از هوش مصنوعی و یادگیری ماشین به عنوان دو رکن اساسی محاسبات کامپیوتری یاد میشود. تکنولوژیهایی که قابلیت شناسایی الگوهای مختلفی را دارند و مطابق با دادههای موجود، خروجیهای تازهای را پیشبینی میکنند. یادگیری عمیق یا «دیپ لرنینگ» (Deep Learning) زیرشاخهای از یادگیری ماشین است که بر اساس «شبکههای عصبی مصنوعی» (Artificial Neural Networks | ANNs) تعریف میشود. برخلاف روشهای سنتی برنامهنویسی، در دیپ لرنینگ نیازی به ارائه صریح دستورالعملها نیست و کامپیوتر طی سلسلهمراتب آموزشی، با الگوهای پنهان میان دادهها آشنا میشود و بر اساس آموختههای بهدست آمده، خروجی مسائل جدید را پیشبینی میکند. در این مطلب از مجله فرادرس، یاد میگیریم دیپ لرنینگ چیست و معرفی سادهای از انواع و همچنین مفاهیم پایهای این حوزه ارائه میدهیم.
در این مطلب، ابتدا یاد میگیریم دیپ لرنینگ چیست و از سیر تکامل یادگیری ماشین تا یادگیری عمیق میگوییم. سپس با اهمیت، مفاهیم و نحوه کارکرد دیپ لرنینگ آشنا میشویم و بعد از مقایسه هوش مصنوعی با یادگیری عمیق، به توضیح موارد استفاده و انواع مدلهای دیپ لرنینگ میپردازیم. در انتهای این مطلب از مجله فرادرس، نگاهی به کاربردها، مفاهیم پایه، الگوریتمهای محبوب و فریمورکهای دیپ لرنینگ میاندازیم و به تعدادی از سوالات متداول در این حوزه پاسخ میدهیم.
دیپ لرنینگ چیست؟
یادگیری عمیق یا «دیپ لرنینگ» (Deep Learning) زیرشاخهای از یادگیری ماشین است که نحوه انجام کارهای مختلف را از طریق مثالهای آموزشی به کامپیوتر یاد میدهد. فرض کنید میخواهید به کامپیوتر یاد بدهید چگونه گربهها را تشخیص دهد. برای اینکار دو رویکرد قابل تصور است. یا با استفاده از روشهای کدنویسی قدیمی به کامپیوتر کمک میکنید تا بخشهای مختلف بدن گربه را مانند گوشها، چشمها و دُم شناسایی کند و یا با نشان دادن تصویر هزاران گربه، از آن میخواهید تا بدون راهنمایی قبلی، الگوهای مشترک را پیدا کرده و به شناسایی تصویر گربههای جدید بپردازد. رویکرد دوم، توصیف مختصری از دیپ لرنینگ است.

در میان واژگان فنی مرتبط با یادگیری عمیق، عبارتی وجود دارد با عنوان «شبکههای عصبی» (Neural Networks) که از مغز انسان الهام گرفته است. این شبکهها، شامل لایههایی از «گرههای» (Nodes) متصل بهم هستند که وظیفه پردازش اطلاعات را بر عهده دارند. هر چه تعداد لایهها بیشتر باشد، به اصطلاح میگوییم شبکه عمیقتر است و همراه با یادگیری ویژگیهای پیچیدهتر، میتواند کارهای دشوارتری نیز انجام دهد.
از ماشین لرنینگ تا دیپ لرنینگ
حالا که میدانیم دیپ لرنینگ چیست، در این بخش از سیر تحول و تکامل یادگیری ماشین به یادگیری عمیق میگوییم و دقیقتر با مفهوم هر کدام آشنا میشویم.
ماشین لرنینگ چیست؟
یادگیری ماشین یا «ماشین لرنینگ» (Machine Learning) زیرمجموعهای از هوش مصنوعی است که کامپیوترها را قادر میسازد بدون برنامهریزی و راهنمایی قبلی از دادهها یاد گرفته و تصمیمگیری کنند. یادگیری ماشین متشکل از تکنیکها و الگوریتمهای فراوانی است که به سیستمها اجازه میدهد با شناسایی و پیشبینی الگوها، عملکرد خود را بهبود بخشند.
تفاوت ماشین لرنینگ و دیپ لرنینگ چیست؟
در حالی که تا کنون، ماشین لرنینگ فناوری متحولکنندهای بوده است، دیپ لرنینگ فراتر رفته و بسیاری از فرایندهایی را که در سابق تنها با بهرهگیری از تخصص انسانی قابل انجام بودهاند، خودکارسازی کرده است. بهطور خلاصه، یادگیری عمیق یا دیپ لرنینگ زیرمجموعهای ویژه از یادگیری ماشین است که از طریق شبکههای عصبی چند لایه متمایز میشود. هر چند فاصله زیادی تا رسیدن به عملکرد برابر وجود دارد، وظیفه شبکههای عصبی، شبیهسازی رفتار مغز انسان در جهت یادگیری از حجم زیادی داده و اطلاعات است.

اهمیت مهندسی ویژگی
به فرایند انتخاب، تغییر یا ساخت مرتبطترین متغیرها یا همان «ویژگیها» (Features) از دادههای خام و سپس استفاده از آنها در مدلهای یادگیری ماشین، «مهندسی ویژگی» (Feature Engineering) گفته میشود. به عنوان مثال، دادههای خام مسئله پیشبینی آبوهوا، شامل ویژگیهایی همچون دما، رطوبت، سرعت باد و فشار هوا میشوند. در طی فرایند مهندسی ویژگی، تعیین میشود که کدام ویژگیها کاربرد بیشتری در پیشبینی آبوهوا داشته و مطابق با مسئله، نوع برخی از ویژگیها تغییر مییابد؛ مانند زمانی که واحد سنجش دما از فارنهایت به سلسیوس تغییر پیدا میکند. بهطور معمول در یادگیری ماشین سنتی، مهندسی ویژگی فرایندی است که توسط انسان انجام شده و علاوهبر زمانبر بودن، به دانش تخصصی بالایی نیاز دارد. در همین راستا، یکی از مزایای دیپ لرنینگ، یادگیری خودکار ویژگیهای مرتبط از دادههای خام و در نتیجه عدم نیاز به دخالت انسان است.
اهمیت دیپ لرنینگ در چیست؟
از جمله دلایلی که دیپ لرنینگ به استانداردی در صنایع مختلف تبدیل شده است، میتوان به موارد زیر اشاره کرد:
- مدیریت دادههای «غیر ساختیافته» (Unstructured Data): مدلهایی که با دادههای «ساختیافته» (Structured) آموزش دیدهاند، بهراحتی میتوانند از دادههای غیر ساختیافته نیز یاد بگیرند. مسئلهای که باعث کاهش زمان و منابع مورد نیاز برای استاندارسازی «مجموعهدادهها» (Datasets) میشود.
- مدیریت دادههای حجیم: معرفی واحد پردازش گرافیکی یا همان GPU، مدلهای یادگیری عمیق را قادر ساخته است تا حجم زیادی از دادهها را با سرعت بالا پردازش کنند.
- دقت بالا: بهرهگیری از مدلهای یادگیری عمیق، دقیقترین خروجیها را در زمینههایی مانند «بینایی ماشین» (Computer Vision)، «پردازش زبان طبیعی» (Natural Language Processing | NLP) و «پردازش صوت» (Audio Processing) نتیجه میدهد.
- «شناسایی الگو» (Pattern Recognition): در حالی که اغلب مدلها به دخالت مهندسهای یادگیری ماشین وابسته هستند، مدلهای یادگیری عمیق میتوانند هر نوع الگویی را بهطور خودکار شناسایی کنند.
تا اینجا یاد گرفتیم دیپ لرنینگ چیست و از اهمیت آن در موضوعات مختلف گفتیم. در ادامه، توضیح سادهای از مفاهیم اصلی و اولیهای که برای شروع کار خود در حوزه هوش مصنوعی نیاز دارید، ارائه میدهیم.
مفاهیم اصلی دیپ لرنینگ
پیش از آشنایی با پیچیدگیهای دیپ لرنینگ و بهطور کلی، کاربردهای یادگیری عمیق، ابتدا باید درک مناسبی از مفاهیم پایهای این فناوری بهدست آوریم. در ادامه پاسخ به پرسش دیپ لرنینگ چیست و در این بخش از مطلب، به معرفی اجزای سازندهای همچون شبکههای عصبی، «شبکههای عصبی عمیق» (Deep Neural Networks) و «توابع فعالسازی» (Activation Functions) در یادگیری عمیق میپردازیم.

شبکه های عصبی
مفهوم دیپ لرنینگ بدون شبکههای عصبی بیمعنی است. مدلهای محاسباتی که از مغز انسان الهام گرفتهاند. هر شبکه عصبی تشکیل شده است از گره یا «نورونهای» (Neurons) متصلی که بهمنظور اتخاذ تصمیمی نهایی با یکدیگر همکاری میکنند. همانطور که هر ناحیه از مغز ما به کاربرد متفاوتی اختصاص دارد، یک شبکه عصبی نیز شامل لایههایی است که برای هر کدام عمل مشخصی تعریف شده است. برای یادگیری بیشتر در مورد شبکههای عصبی، میتوانید فیلم آموزشی شبکههای عصبی مصنوعی فرادرس که لینک آن در ادامه آورده شده است را مشاهده کنید:
شبکه های عصبی عمیق
چیزی که باعث میشود یک شبکه عصبی را عمیق بنامیم، تعداد لایههایی است که بین لایه ورودی و خروجی قرار گرفتهاند. تعداد زیاد لایهها در «شبکههای عصبی عمیق» (Deep Neural Networks)، امکان یادگیری ویژگیهای پیچیده و پیشبینیهای دقیقتری را مهیا میسازد.
توابع فعال سازی
در شبکههای عصبی، «توابع فعالسازی» (Activation Functions) نقش تصمیمگیرنده را دارند. این توابع فعالسازی هستند که تعیین میکنند چه اطلاعاتی باید به لایه بعدی منتقل شود. توابعی که با معرفی سطحی از پیچیدگی، باعث میشوند شبکههای عصبی بتوانند از دادهها یاد گرفته و تصمیمات متفاوتی بگیرند.
چگونه دیپ لرنینگ را با فرادرس یاد بگیریم؟

در حال حاضر، دیپ لرنینگ یکی از پیشرفتهترین و پرکابردترین زیرمجموعههای یادگیری ماشین است. رویکردی که با الهام از شبکههای عصبی بیولوژیکی، میتواند الگوهای پیچیده میان دادهها را یاد بگیرد. نقطه آغاز در مسیری یادگیری دیپ لرنینگ، بهدست آوردن درکی اولیه از انواع دادهها، روشهای مختلف پردازش و پیشپردازش اطلاعات و سپس آشنایی با مفهوم یادگیری ماشین است. در قدم بعدی، لازم است تا آموختههای خود را به چالش کشیده و با بهرهگیری از ابزارهایی مانند زبان برنامهنویسی پایتون و کتابخانههای آن، به پیادهسازی الگوریتمهای یادگیری بپردازید. پس از کسب این پیشنیازها، زمان تسلط بر مفاهیم پایه دیپ لرنینگ مانند انواع لایهها، توابع فعالسازی و معماریهای رایج مانند شبکههای عصبی پیچشی و بازگشتی فرا میرسد.
همچنین گام بعدی، یاد گرفتن نحوه کار کردن با کتابخانهها و فریمورکهای محبوب دیپ لرنینگ مانند TensorFlow، Keras و PyTorch است. اگر شما نیز به این حوزه علاقهمند هستید و میخواهید از پایه تا سطح حرفهای دیپ لرنینگ را یاد بگیرید، فرادرس مجموعهای از فیلمهای آموزشی و کاربردی تهیه کرده است که میتوانید از طریق لینک زیر از آنها بهرهمند شوید:
یادگیری عمیق یا دیپ لرنینگ چگونه کار می کند؟
در یادگیری عمیق بهمنظور تشخیص ویژگیهای مشابه، ابتدا ویژگیها استخراج میشوند و سپس با استفاده از تابعی با عنوان «مرز تصمیم» (Decision Boundary)، ویژگیهای شاخص از یکدیگر جدا میشوند. مدلهای دیپ لرنینگ در مسئله طبقهبندی سگها و گربهها، اطلاعاتی مانند چشمها، صورت و فرم بدن حیوان را استخراج کرده و هر نمونه را در دو کلاس مجزا قرار میدهند. هر مدل یادگیری عمیق، متشکل از شبکههای عصبی است. همچنین یک شبکه عصبی ساده شامل یک «لایه ورودی» (Input Layer)، یک «لایه پنهان» (Hidden Layer) و یک «لایه خروجی» (Output Layer) است. تفاوت مدلهای یادگیری عمیق در تعداد لایههای مخفی بیشتری است که باعث ارتقا دقت مدل میشوند.

لایه ورودی دادههای خام را دریافت و سپس هر کدام را به اجزای تشکیل دهنده لایه پنهان بعدی یعنی گرهها منتقل میکند. وظیفه گرهها در هر لایه مخفی، طبقهبندی نقاط داده بر اساس اطلاعاتی است که تا آن لحظه بهدست آوردهاند. در آخر، لایه خروجی از اطلاعات حاصل از لایههای مخفی برای انتخاب محتملترین خروجی یا بهطور دقیقتر «برچسب» (Label) استفاده میکند. در مثال ما، برای هر تصویر دو برچسب سگ یا گربه قابل پیشبینی است.
هوش مصنوعی و دیپ لرنینگ
یکی از متداولترین پرسشهایی که در اینترنت مطرح میشود، این است که آیا دیپ لرنینگ همان «هوش مصنوعی» (Artificial Intelligence | AI) است یا با یکدیگر تفاوت دارند. پاسخ کوتاه مثبت است. بله، یادگیری عمیق یا دیپ لرنینگ زیرمجموعه یادگیری ماشین و یادگیری ماشین زیرمجموعهای از هوش مصنوعی است.

ایده هوش مصنوعی در ساخت ماشینهایی هوشمند که قادر به تقلید رفتار انسان یا پیشی گرفتن از سطح هوش انسانی باشند خلاصه میشود. هوش مصنوعی از رویکردهایی مانند یادگیری ماشین و دیپ لرنینگ برای انجام دادن فعالیتهای انسان کمک میگیرد. بهطور خلاصه، یادگیری عمیق، پیشرفتهترین الگوریتمی در هوش مصنوعی است که میتواند تصمیمات هوشمندانهای اتخاذ کند.
موارد استفاده دیپ لرنینگ چیست؟
به تازگی، جهان تکنولوژی شاهد موج عظیمی از کاربردهای حوزه هوش مصنوعی بوده است که همگی از مدلهای یادگیری عمیق یا همان دیپ لرنینگ سرچشمه میگیرند. گستره این کاربردها از «سیستمهای توصیهگر» (Recommender System) فیلم در پلتفرم «نتفلیکس» (Netflix) تا سیستمهای مدیریت انبار شرکت «آمازون» (Amazon) ادامه دارد. حالا و پس از پاسخ دادن به پرسش دیپ لرنینگ چیست، در این بخش با چند نمونه بسیار معروف از کاربردهای دیپ لرنینگ آشنا میشویم. به این صورت، درک خوبی از توانایی و پتانسیل شبکههای عصبی عمیق بهدست میآورید.
بینایی ماشین
از جمله کاربردهای «بینایی ماشین» (Computer Vision | CV)، میتوانیم به شناسایی موانع و جلوگیری از تصادف در اتومبیلهای خودران اشاره کنیم. همچنین در کاربردهای دیگری مانند «بازشناسی چهره» (Face Recognition)، «تخمین حالت» (Pose Estimation)، «طبقهبندی تصویر» (Image Classification) و «تشخیص ناهنجاری» (Anomaly Detection) نیز از بینایی ماشین استفاده میشود.
تشخیص گفتار خودکار
روزانه میلیاردها نفر از سیستمهای «تشخیص گفتار خودکار» (Automatic Speech Recognition | ASR) بهره میبرند. فناوری که در تلفنهای همراه ما تعبیه شده و بهطور معمول با بیان عباراتی همچون Hey, Google یا Hi, Siri فعال میشود. از چنین کاربردهایی در تبدیل «متن به صدا» (Text-to-Speech)، «دستهبندی صدا» (Audio Classification) و «تشخیص تغییرات کلامی» (Voice Activity Detection) استفاده میشود.
هوش مصنوعی مولد
معرفی مدل زبانی «جیپیتی» (GPT) توسط شرکت OpenAI، جهان «هوش مصنوعی مولد» (Generative AI) را متحول کرد. امروزه میتوانید چنین مدلهایی را برای نگارش کامل یک رمان یا حتی پیادهسازی پروژههای یادگیری ماشین خود آموزش دهید.

ترجمه
منظور از «ترجمه» (Translation) تنها ترجمه زبانی نیست و روشهایی مانند «بازشناسی کاراکترهای نوری» (Optical Character Recognition | OCR)، تصاویر را به متن تبدیل میکنند یا «شبکههای مولد تخاصمی» (Generative Adversarial Networks | GANs) متنی توصیفی به عنوان ورودی دریافت کرده و تصاویر متنوعی تحویل میدهند.
تحلیل سری زمانی
از «تحلیل سری زمانی» (Time Series Forecast) در پیشبینی نوسانات بازار، قیمت سهام و تغییرات آبوهوایی استفاده میشود. بقای بخش مالی هر سازمانی به تحلیل و پیشبینی طرحهای آینده بستگی دارد. مدلهای یادگیری عمیق و سری زمانی، در فرایندهایی مانند شناسایی الگو، مهارت بیشتری نسبت به انسان دارند و به همین خاطر، نقش ابزاری اساسی را در صنایع مختلف ایفا میکنند.
خودکارسازی
یکی از رایجترین کاربردهای دیپ لرنینگ، «خودکارسازی» (Automation) فعالیتها است. به عنوان مثال، از رباتهای آموزش دیده در کارخانهها و طی مراحل مختلف تولید بهرهبرداری میشود و برخی نرمافزارها نیز میتوانند بهطور خودکار، بازیها کامپیوتری را انجام دهند.
بازخورد مشتری
از دیپ لرنینگ در مدیریت بازخورد و شکایات مشتریها استفاده میشود. در تمامی «چتباتها» (Chatbots) بخشی برای ثبت بازخورد کاربران طراحی شده است.
زیست پزشکی
حوزه «زیستپزشکی» (Biomedical) رشد زیادی را از زمان معرفی دیپ لرنینگ تجربه کرده است. کمک در تشخیص سرطان، ساخت مواد دارویی پایدار و تشخیص ناهنجاری در تصاویر پزشکی تنها چند نمونه از موارد استفاده یادگیری عمیق در زیستپزشکی است.
انواع مدل های یادگیری عمیق
حالا که بهخوبی میدانیم دیپ لرنینگ چیست و چه موارد استفادهای دارد، در این بخش به توصیف انواع مدلهای یادگیری عمیق و نحوه کارکرد آنها میپردازیم.
یادگیری نظارت شده
در «یادگیری نظارت شده» (Supervised Learning) از دیتاستی «برچسبگذاری شده» (Labeled) برای آموزش مدلها، طبقهبندی دادهها و در نهایت پیشبینی مقادیر مختلف استفاده میشود. هر دیتاست شامل چندین ویژگی و کلاس هدف است که الگوریتم را قادر میسازند به مرور زمان از طریق کمینهسازی فاصله یا خطای میان نتایج پیشبینی شده و برچسبهای حقیقی یاد بگیرد. یادگیری نظارت شده را میتوان به دو دسته از مسائل «طبقهبندی» (Classification) و «رگرسیون» (Regression) تقسیم کرد.

طبقه بندی
الگوریتمهای «طبقهبندی» (Classification) بر اساس ویژگیهای استخراج شده، دیتاست را به گروههای مجزایی تقسیم میکنند. از جمله مدلهای محبوب یادگیری عمیق میتوان به ResNet50 برای دستهبندی تصاویر و مدل زبانی BERT برای «طبقهبندی متون» (Text Classification) اشاره کرد.

رگرسیون
بهجای تقسیم مجموعهداده به چند دسته یا گروه، مدلهای «رگرسیونی» (Regression) با یادگیری روابط میان متغیرهای ورودی و خروجی، نتایج را پیشبینی میکنند. استفاده از مدلهای رگرسیونی در مواردی همچون «تحلیل پیشگویانه» (Predictive Analysis)، پیشبینی آبوهوا و عملکرد بازار بسیار رواج دارد. به عنوان دو مدل رگرسیونی پر کاربرد در دیپ لرنینگ میتوان به «حافظه کوتاهمدت بلند» (Long Short-Term Memory | LSTM) و «شبکه عصبی بازگشتی» (Recurrent Neural Network | RNN) اشاره داشت.

یادگیری نظارت نشده
الگوریتمهای «یادگیری نظارت نشده» (Unsupervised Learning) الگوی میان دادههای یک دیتاستِ «بدون برچسب» (Unlabeled) را یاد گرفته و چندین گروه یا «خوشه» (Cluster) متفاوت ایجاد میکنند. مهم است توجه داشته باشید که یادگیری الگوهای پنهان، بدون دخالت انسان صورت گرفته و عمده کاربرد این قبیل از مدلهای یادگیری عمیق در «موتورهای توصیهگر» (Recommendation Engines) است. با استفاده از یادگیری نظارت نشده میتوان گونههای مختلف جانوری و تصاویر پزشکی را گروهبندی کرد. رایجترین مدل یادگیری عمیق برای «خوشهبندی» (Clustering)، الگوریتم «خوشهبندی تعبیه شده عمیق» (Deep Embedded Clustering) نام دارد.
کابرد های دیپ لرنینگ چیست؟
تا اینجا یاد گرفتیم دیپ لرنینگ چیست و از اهمیت و همچنین انواع مدلهای یادگیری عمیق گفتیم. در این بخش از مطلب مجله فرادرس، به بررسی تعدادی از مهمترین کاربردهای دیپ لرنینگ در جهان امروز میپردازیم.
یادگیری تقویتی
به روشی از یادگیری ماشین که در آن چند «عامل هوشمند» (Intelligent Agents) از طریق تعامل با محیط، رفتارهای مختلفی را یاد میگیرند، «یادگیری تقویتی» (Reinforcement Learning | RL) گفته میشود. هر عامل هوشمند با آزمون و خطا در محیطی پیچیده و بدون راهنمایی انسان، نحوه انجام دادن صحیح کارها را یاد گرفته و پاداش دریافت میکند. همانطور که کودکی با تشویق والدین خود یاد میگیرد چگونه راه برود، بیشینه کردن پاداش نیز به یادگیری هوش مصنوعی سرعت میبخشد. البته انتخاب میزان پاداش بر عهده شخص طراح و توسعهدهنده است. به تازگی و با توجه به پیشرفتهای حوزه رباتیک، اتومبیلهای خودران و علوم فضایی، یادگیری تقویتی و کاربرد آن در خودکارسازی بسیار مورد توجه قرار گرفته است.

شبکه های مولد تخاصمی
در «شبکههای مولد تخاصمی» (Generative Adversarial Networks | GANs) از دو شبکه عصبی استفاده میشود و این دو شبکه با کمک یکدیگر، نمونههای مصنوعی از دادههای اصلی تولید میکنند. در سالهای اخیر و بهدلیل تقلید از کار هنرمندان بزرگ، شبکههای مولد تخاصمی محبوبیت زیادی کسب کردهاند. بیشترین کاربرد GAN در تولید آثار هنری مصنوعی، ویدئو، موسیفی و متن است. برای آشنایی بیشتر با شبکههای GAN و نحوه پیادهسازی آن از طریق زبان برنامهنویسی پایتون، مشاهده فیلم آموزشی شبکههای GAN با پایتون فرادرس که لینک آن در بخش زیر آمده است را به شما پیشنهاد میکنیم:

در فهرست زیر به مراحل تولید تصاویر مصنوعی بهوسیله شبکههای مولد تخاصمی اشاره کردهایم:
- ابتدا مدل اول یعنی مدل «مولد» (Generator)، نوعی نویز تصادفی یا ورودی بیکیفیت را به عنوان ورودی دریافت کرده و چند تصویر جعلی میسازد.
- سپس تصاویر جعلی و حقیقی به عنوان ورودی مدل دوم یا همان مدل «متمایزگر» (Discriminator) قرار میگیرند.
- در نهایت، جعلی یا واقعی بودن تصاویر تولیدی بهوسیله مدل متمایزگر مشخص میشود. خروجی مدل متمایزگر مقداری احتمالاتی بین صفر و یک است که صفر، بیانگر جعلی بودن تصویر و مقدار یک، نشان میدهد که تصویر از نوع حقیقی تشخیص داده شده است.
معماری GAN شامل دو «حلقه بازخورد» (Feedback Loop) است. همزمان که مدل متمایزگر در حلقه بازخوردی با تصاویر حقیقی قرار دارد، مدل مولد نیز در حلقهای دیگر و در کنار مدل متمایزگر قرار میگیرد و همکاری میان این دو بخش، به تولید تصاویر معتبر بیشتری ختم میشود.
شبکه عصبی گراف
منظور از مفهوم «گراف» (Graph)، نوعی ساختمان داده متشکل از چند «یال» (Edges) و «رأس» (Vertices) است. بستگی به وجود یا عدم وجود وابستگی میان رئوس یا گرهها، یالها میتوانند جهتدار یا بدون جهت باشند. گرافی با یالهای جهتدار را «گراف جهتدار» (Directed Graph) مینامند. دایرههای سبز در تصویر زیر همان گرهها و خطوط میان گرهها همان یالها هستند:

در واقع، «شبکه عصبی گراف» (Graph Neural Network | GNN) نوعی معماری یادگیری عمیق است که تمامی عملیاتهای مورد نیاز را در بستر ساختمان داده گراف انجام میدهد. بیشترین کاربرد شبکههای عصبی گراف در تحلیل مجموعهدادههای بزرگ، سیستمهای توصیهگر و بینایی ماشین است.

از دیگر کاربردهای GNN میتوان به «طبقهبندی گره» (Node Classification)، «پیشبینی لینک» (Link Prediction) و خوشهبندی اشاره داشت. در برخی از مسائل مانند «شناسایی اشیاء» (Object Detection) و پیشبینی روابط «معنایی» (Semantic)، شبکههای عصبی گراف عملکرد بهتری نسبت به «شبکههای عصبی پیچشی» (Convolutional Neural Networks | CNNs) از خود نشان میدهند.
پردازش زبان طبیعی
در «پردازش زبان طبیعی» (Natural Language Processing | NLP)، از دیپ لرنینگ برای آموزش دادن زبان طبیعی انسان به کامپیوتر بهرهبرداری میشود. پردازش زبان طبیعی از یادگیری عمیق برای خواندن، درک و رمزگشایی از زبان انسان استفاده میکند. عمده کاربرد NLP در پردازش گفتار، متن و تصویر است. معرفی رویکرد «یادگیری انتقالی» (Transfer Learning) نقش بهسزایی در رشد NLP داشت و به پژوهشگران اجازه داد تا مدلهای آماده را با نمونه دادههای جدیدی آموزش داده و به نتایج قابل توجهی دست پیدا کنند. اگر به این حوزه علاقهمند هستید و قصد شروع یادگیری آن را با استفاده از زبان برنامهنویسی پایتون دارید، میتوانید فیلم آموزشی NLP در پایتون فرادرس که لینک آن در ادامه آورده شده است را مشاهده کنید:
حوزه NLP را میتوان به زمینههای زیر تقسیم کرد:
- «ترجمه» (Translation): شامل ترجمه زبانی، ترجمه ساختار مولکولی و ترجمه معادلات ریاضیاتی.
- «خلاصهسازی» (Summarization): خلاصهسازی قسمت بزرگی از متن به چند خط کوتاه، همزمان با حفظ ساختار و اطلاعات کلیدی.
- «طبقهبندی» (Classification): تقسیم متن به دستههای مختلف.
- «تولید» (Generation): تولید «متن به متن» (Text-to-Text) و قابل استفاده برای نگارش متون تخصصی با تنها دستوری تک خطی.
- «مکالمهای» (Conversational): نرمافزارهای «دستیار شخصی» (Virtual Assistant) که با حفظ دانش قبلی از مکالمات، به تقلید مهارت گفتوگو انسان میپردازند.
- «طرح پرسش» (Answering Questions): هوش مصنوعی از دادههای مربوط به بخش پرسش و پاسخ یا Q&A یاد گرفته و به سوالات پاسخ میدهد.
- «استخراج ویژگی» (Feature Extraction): شناسایی الگوهای متنی یا استخراج اطلاعات در روشهایی مانند «شناسایی موجودیتهای نامدار» (Named Entity Recognition) و کلماتی که تحت عنوان «اجزای کلام» (Parts of Speech) شناخته میشوند.
- «شباهت میان جملات» (Sentece Similarities): ارزیابی شباهت میان متون مختلف.
- «متن به گفتار» (Text-to-Speech): تبدیل متن به گفتاری قابل شنیدن.
- «تشخیص گفتار خودکار» (Automatic Speech Recognition): درک آواهای متنوع و تبدیل آنها به متن.
- «بازشناسی کاراکترهای نوری» (Optical Character Recognition): استخراج دادههای متنی از تصویر.
تا اینجا یاد گرفتیم دیپ لرنینگ چیست و با مهمترین کاربردهای یادگیری عمیق در زمینههای مختلف آشنا شدیم. در ادامه شرح دقیقتری از برخی مفاهیم پایهای در دیپ لرنینگ ارائه میدهیم.
نگاهی عمیق تر به مفاهیم دیپ لرنینگ
حالا که میدانیم دیپ لرنینگ چیست، بهتر است برای بهدست آوردن درک بهتر از دیپ لرنینگ و بهطور کلی نحوه کارکرد یادگیری عمیق، نگاهی دقیقتر به مفاهیم اولیه و اساسی دیپ لرنینگ بیندازیم.

توابع فعال سازی
همانطور که پیشتر نیز با این مفهوم آشنا شدیم، توابع فعالسازی در شبکههای عصبی، وظیفه تولید خروجی یا همان مرز تصمیم را بر عهده دارند و عملکرد نهایی مدل یادگیری ماشین را بهبود میبخشند. به بیان سادهتر، تابع فعالسازی نوعی عبارت ریاضیاتی است که مطابق با اهمیت ورودی، تصمیم میگیرد که آیا دادهها اجازه عبور از یک نورون را دارند یا خیر. همچنین، توابع فعالسازی شبکه عصبی را با مفهوم «غیرخطی بودن» (Non-Linearity) آشنا میکنند. توجه داشته باشید که بدون تابع فعالسازی، شبکه عصبی تفاوتی با یک «مدل رگرسیون خطی» (Linear Regression Model) ساده ندارد. در فهرست زیر به تعدادی از رایجترین توابع فعالسازی اشاره شده است:
- تابع «تانژانت هذلولوی» (Hyperbolic Tangent | Tanh)
- تابع «یکسوساز» (Rectified Linear Unit | ReLU)
- تابع «سیگموئید» (Sigmoid)
- تابع «خطی» (Linear)
- تابع «بیشینه هموار» (Softmax)
- تابع Swish

همانطور که در تصویر بالا ملاحظه میکنید، نتایج هر کدام از این توابع متفاوت است. وجود چند لایه مختلف و توابع فعالسازی، امکان حل مسائل پیچیده بسیاری را فراهم میکند. در مطلب زیر از مجله فرادرس، توضیح کاملتری از انواع توابع فعالسازی در شبکههای عصبی ارائه شده است:
توابع زیان
تعریف «تابع زیان» (Loss Function) برابر با تفاضل میان مقادیر حقیقی و پیشبینی شده است. شبکههای عصبی با بهرهگیری از توابع زیان، عملکرد مدل یادگیری ماشین را مورد ارزیابی قرار میدهند. انتخاب تابع زیان به نوع مسئله بستگی دارد و نحوه محاسبه تابع زیان بهصورت زیر است:
$$ Loss = sum_{i=1}^{n}(hat{y_i} – y_i)^2 $$
برخی از مورد استفادهترین توابع زیان در دیپ لرنینگ عبارتاند از:
- تابع «آنتروپی متقاطع دودویی» (Binary Cross Entropy)
- تابع «آنتروپی متقاطع دستهای» (Categorical Cross Entropy)
- تابع «میانگین مربعات خطا» (Mean Squared Error | MSE)
پس انتشار
در روش «انتشار روبهجلو» (Forward Propagation)، برای تولید خروجی تصادفی، شبکه عصبی خود را با ورودیهای تصادفی دیگری مقداردهی اولیه میکنیم. برای تضمین روند پیشرفت مدل، لازم است تا پارامترهای یادگیری مانند «وزنها» (Weights) را در طول فرایند آموزش بهروزرسانی کنیم؛ عملی که تحت عنوان روش «پس انتشار» (Backpropagation) انجام میشود. از طرف دیگر، دنبال کردن عملکرد مدل، نیازمند وجود تابع زیانی است که با پیدا کردن مقدار «کمینه سراسری» (Global Minima)، باعث بیشینه شدن دقت مدل شود.
گرادیان کاهشی تصادفی
بهمنظور بهینهسازی تابع زیان و تغییر پارامترهای وزنی به شکلی کنترل شده، از روش «گرادیان کاهشی» (Gradient Descent) استفاده میشود. پس از مشخص شدن هدف که همان رسیدن به مقدار کمینه سراسری است، باید مشخص کنیم که آیا میخواهیم پارامترهای وزنی افزایش داشته یا از مقدار آنها کاسته شود. در اینجا، «مشتقِ» (Derivative) تابع زیان، جهت حرکت بهروزرسانی وزنها را برای ما مشخص میکند.

معادله زیر، نحوه بهروزرسانی پارامترهای وزنی را با استفاده از گرادیان کاهشی نشان میدهد:
$$ W_{new} = W_{old} – frac{dJ}{dW} $$
نحوه کار «گرادیان کاهشی تصادفی» (Stochastic Gradient Descent) به این شکل است که دادهها به چند «دسته» (Batch) مختلف تقسیم شده و این دستهها بهجای کل مجموعهداده، برای بهینهسازی پارامترهای یادگیری مورد استفاده قرار میگیرند.
ابَرپارامترها
به پارامترهای قابل تنظیمی که پیش از اجرای فرایند آموزش مقداردهی میشوند، «ابَرپارامتر» (Hyperparameter) میگویند. پارامترهایی که تاثیر مستقیمی بر عملکرد مدل داشته و سرعت رسیدن به کمینه سراسری را افزایش میدهند. در فهرست زیر به چند مورد از رایجترین ابرپارامترها اشاره کردهایم:
- «نرخ یادگیری» (Learning Rate): طول هر بار تکرار از فرایند آموزش را گویند و بهطور معمول دامنهای بین ۰/۱ تا ۰/۰۰۰۱ دارد. در واقع نرخ یادگیری، مشخصکننده سرعت یادگیری مدل است.
- «اندازه دسته» (Batch Size): تعداد نمونههایی که در هر دور از اجرای الگوریتم یادگیری، وارد شبکه عصبی میشوند.
- «تعداد دوره» (Number of Epochs): واحدی تکراری که از آن برای شمارش تعداد دفعات تغییر پارامترهای وزنی مدل استفاده میشود. انتخاب تعداد دوره باید هدفمند و دقیق باشد؛ چرا که تعداد بیش از حد بالا به مشکل «بیشبرازش» (Overfit) و تعداد پایین به «کمبرازش» (Underfit) منجر میشود.
الگوریتم های محبوب دیپ لرنینگ چیست؟
دانستن این موضوع که دیپ لرنینگ چیست و چه کاربردهایی دارد، لازم اما کافی نیست. به همین خاطر، در این قسمت به شرح برخی از محبوبترین الگوریتمهای دیپ لرنینگ میپردازیم.
شبکه های عصبی پیچشی
به نوعی خاص از شبکههای عصبی که قابلیت پردازش آرایهای ساختیافته از دادهها را دارند، «شبکههای عصبی پیچشی» (Convolutional Neural Networks | CNNs) گفته میشود. عمده استفاده از شبکههای عصبی پیچشی در بینایی ماشین و بهطور ویژه کاربردهایی مانند طبقهبندی تصاویر است.
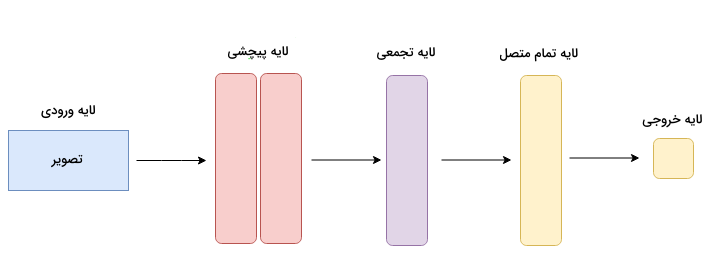
این شبکهها مهارت بالایی در شناسایی الگوها، خطوط و اشکال مختلف دارند. هر CNN شامل یک یا چند لایه «پیچشی» (Convolutional)، لایه «تجمعی» (Pooling) و لایه خروجی است که با عنوان لایه «تمام متصل» (Fully Connected) نیز شناخته میشود. بهطور معمول، مدلهای طبقهبندی تصویر شامل چند لایه پیچشی همراه با چند لایه تجمعی هستند و از آنجا که تعداد بیشتر لایه به درک عمیقتری از الگوهای میان دادهای منجر میشود، ممکن است همزمان با افزایش تعداد لایهها، دقت شبکه عصبی پیچشی نیز افزایش پیدا کند.
شبکه های عصبی بازگشتی
منظور از واژه بازگشتی در «شبکههای عصبی بازگشتی» (Recurrent Neural Networks | RNN)، حفظ خروجی هر لایه و سپس استفاده مجدد از آن به عنوان ورودی همان لایه است. قابلیت ذخیرهسازی و استفاده از اطلاعاتِ نمونههای قدیمی برای پیشبینی نمونههای جدید، شبکههای عصبی بازگشتی را قادر میسازد تا عملکرد بهتری در پردازش دادههای «ترتیبی» (Sequential) داشته باشند.
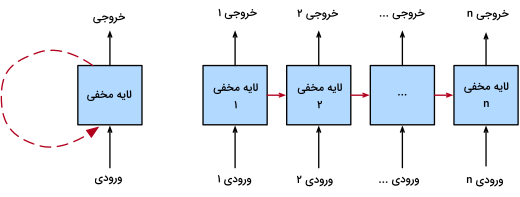
برخلاف شبکههای عصبی سنتی که خروجی مدل بر اساس مقدار ورودی فعلی محاسبه میشود، در RNN، بهازای ورودیهای گذشته نیز خروجی جدیدی بهدست میآید. همین ویژگی RNN، آن را به گزینه ایدهآلی برای پیشبینی واژه بعدی، قیمت سهام و تشخیص ناهنجاری تبدیل میکند.
شبکه های حافظه کوتاه مدت بلند
نوع پیشرفتهای از شبکههای عصبی بازگشتی که میتوانند اطلاعات قدیمیتری را ذخیره کنند. همچنین در شبکههای «حافظه کوتاهمدت بلند» (Long Short-Term Memory | LSTM)، برخلاف RNN ساده، مشکل «محوشدگی گرادیان» (Vanishing Gradient) دیده نمیشود.
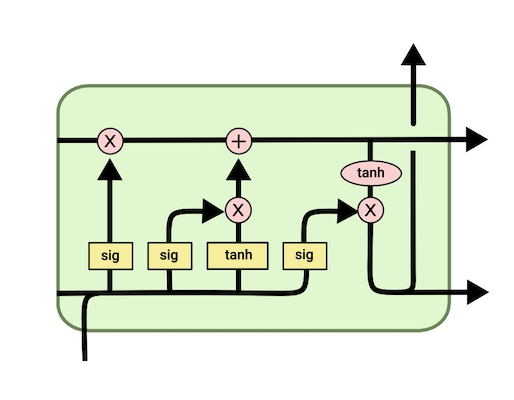
شبکههای RNN مرسوم، شامل چند شبکه عصبی سلسلهمراتبی با یک تابع فعالسازی تانژانت هذلولوی یا Tanh هستند؛ در حالی که در LSTM، دو تابع فعالسازی Tanh و سیگموئید همراه با چهار لایه تعاملی، وظیفه همکاری با یکدیگر و پردازش دنباله بزرگی از دادهها را بر عهده دارند. برای آشنایی بیشتر و بهدست آوردن درکی کامل از انواع الگوریتمهای یادگیری عمیق، مطالعه مطلب زیر را از مجله فرادرس به شما پیشنهاد میکنیم:
معرفی فریم ورک های یادگیری عمیق
فریمورکهای بسیاری در زمینه یادگیری عمیق وجود دارند که باعث آسانتر شدن فرایند طراحی و استفاده از مدلهای یادگیری ماشین شدهاند. حالا که بهخوبی میدانیم منظور از دیپ لرنینگ چیست، در ادامه چند مورد از محبوبترین فریمورکهای یادگیری عمیق را معرفی میکنیم.

TensorFlow
فریمورک TensorFlow یا به اختصار TF، کتابخانهای متنباز است که در طراحی کاربردهای مرتبط با دیپ لرنینگ مورد استفاده قرار میگیرد. این فریمورک دربرگیرنده تمامی ابزارهای مورد نیاز برای آزمایش و توسعه محصولات هوشمند است. همچنین TensorFlow از سه واحد پردازش مرکزی، گرافیکی و «تنسور» (Tensor) یا همان GPU، CPU و TPU برای آموزش دادن مدلهای پیچیده پشتیبانی میکند. در ابتدا، فریمورک TF توسط تیم هوش مصنوعی شرکت «گوگل» (Google) و برای استفاده داخلی توسعه داده شد و امروزه در دسترس عموم قرار دارد.
Keras
فریمورکی نوشته شده با زبان برنامهنویسی پایتون که با کتابخانههای متعددی مانند TensorFlow و Theano یکپارچگی دارد. فریمورک Keras، کتابخانهای متنباز است که بهمنظور انجام آزمایشات سریع و بهینه در زمینه یادگیری عمیق توسعه یافته است. همچنین مستندات ساده و قابل فهمی داشته و با اغلب پروژههای «علم داده» (Data Science) سازگاری دارد. مانند TensorFlow، فریمورک Keras نیز از GPU، CPU و TPU پشتیبانی میکند.
PyTorch
این ابزار یعنی PyTorch، محبوبترین و همچنین آسانترین فریمورک دیپ لرنینگ برای یادگیری است. در این فریمورک، بهجای آرایههای کتابخانه Numpy از نوع داده تنسور برای اجرای سریع محاسبات عددی در GPU استفاده میشود. بیشترین کاربرد این فریمورک در یادگیری عمیق و توسعه مدلهای یادگیری پیچیده است. بهدلیل انعطافپذیری و سادگی بیشتر، ترجیح اکثر پژوهشگران آکادمیک به استفاده از PyTorch است. کتابخانهای که با زبانهای برنامهنویسی ++C و پایتون نوشته شده و از شتابدهندههای GPU و TPU نیز پشتیبانی میکند.
سوالات متداول در رابطه با دیپ لرنینگ چیست؟
پس از آنکه یاد گرفتیم دیپ لرنینگ چیست و شرح به نسبت کاملی از انواع، کاربردها و همچنین فریمورکهای یادگیری عمیق ارائه دادیم، حال زمان خوبی است تا در این بخش از مطلب مجله فرادرس، به چند نمونه از پرسشهای متداول در این زمینه پاسخ دهیم.
مفهوم دیپ لرنینگ چیست؟
زیرمجموعهای از یادگیری ماشین که میتواند بهصورت خودکار یاد گرفته و با استفاده از الگوریتمهایی، کارایی خود را بهبود بخشد. الگوریتمهایی که یادگیری آنها بهوسیله شبکههای عصبی انجام گرفته و با تقلید از نحوه تفکر و یادگیری انسان پیشرفت میکنند.
موارد استفاده دیپ لرنینگ چیست؟
دیپ لرنینگ نقش مهمی در علم آمار و «مدلسازی پیشگویانه» (Predictive Modeling) دارد. با جمعآوری حجم عظیمی از داده و سپس تحلیل آن، یادگیری عمیق مدلهای متنوعی برای درک الگوهای میاندادهای ایجاد میکند.
آیا CNN نوعی دیپ لرنینگ است؟
شبکه عصبی پیچشی یا به اختصار CNN، روشی مورد استفاده در دیپ لرنینگ برای تجزیه و تحلیل دادههای بصری است.

شبکه های عصبی عمیق چگونه کار میکنند؟
هر شبکه عصبی عمیق، مانند مغز انسان که از نورونها ساخته شده است، از چند لایه با گرههای مختلف تشکیل میشود. نحوه کارکرد شبکههای عصبی عمیق نیز مانند مغز انسان بوده و اطلاعات گوناگونی میان گرهها رد و بدل میشود. هر چه تعداد لایهها بیشتر باشد، میگوییم شبکه عمیقتر است. در یک شبکه عصبی عمیق به هر سیگنال یا اطلاعاتی که از یک گره به گره دیگر منتقل میشود، وزنی اختصاص یافته و هر چه وزن گره بیشتر باشد، به همان اندازه تاثیر بیشتری بر گرههای لایه بعدی میگذارد. در انتها، خروجی شبکه، نتیجه همگرایی وزندار تمامی ورودیها تا آن مرحله خواهد بود.
تفاوت هوش مصنوعی و دیپ لرنینگ چیست؟
یادگیری ماشین و دیپ لرنینگ هر دو زیرشاخههای هوش مصنوعی هستند. دیپ لرنینگ زیرشاخه یادگیری ماشین و یادگیری ماشین زیرشاخه هوش مصنوعی است. یادگیری عمیق یا همان دیپ لرنینگ، برای تقلید فرایند یادگیری مغز انسان از شبکههای عصبی عمیق کمک میگیرد؛ رویکردی که باعث میشود، یادگیری ماشین بهطور خودکار و بدون دخالت انسان، با شرایط مسئله تطبیق پیدا کند.
جمعبندی
دیپ لرنینگ تازه در ابتدای مسیر قرار دارد و در دهههای آینده، پایهگذار تحولات به مراتب عظیمتری در جوامع خواهد بود. در این مطلب از مجله فرادرس، یاد گرفتیم دیپ لرنینگ چیست و از سیر تکامل تا معرفی فریمورکهای محبوب یادگیری عمیق باهم همراه بودیم. در کنار مزایای بسیاری که به برخی اشاره داشتیم، هزینه محاسباتی بالا و وابستگی بیش از حد به تعداد نمونه دادههای زیاد، از جمله مواردی است که باید هنگام بهرهگیری از دیپ لرنینگ به آن توجه داشته باشیم.
source