشکل بیشبرازش وجود دارد. زیرا در این الگوریتم تقسیمها بر پایه یادگیری از مجموعه آموزشی انجام شده و ممکن است قادر به شناسایی نمونههای جدید نباشد. مشکلی که راهحل آن استفاده از یکی دیگر از انواع مدل های یادگیری ماشین به نام «جنگل تصادفی» است.
جنگل تصادفی
مدل جنگل تصادفی از جمله انواع مدل های یادگیری ماشین مبتنیبر درخت است که ما را در غلبهبر مشکلات حاصل از درخت تصمیم مانند بیشبرازش یاری میکند. در واقع هر جنگل تصادفی با ترکیب پیشبینیهای چند درخت تصمیم تشکیل شده و یک خروجی واحد را نتیجه میدهد. مراحل اجرای الگوریتم جنگل تصادفی در دو قدم خلاصه میشود:
- قدم ۱: ابتدا و بهطور تصادفی از سطرها و متغیرهای دیتاست نمونهبرداری شده و با مقادیر دیگری جایگزین میشوند. در ادامه و پس از ایجاد چند درخت تصمیم مختلف، هر کدام با بخشی از دادهها آموزش میبینند.
- قدم ۲: در مرحله بعد، پیشبینیهای بهدست آمده از هر از درخت تصمیم باهم ترکیب شده و یک خروجی واحد حاصل میشود. به عنوان مثال اگر ۳ درخت آموزش دیده باشند و ۲ درخت خروجی «بله» و ۱ درخت خروجی «خیر» را پیشبینی کند، خروجی نهایی الگوریتم جنگل تصادفی «بله» خواهد بود.
اگر از الگوریتم جنگل تصادفی در مسائل رگرسیونی استفاده شود، آن زمان، خروجی میانگینی از پیشبینی همه درختهای تصمیم است. در تصویر زیر شاهد نمونه سادهای از عملکرد الگوریتم جنگل تصادفی هستید:

همانطور که در تصویر مشاهده میکنید، دو درخت تصمیم اول و سوم خروجی «بله» و درخت دوم خروجی «خیر» را پیشبینی کرده است. با توجه به نوع مسئله که طبقهبندی است، کلاس اکثریت یعنی «بله» انتخاب میشود. از آنجا که در جنگل تصادفی نتایج چند درخت مجزا با یکدیگر ترکیب میشوند، دقت تشخیص نمونههای جدید بیشتر از الگوریتم درخت تصمیم است. علاوهبر آن، برخلاف الگوریتم درخت تصمیم که خروجی بسیار وابسته به تغییرات مجموعه آموزشی است، در جنگل تصادفی بارها از مجموعه آموزشی «نمونهگیری» شده و چنین مشکلی وجود ندارد.
ساخت مدل های یادگیری ماشین مبتنی بر درخت در پایتون
با اجرای قطعه کدهایی که در ادامه برای هر کدام از انواع مدل های یادگیری ماشین مبتنیبر درخت ارائه شده است، میتوانید نحوه پیادهسازی اولیه الگوریتمهای درخت تصمیم و جنگل تصادفی را یاد بگیرید.
۱. درخت تصمیم
برای پیادهسازی الگوریتم جنگل تصادفی، ابتدا دو کلاس DecisionTreeClassifier
و DecisionTreeRegressor
را بارگذاری و سپس شی حاصل از آنها را در دو متغیر با نامهای clf
و dt_reg
برای دو نوع مسئله طبقهبندی و رگرسیون ذخیره میکنیم:
1# classification
2from sklearn.tree import DecisionTreeClassifier
3
4
5clf = DecisionTreeClassifier()
6
7# regression
8from sklearn.tree import DecisionTreeRegressor
9
10
11dt_reg = DecisionTreeRegressor()۲. جنگل تصادفی
روند کلی برای جنگل تصادفی نیز مانند الگوریتم درخت تصمیم بوده و تنها تفاوت در کلاسهای بارگذاری شده است که در این مورد به ترتیب RandomForestClassifier
و RandomForestRegressor
برای مسائل طبقهبندی و رگرسیون نام دارند:
1# classification
2from sklearn.ensemble import RandomForestClassifier
3
4
5rf_clf = RandomForestClassifier()
6
7# regression
8from sklearn.ensemble import RandomForestRegressor
9
10
11rf_reg = RandomForestRegressor()مدل های خوشه بندی
تا اینجا برخی از رایجترین انواع مدل های یادگیری ماشین نظارت شده را برای حل مسائل طبقهبندی و رگرسیون بررسی کردیم. در این بخش به معرفی یکی از مورد استفادهترین الگوریتمهای یادگیری نظارت نشده تحت عنوان «خوشهبندی» میپردازیم. به زبان ساده، خوشهبندی یعنی ایجاد گروههایی از نمونههای مشابه که با سایر نمونههای خارج از گروه تفاوت دارند. از جمله کاربردهای این تکنیک میتوان به پیشنهاد فیلم به کاربرانی که سلیقه مشابهی دارند در یک پلتفرم پخش آنلاین، «تشخیص ناهنجاری» و بخشبندی مشتریها اشاره کرد. سادهترین و محبوبترین الگوریتم از گروه مدلهای خوشهبندی و بهطور کلی یادگیری نظارت نشده، الگوریتم خوشهبندی «K-میانگین» یا K-Means نام داشته که در ادامه بیشتر درباره آن توضیح میدهیم.
خوشه بندی K-Means
خوشهبندی K-Means نوعی تکنیک یادگیری نظارت نشده است که برای گروهبندی نمونه دادههای شبیه بهم از آن استفاده میشود. برای درک نحوه کارکرد الگوریتم K-Means نمودار زیر را در نظر بگیرید:

مراحل اجرای الگوریتم K-Means در ۴ قدم قابل شرح است:
- قدم ۱: نموداری که پیشتر ارائه شد، شامل نمونههایی بدون برچسب و گروه است. به همین منظور، ابتدا هر نمونه بهطور تصادفی در یک خوشه قرار میگیرد. سپس برای هر خوشه، یک «نقطه مرکزی» (Centroid) در نظر گرفته میشود. این نقاط مرکزی با علامت «+» در نمودار زیر مشخص شدهاند:

- قدم ۲: در این مرحله فاصله هر نمونه تا مرکز خوشه محاسبه شده و هر نقطه داده به نزدیکترین مرکز خوشه اختصاص مییابد:

- قدم ۳: سپس مرکز هر خوشه مجدد با دادههای جدید محاسبه شده و فرایند تخصیص نقاط داده به مراکز خوشه تکرار میشود.
- قدم ۴: این فرایند تا زمانی تکرار میشود که دیگر تغییری در گروهبندی نقاط داده رخ ندهد:

مشاهده میکنید که مثال فوق از ۳ خوشه با رنگهای قرمز، نارنجی و سبز تشکیل شده است. حرف در الگوریتم K-Means بیانگر تعداد خوشهها بوده و توسط ما مشخص میشود. روشهای متنوعی برای انتخاب مقدار وجود دارد که از جمله رایجترین آنها میتوان به «روش Elbow» اشاره کرد. در این تکنیک خطای خوشهبندی برای تعداد مختلفی از خوشهها بر روی نمودار رسم و «نقطه عطف» (Inflection Point) منحنی به عنوان متغیر انتخاب میشود.
ساخت مدل یادگیری ماشین خوشه بندی K-Means در پایتون
برای پیادهسازی الگوریتم خوشهبندی K-Means در زبان برنامهنویسی پایتون مانند نمونه عمل میکنیم:
1from sklearn.cluster import KMeans
2
3
4kmeans = KMeans(n_clusters=3, init='k-means++')پارامتر n_clusters
از کلاس KMeans
، تعداد خوشهها را مشخص کرده و بیانگر متغیر است.
حال که با مفاهیم پایه یادگیری ماشین و انواع مدلهای آن از قبیل رگرسیون، طبقهبندی، خوشهبندی و دیگر الگوریتمها آشنا شدید، میتوانید برای یادگیری جنبههای کاربردی و پیادهسازی این مدلها با استفاده از زبان برنامهنویسی پایتون، از فیلمهای آموزشی جامعی که در وبسایت فرادرس منتشر شده است بهره ببرید. این دورههای آموزشی عبارتاند از:
با پشت سر گذاشتن این دورهها، توانایی پیادهسازی انواع مدلها و دیگر تکنیکهای یادگیری ماشین را در پایتون کسب خواهید کرد. مهارتی که شما را برای ورود به پروژههای کاربردی در این حوزه پرطرفدار آماده میکند.
جمعبندی
تنها زمانی میتوان بیشترین استفاده را از یادگیری ماشین برد که آشنایی و درک کافی از انواع مدل های یادگیری ماشین و طریقه اعمال آنها بر مسائل مختلف بهدست آمده باشد. علاوهبر آن، همانطور که در این مطلب از مجله فرادرس خواندیم، نحوه ارزیابی مدلهای یادگیری ماشین نیز از اهمیت بالایی برخوردار است. کارایی هر مدل به دیتاست و نوع مسئله ما بستگی دارد. به عنوان یک فرد متخصص در علم داده، باید همزمان با این دو حوزه یعنی انواع مدل های یادگیری ماشین و روشهای ارزیابی آشنایی کامل داشته باشید.
source