علم داده بهمنظور استخراج دانش و بینش مورد نیاز از دادهها، از حوزههایی همچون «تحلیل آماری» (Statistical Analysis)، «یادگیری ماشین» (Machine Learning) و «برنامهنویسی» (Programming) کمک میگیرد. شکل خام دادهها در جهان حقیقی با مشکلات زیادی مواجه است. از جمله این مشکلات میتوان به دادههای ناموجود یا همان کامل نبودن مجموعهدادهها اشاره کرد. فرایند «پیش پردازش داده ها» (Data Preprocessing) به تولید دادههای با کیفیت برای مدلهای یادگیری ماشین گفته میشود. پیچیدهترین جنبه علم داده که اولین مرحله ساخت یک مدل یادگیری ماشین نیز میباشد. پیش پردازش داده ها قدمی ضروری در الگوریتمهای یادگیری ماشین است؛ چرا که بدون آن، مدل یادگیری ماشین بسیار پیچیده خواهد بود و زمان زیادی صرف آموزش میشود. در واقع، یک مجموعهداده ناقص ارزشی نداشته و به همین خاطر است که باید با اجرای فرایند پیش پردازش، به اصلاح و پالایش دادهها بپردازیم. در این مطلب از مجله فرادرس، یاد میگیریم پیش پردازش داده ها چیست و با نحوه پیادهسازی مراحل مختلف آن در زبان برنامهنویسی پایتون آشنا میشویم.
در این مطلب، ابتدا یاد میگیریم پیش پردازش داده ها چیست و همچنین به چرایی استفاده از آن میپردازیم. سپس با بهرهگیری از یک مجموعهداده آموزشی و زبان برنامهنویسی پایتون، برخی از مراحل مهم پیش پردازش داده ها را پیادهسازی میکنیم. در انتهای این مطلب از مجله فرادرس، اصول و قواعده پیشنهادی را شرح داده و به چند مورد از پرسشهای متداول در این زمینه پاسخ میدهیم.
پیش پردازش داده ها چیست؟
منظور از پیش پردازش داده ها، تغییراتی است که پیش از اجرای مدل یادگیری ماشین بر روی دادهها اعمال میکنیم. به بیان دیگر، پیش پردازش داده ها تکنیکی است که دادههای خام را به شکل مرتب شده و تمیز تبدیل میکند. بهطور معمول، دادهها از منابع مختلفی جمعآوری میشوند که بدون پیش پردازش، امکان تحلیل و بررسی آنها وجود ندارد.

چرا به پیش پردازش داده ها نیاز داریم؟
پیش پردازش داده ها، مرحلهای مهم از الگوریتمهای یادگیری ماشین به شمار میآید. فرض کنید قرار است بر روی تکلیف یکی از دروس دانشگاهی خود کار کنید. اما استاد درس، بهطور شفاف موضوع و دادههای مورد نیاز آن تکلیف را برای شما مشخص نکرده است. در چنین شرایطی و از آنجا که دادههای مورد نیاز اولیه را در اختیار ندارید، انجام دادن تکلیف بسیار دشوار خواهد بود. همین موضوع در یادگیری ماشین نیز صدق میکند. در واقع، ممکن است الگوریتم یادگیری ماشین بدون اجرای مرحله پیش پردازش داده ها پیادهسازی شود. موقعیتی که نتیجه نهایی کار شما را تحت تاثیر قرار میدهد. علاوهبر آنکه باید از اجرای فرایند پیش پردازش داده ها اطمینان حاصل کنیم، حفظ کیفیت و دقت بالای دادهها نیز اهمیت و تاثیرگذاری زیادی دارد.
چگونه پیش پردازش داده ها را یاد بگیریم؟

قبل از انجام هر گونه پردازش و تحلیل دادهای، ابتدا باید به پیشپردازش دادهها بپردازیم. مرحلهای که دقت و کیفیت نتایج نهایی را تضمین میکند. قدم اول در یادگیری موثر پیشپردازش دادهها، آشنایی با انواع مختلف، منابع جمعآوری و نحوه ذخیرهسازی دادهها است. همچنین لازم است تا درک مناسبی از مفهوم کیفیت داده و چالشهای مرتبط با آن، مانند دادههای گمشده و نامعتبر بهدست آورید.
در مرحله بعد و پس از آشنایی با مفاهیم اولیه، باید روشهای پیشپردازش دادهها را فرا بگیرید. پاکسازی دادههای نامعتبر، جایگزینی دادههای گمشده، تشخیص و حذف دادههای پرت، از جمله این روشها هستند. توجه داشته باشید که زبانهای برنامهنویسی همچون پایتون و R، ابزارهایی هستند که برای اجرای روشهای پیشپردازش به آنها نیاز دارید. برای یادگیری تمامی موارد ذکر شده و تمرین مهارتهای خود، مشاهده فیلم های آموزشی فرادرس را به ترتیب زیر پیشنهاد میکنیم.
همچنین، اگر تمایل داشتید در مباحث عمیقتر شده و موضوعات پیشرفتهتری مانند انتخاب ویژگی و تقلیل ابعاد را نیز یاد بگیرید، فردارس فیلم های آموزشی جامعی در این زمینه دارد که میتوانید آنها را از طریق لینکهای زیر مشاهده کنید.
مراحل انجام پیش پردازش داده ها
پس از پاسخ دادن به پرسش پیش پردازش داده ها چیست و همچنین آشنایی با اهمیتی که در یادگیری ماشین دارد، در این بخش از مطلب، با استفاده از زبان برنامهنویسی پایتون و مجموعهداده مربوط به معدل ۷۶ دانشجو که در وبسایت Kaggle موجود است، به شرح ۴ قدم مهم از پیش پردازش داده ها میپردازیم. همچنین، از ملزومات پیشپردازش داده، آشنایی با مباحث آماری است. برای یادگیری بیشتر میتوانید فیلم آموزش مفاهیم آماری در داده کاوی و پیاده سازی آن در پایتون فرادرس را از لینک زیر مشاهده کنید.
- تقسیم مجموعهداده به دو بخش «آموزشی» (Training Set) و «آزمایشی» (Test Set).
- بررسی «دادههای گمشده» (Missing Values).
- بررسی «ویژگیها طبقهبندی شده» (Categorical Features)
- نرمالسازی مجموعهداده.

در ادامه، با نحوه پیادهسازی هر کدام از این ۴ مرحله با زبان برنامهنویسی پایتون آشنا میشویم.
تقسیم مجموعه داده
فرایند تقسیم مجموعهداده که با عنوان Train Test Split شناخته میشود، قدمی مهم و ضروری در یادگیری ماشین است. زیرا مدل یادگیری ماشین باید پیش از توسعه، نسبت به نمونه دادههای جدید مورد ارزیابی قرار گرفته و برای استفاده در کاربردهای حقیقی آماده شود. هدف این قسمت از پیش پردازش داده ها، تقسیم مجموعهداده به دو بخش آموزشی و آزمایشی است. دادههای آموزشی شامل نمونههایی برچسبگذاری شده هستند که در مرحله آموزش به مدل ارائه میشوند. از طرفی دیگر، مجموعه آزمایشی متشکل است از نمونه دادههایی که برای سنجش عملکرد مدل، پس از مرحله آموزش مورد استفاده قرار میگیرند.
پیش از انجام فرایند تقسیم، ابتدا با استفاده از دو تابع read_csv
و head
کتابخانه Pandas در زبان برنامهنویسی پایتون، مجموعهداده را بارگذاری کرده و پنج نمونه اول را مانند زیر به به نمایش میگذاریم:
1import pandas as pd
2
3df = pd.read_csv('gpa.csv')
4df.head()در تصویر زیر، خروجی اجرای قطعه کد بالا را مشاهده میکنید:

مطابق تصویر، مجموعهداده متشکل از ۸ ستون یا ویژگی است. ستون gpa یا همان معدل، کلاس هدف ما میباشد که باید آن را از سایر ستونها جدا کرده و در متغیری دیگر ذخیره کنیم:
1X = df.drop(['GPA'], axis=1)
2y = df['GPA']پس از اجرای قطعه کد بالا، دادههای ورودی در متغیر X
و کلاس هدف یا همان برچسبهایی که باید توسط مدل یاد گرفته و پیشبینی شوند، در متغیر y
قرار میگیرند. آسانترین راه برای تقسیم مجموعهداده، استفاده از کتابخانه scikit-learn و تابع train_test_split
میباشد:
1from sklearn.model_selection import train_test_split
2
3X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)به این ترتیب، متغیرهای X
و y
را به عنوان ورودی تابع train_test_split
قرار داده و مجموعهداده را به نسبت ۸۰ درصد برای مجموعه آموزشی و ۲۰ درصد برای مجموعه آزمایشی تقسیم میکنیم. در نهایت، دادههای ورودی در متغیرهای X_train
و X_test
و همچنین برچسبهای کلاسی در متغیرهای y_train
و y_test
ذخیره میشوند. متغیرهای X_train
و y_train
از مجموعه آموزشی و X_test
و y_test
از نمونه دادههای مجموعه آزمایشی تشکیل شدهاند.
بررسی داده های گمشده
عبارت «ورودی زباله، خروجی زباله» (Garbage in Garbage out | GIGO) در یادگیری ماشین شهرت دارد. اگر مجموعهداده شما پر از مقادیر «غیر عددی» (Not a Number | NaN) و به اصطلاح زباله یا Garbage باشد، خروجی مدل یادگیری ماشین نیز کیفیت چندانی نخواهد داشت. به همین خاطر، بررسی و برطرفسازی مشکل «دادههای گمشده» (Missing Values) از اهمیت بالایی برخوردار است. با استفاده از دو تابع isna
و سپس sum
، مجموعه کل دادههای گمشده هر ستون را بهدست میآوریم:
در تصویر زیر، نتیجه اجرای قطعه کد بالا را مشاهده میکنید:

با توجه به خروجی، در ۳ ستون Gender، School_AV و Age، به ترتیب ۲، ۴ و ۸ داده گمشده داریم. یک راه برای حل این مشکل، جایگذاری «میانگین» (Mean) هر ستون بهجای دادههای گمشده است. به عنوان مثال، میتوانیم دادههای گمشده ستون School_AV را با میانگین تمامی دانشجویان جایگزین کنیم. برای این منظور، از کلاس SimpleImputer
کتابخانه scikit-learn کمک میگیریم:
1import numpy as np
2from sklearn.impute import SimpleImputer
3
4imputer = SimpleImputer(fill_value=np.nan, strategy='mean')
5school_av = imputer.fit_transform(df['School_AV'].to_numpy().reshape(-1, 1))از این طریق، مقدار میانگین ستون School_AV، جایگزین دادههای گمشده میشود. همانطور که در قطعه کد بالا نیز ملاحظه میکنید، برای اینکار از تابع fit_transform
استفاده شده است. اما مقداری که در متغیر school_av
ذخیره میشود، از نوع آرایه کتابخانه Numpy است و باید مانند نمونه، ابتدا آن را به فرمت Dataframe تبدیل کرده و سپس به مجموعهداده اصلی اضافه کنیم:
1school_av_df = pd.DataFrame(school_av, columns=['School_AV'])
2df['School_AV'] = school_av_df
3print(df)خروجی قطعه کد نمونه، مانند زیر خواهد بود:

برای اثبات این موضوع، مانند قبل از دو تابع isna
و sum
کمک میگیریم:
حال باید تعداد دادههای گمشده ویژگی School_AV، به صفر رسیده باشد:

توجه داشته باشید که برای پارامتر strategy
کلاس SimpleImputer
، مقادیر دیگری مانند «میانه» (Median) و «نما» (Mode) نیز قابل استفاده است. اگر تعداد دادههای گمشده کم باشد یا جایگذاری این دست از نمونهها مورد قبول نباشد، میتوان از طریق تابع dropna
کتابخانه Pandas، سطرهایی که شامل دادههای گمشده هستند را از مجموعهداده حذف کرد:
به این صورت، دادههای گمشده متعلق به تمامی ستونها را حذف کرده و نتیجه را در متغیری دیگر با نام dropDf
ذخیره میکنیم. مجدد و برای مشاهده نتیجه، دو تابع isna
و sum
را بر روی مجموعهداده فراخوانی میکنیم:
مطابق انتظار، دیگر هیچ ستونی داده گمشده ندارد:

بررسی ویژگی های طبقه بندی شده
از آنجا که ورودی مدل یادگیری ماشین باید به شکل عددی باشد، ویژگیهای طبقهبندی شده قابل قبول نبوده و باید آنها را نیز به اعداد صحیح تبدیل کنیم. در فهرست زیر، به دو روش رایج برای انجام این کار اشاره شده است:
- «کدبندی برچسبی» (Label Encoding)
- «کدبندی وانهات» (One Hot Encoding)

کدبندی برچسبی
در این روش، مقادیر طبقهبندی شده به برچسبهای عددی تبدیل میشوند. ستون Gender یا همان جنسیت در مجموعهداده ما از دو مقدار Female و Male یا به اختصار F و M تشکیل شده است. برای اعمال «کدبندی برچسبی» (Label Encoding)، ابتدا شیای از کلاس LabelEncoder
تعریف کرده و سپس با استفاده از دو تابع fit
و transform
، آن را بر ویژگی طبقهبندی شده مدنظر، به ترتیب برازش و اعمال میکنیم:
1from sklearn.preprocessing import LabelEncoder
2
3l1 = LabelEncoder()
4l1.fit(df['Gender'])
5df.Gender = l1.transform(df.Gender)
6print(df)مطابق انتظار و همانطور که در خروجی مشخص است، دو مقدار F و M به مقادیر عددی متناظر ۰ و ۱ تبدیل شدهاند:

اما مشکل این روش از جایی شروع میشود که مدل یادگیری ماشین، طی یک مقایسه نادرست، به نوع ویژگی که مقدار عددی بیشتری دارد (M) اولویت بالاتری میدهد. با این حال، استفاده از کدبندی برچسبی به نوع مسئله بستگی داشته و کاربرد زیادی نیز دارد.
کدبندی وان هات
در روش «کدبندی وانهات» (One Hot Encoding) برای هر مقدار طبقهبندی شده، یک ستون مجزا در نظر گرفته میشود. سپس مقدار ستون مربوط به هر سطر برابر با ۱ و دیگر ستونها همه برابر با ۰ میشود. به عنوان مثال، در مجموعهداده ما دو ویژگی طبقهبندی شده با نامهای Spec و branch وجود دارد که به ترتیب بیانگر رشته و گرایش تحصیلی هستند. از دو طریق یعنی تابع get_dummies
و کلاس OneHotEncoder
، میتوانیم روش کدبندی وانهات را بر این قبیل از ویژگیها اعمال کنیم.
۱. تابع get_dummies
روشی رایج و از جمله توابع پیشفرض کتابخانه Pandas که مقادیر طبقهبندی شده موجود در فرمت Dataframe را به نوعی بردار وانهات تبدیل میکند:
1df = pd.get_dummies(data=df)
2print(df)خروجی قطعه کد بالا، مجموعهدادهای شامل مقادیر طبقهبندی شده است که با روش وانهات، کدبندی شدهاند:
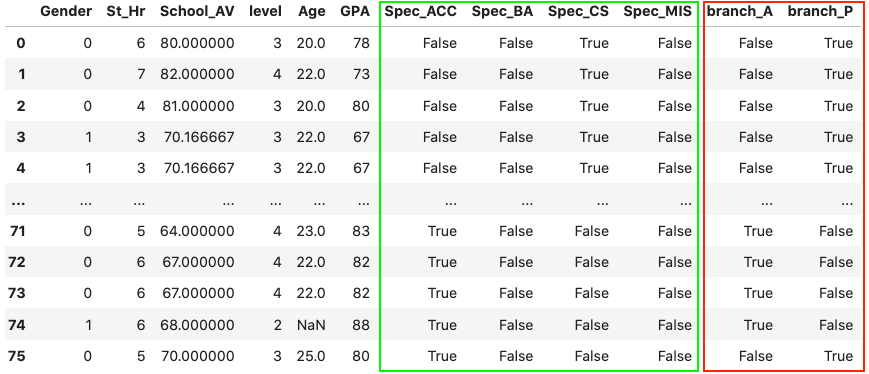
همانطور که در تصویر مشاهده میکنید، مقادیر منحصربهفرد ویژگی Specs در ۴ ستون (رنگ سبز) و همچنین ویژگی branch در ۲ ستون (رنگ قرمز) با همان نامها قرار گرفتهاند.
۲. کلاس OneHotEncoder
استفاده از کلاس OneHotEncoder
کتابخانه scikit-learn نیز بسیار متداول است. با این تفاوت که قابلیتهای بیشتری داشته و کار با آن کمی دشوارتر است. نحوه استفاده از کلاس OneHotEncoder
برای دو ستون Spec و branch مانند زیر است:
1from sklearn.preprocessing import OneHotEncoder
2
3ohe = OneHotEncoder(sparse_output=False)
4s1 = pd.DataFrame(ohe.fit_transform(df.iloc[:, [0, 4]]))
5df = pd.concat([df, s1], axis=1)
6print(df)در این روش، ابتدا شیای از کلاس OneHotEncoder
ایجاد کرده و سپس تابع fit_transform
را بر روی ستونهای مدنظر یعنی ستون اول و پنجم در مجموعهداده اعمال میکنیم. مقدار بازگشتی تابع fit_transform
، از نوع آرایه کتابخانه Numpy است و باید آن را از طریق کلاس DataFrame
به نوع داده Dataframe تبدیل کنیم. پس از تبدیل و برای متصل کردن ستونهای جدید به مجموعهداده اصلی، از تابع concat
کمک میگیریم. پارامتر axis=1
در تابع concat
، به این معنی است که میخواهیم عمل اتصال بر اساس ستونها انجام شود. در تصویر زیر، خروجی اجرای قطعه کد بالا را مشاهده میکنید:
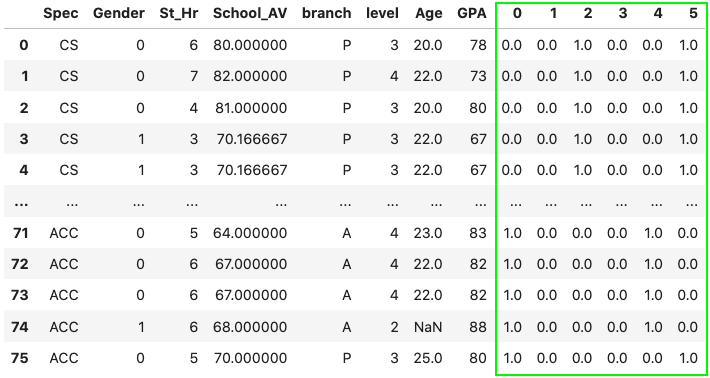
با وجود یکسان بودن نتایج حاصل از دو روش عنوان شده، خوانایی روش اول یا همان تابع get_dummies
کمی بهتر است. در مطالب قبلی مجله فرادرس نیز به طور کامل راجع به روش کدبندی وان هات صبحت کردهایم که لینک آن را میتوانید در ادامه مشاهده کنید.
نرمال سازی مجموعه داده
در ادامه پاسخ دادن به پرسش پیش پردازش داده ها چیست و پس بررسی سه مرحله تقسیم مجموعهداده، بررسی دادههای گمشده و بررسی ویژگیهای طبقهبندی شده، در این بخش با مفهوم نرمالسازی مجموعهداده آشنا میشویم. مطابق آزمایشات انجام شده، پژوهشگران به این نتیجه رسیدهاند که مدلهای یادگیری ماشین و «یادگیری عمیق» (Deep Learning)، عملکرد به مراتب بهتری با دادههای نرمالسازی شده از خود به نمایش میگذارند. هدف از نرمالسازی، تغییر مقادیر داده به مقیاسی رایج میان تمامی ویژگیها است. روشهای مختلفی برای انجام نرمالسازی وجود دارد که در این بخش به شرح دو مورد از متداولترین این روشها یعنی «مقیاس استاندارد» (Standard Scaler) و «نرمالسازی» (Normalization) میپردازیم.

مقیاس استاندارد
مراحل انجام روش «مقایس استاندارد» (Standard Scaler) را میتوان به سه بخش تقسیم کرد. در بخش اول، میانگین کل مجموعهداده محاسبه میشود:
$$ mu = frac{1}{N}sum_{i=1}^N(x_i) $$
سپس «انحراف معیار» (Standard Deviation) مجموعهداده را بهدست میآوریم:
$$ sigma = sqrt{frac{1}{N}sum_{i=1}^N(x_i – mu)^2} $$
در آخر برای آنکه تمامی نمونهها در محدوده صفر نمودار قرار بگیرند و همچنین «واریانس» (Variance) ویژگیها نیز برابر شود، ابتدا میانگین را از هر نمونه کم کرده و سپس نتیجه را بر انحراف میعار تقسیم میکنیم. از این مرحله با عنوان «استانداردسازی» (Standardization) نیز یاد میشود:
$$ z = frac{x – mu}{sigma} $$
با استفاده از این تکنیک، میانگین و انحراف معیار مجموعهداده به ترتیب برابر با ۰ و ۱ خواهد بود. مقایس استاندارد را میتوان با ترکیبی از توابع کتابخانه Numpy محاسبه کرد:
1z = (x.values - np.mean(x.values)) / np.std(x.values)در قطعه کد بالا، متغیر x
نشانگر مجموعهدادهای است که با فرمت Dataframe ذخیره شده است.
محسابه واریانس پیش از مقیاس استاندارد
از طریق فراخوانی تابع var
بر روی مجموعهداده، میتوان واریانس هر کدام از ویژگیها را محاسبه کرد. به عنوان مثال، با استفاده از قطعه کد زیر، مقدار واریانس برای دو ستون School_AV و GPA بهدست میآید:
1df.iloc[:, [3, 7]].var(ddof=0)در تصویر زیر، خروجی اجرای قطعه کد بالا را مشاهده میکنید:

مقدار پیشفرض پارامتر ورودی تابع var
یعنی ddof
، برای نوع داده Dataframe از کتابخانه Pandas برابر با ۰ و برای آرایههای کتابخانه Numpy برابر با ۱ میباشد. واژه Ddof مخفف عبارت (Delta Degrees of Freedom) و به معنی درجه آزادی دِلتا میباشد که در محاسبه انحراف معیار بهکار میرود. در واقع، مقسومعلیه انحراف معیار برابر است با $$ N – ddof $$، که $$ N $$ بیانگر تعداد کل نمونههای داده است. با قرار دادن مقدار ۰ برای پارامتر ddof
، تخمینی از نوع «بیشینه درستنمایی» (Maximum Likelihood)، برای متغیرهایی با توزیع نرمال بهدست میآید.
محاسبه واریانس پس از مقیاس استاندارد
از طریق کلاس StandardScaler
کتابخانه scikit-learn نیز میتوان مقدار واریانس را محاسبه کرد. برای اینکار، ابتدا باید شیای از روی کلاس StandardScaler
ساخته و سپس مقیاس استاندارد را بر ستونهای مورد نظر مجموعهداده اعمال کنیم:
1from sklearn.preprocessing import StandardScaler
2
3ss = StandardScaler()
4df.iloc[:, [3, 7]] = ss.fit_transform(df.iloc[:, [3, 7]])
5print(df)در تصویر زیر، نتیجه فراخوانی تابع fit_transform
را بر ویژگیهای School_AV (رنگ سبز) و GPA (رنگ قرمز) مشاهده میکنید:

برای محاسبه مجدد واریانس، مانند نمونه عمل میکنیم:
1df.iloc[:, [3, 7]].var(ddof=0)با توجه به خروجی، واریانس هر دو ستون School_AV و GPA با یکدیگر برابر شده و از مقادیر ۶۶ و ۴۳ به ۱ کاهش یافته است:

نرمال سازی
طبق تعریف، مجموعهدادهای «نرمالسازی» (Normalization) شده است که مجموعِ مربع تمام نمونههای آن برابر با ۱ باشد. از این روش، بهطور ویژه در کاربردهایی استفاده میشود که هدف، سنجش شباهت میان جفت نمونهها از طریق معیاری مانند «ضرب داخلی» (Dot Product) است. نحوه پیادهسازی نرمالسازی نیز بسیار راحت بوده و از طریق کلاس Normalizer
انجام میشود:
1from sklearn.preprocessing import Normalizer
2
3norm = Normalizer()
4df.iloc[:, [3, 7]] = norm.fit_transform(df.iloc[:, [3, 7]])
5print(df)خروجی دو ستون School_AV (رنگ سبز) و GPA (رنگ قرمز) مانند زیر خواهد بود:

نرمالسازی، یکی از مراحل مهم پیش پردازش داده ها است و انواع مختلفی نیز دارد که هر کدام، در کاربردهایی مشخص مورد استفاده قرار میگیرند.
اصول و قواعد پیشنهادی در پیش پردازش داده ها
همانطور که تا اینجا یاد گرفتیم، فرایند پیش پردازش داده ها شامل مراحل مختلفی میشود. با این حال، تجربه نشان داده است که برخی از این مراحل کارآمدی بیشتری دارند که در ادامه این مطلب از مجله فرادرس، به بررسی آنها میپردازیم.

پاکسازی داده
کاربرد فرایند «پاکسازی داده» (Data Cleaning)، در شناسایی دادههای گمشده و نویزی است. نمونههایی که باعث افت کیفیت مجموعهداده میشوند.
طبقه بندی داده
به این دلیل که الگوریتمهای یادگیری ماشین، تنها قادر به مدیریت دادههای عددی هستند، طبقهبندی دادهها از اهمیت بالایی برخوردار است. فرایندی که از وقوع بسیاری مشکلات در مراحل بعدی جلوگیری میکند.
کاهش بعد داده
در بسیاری از مواقع، اجرای سریع و کارآمد مدلهای یادگیری ماشین، با «کاهش بعد» (Data Reduction) و سادهسازی دادهها ممکن میشود. کاهش بعدی که مطابق اهداف مسئله و پیش پردازش داده ها باشد.
یکپارچه سازی
از جمله پیشنیازهای ضروری الگوریتمهای یادگیری ماشین موثر، میتوان به یکپارچهسازی مجموعهداده برای پیش پردازش داده ها اشاره کرد.
سوالات متداول پیرامون پیش پردازش داده ها
پس از آنکه یاد گرفتیم پیش پردازش داده ها چیست و با نحوه پیادهسازی آن در زبان برنامهنویسی پایتون آشنا شدیم، حال زمان خوبی است تا در این بخش از مطلب مجله فرادرس، به چند مورد از پرسشهای متداول در این زمینه پاسخ دهیم.
نقش پیش پردازش داده ها در یادگیری ماشین چیست؟
پیش پردازش داده ها، فرایندی است که دادههای خام را برای ارائه به مدلهای یادگیری ماشین آماده میکند.
اجرای چه مراحلی در پیش پردازش داده ها ضرورت دارد؟
از جمله مراحل لازم در پیش پردازش دادهها میتوان به موارد زیر اشاره کرد:
- جمعآوری داده.
- بررسی دادههای گمشده و نویزی.
- جایگذاری دادههای گمشده.
- مرتبسازی دادهها.
- توزیع دادهها در چند مجموعه مشخص.

از چه روش هایی به عنوان پیش پردازش داده در یادگیری ماشین استفاده می شود؟
در یادگیری ماشین، از کاهش بعد و «تبدیل داده» (Data Transformation)، به عنوان دو نمونه از روشهای متداول پیش پردازش استفاده میشود.
جمعبندی
پیش پردازش داده ها بخشی مهم از الگوریتمهای مورد استفاده در علم داده، بهویژه مدلهای یادگیری ماشین است. دادههای پردازش شده نسبت به خام، تاثیر بهسزایی بر دقت و عملکرد نهایی مدل میگذارند. همانطور که در این مطلب از مجله فرادرس خواندیم، پیش پردازش داده ها فرایندی است که مراحل متنوعی داشته و بر اساس نوع و هدف مسئله، میتوانیم هر کدام را به راحتی بر روی مجموعهداده خود پیادهسازی کنیم. تکنیکهایی که علاوهبر بالا بردن مهارت شما به عنوان یک دانشمند علم داده یا مهندس یادگیری ماشین، به ارتقاء عملکرد مدلهای یادگیری نیز کمک میکنند.
source