در دنیای امروز، دادهها به عنوان یکی از ارزشمندترین سرمایههای سازمانها و شرکتها محسوب میشوند و موفقیت و پیشرفت این مراکز تا حد زیادی وابسته به درک و تجزیه تحلیل این دارایی ارزشمند است. به منظور پیشی گرفتن از سایر رقبا در حیطه کسب و کار، باید با تحولات فناوری خود را تطبیق دهید و از جدیدترین روشها استفاده کنید تا از دادههای خود بیشترین بهره را ببرید. «داده کاوی» (Data Mining) یکی از شاخههای کاربردی میان رشتهای است که با کمک روشهای آن میتوانید از دادههای خام خود، اطلاعات ارزشمندی به دست آورید. در این مطلب قصد داریم به این پرسش پاسخ دهیم که داده کاوی چیست و شامل چه روشهایی میشود.


در ابتدای مطلب حاضر از مجله فرادرس به مفهوم داده کاوی، تاریخچه، مزایا و معایب آن میپردازیم و توضیح خواهیم داد این شاخه از علوم کامپیوتر چه مباحثی را شامل میشود و چه تفاوتی با «یادگیری ماشین» (Machine Learning) دارد. سپس، مراحل مختلف داده کاوی را شرح میدهیم و به انواع روشهای آن اشاره خواهیم کرد. در نهایت نیز به برخی از مهمترین کاربردهای دیتا ماینینگ در زندگی انسان میپردازیم.
داده کاوی چیست؟
زمانی که لغت «کاویدن» را میشنویم، ممکن است تصویری از افرادی را در ذهن خود تجسم کنیم که کلاه ایمنی بر سر دارند و چراغ قوهای به دست گرفتهاند و در زیر زمین دنبال منابع طبیعی میگردند. در پاسخ به پرسش داده کاوی چیست باید بگوییم چنین تصوری درباره داده تا حدی صادق است البته در داده کاوی، افرادی به دنبال یافتن داده در تونلهای زیرزمینی نیستند.
داده کاوی فرآیند تحلیل حجم عظیمی از داده و پایگاه داده است تا بتوان با استخراج (کاویدن) اطلاعات موجود در آنها، مسائل تعریف شده را حل کرد. این مسائل میتوانند پیشبینی مقادیری خاص، انجام وظایف تعریف شده یا پیدا کردن فرصتهای جدید باشد.

داده کاوی مشابه کاویدن معدنچیها در زیر زمین هستند. این افراد در تونلها به دنبال یافتن منابع ارزشمند طبیعی هستند. بهطور مشابه، در داده کاوی نیز به دنبال پیدا کردن یک سری اطلاعات ارزشمند از دادههای حجیم هستیم. به عبارتی، در پاسخ به پرسش هدف داده کاوی چیست میتوان گفت این حوزه در تلفیق با علم آمار به بررسی روابط بین دادهها و یافتن الگوهای میان آنها میپردازد و این کار را با استفاده از الگوریتم های یادگیری ماشین و الگوریتم های یادگیری عمیق پیادهسازی میکند.
تاریخچه داده کاوی
هزاران سال است که مردم مکانهای مختلف را به دنبال یافتن اسرار پنهان حفاری میکنند. همین ایده بستری برای ظهور شاخه داده کاوی در علوم کامپیوتر شد. به عبارتی، زمانی که دادهها همانند سایر منابع طبیعی به عنوان یکی از ارزشمندترین داراییهای سازمانها محسوب شدند، پژوهشهای جدی برای کاویدن آنها شکل گرفت.
پس از دهه ۱۹۵۰ که کامپیوترهای اولیه شکل گرفتند، مفاهیم پایگاه داده و ذخیرهسازی دادهها به عنوان موضوع مهمی در حوزه کامپیوتر مطرح شدند. در دهه ۱۹۷۰ برنامههایی برای مدیریت پایگاه داده رابطهای طراحی شدند و متخصصان کامپیوتر «سیستمهای خبره» (Expert Systems) سادهای را با چندین قاعده ارائه کردند که میتوانستند اطلاعاتی را از این پایگاه دادهها استخراج کنند.
در دهه ۱۹۸۰ استفاده از سیستمهای مدیریت پایگاه داده بیش از پیش گستردهتر شد و در این دوران سازمانها و شرکتها برای مشتریان خود، پایگاههای دادهای برای ذخیرهسازی حجم عظیمی از داده طراحی میکردند و با استفاده از زبان SQL میتوانستند اطلاعاتی را از این بانکهای اطلاعاتی استخراج کنند.

دهه ۱۹۹۰ دورانی بود که افراد به میزان اهمیت و ارزش اصلی دادهها پی برده بودند و از این دوران به بعد تمرکز سازمانها به سوی ذخیرهسازی دادهها در حجم بسیار زیاد سوق گرفت و میتوان گفت در این دهه برای نخستین بار اصطلاح داده کاوی با مفهوم امروزی شکل گرفت.
روال داده کاوی از جنبه پژوهشهای آماری و مفاهیم طراحی الگوریتم و شناسایی آماری الگوهای دادهها نیز از «قضیه بیز» (Bayes Theory) در دهه ۱۷۰۰ آغاز شد و به مباحث رگرسیون در دهه ۱۸۰۰ رسید. سپس با گسترش پژوهشها در حوزه یادگیری ماشین و «شبکه عصبی» (Neural Network)، الگوریتم ژنتیک (در دهه ۱۹۵۰)، «درخت تصمیم» (Decision Tree) (در دهه ۱۹۶۰) و الگوریتم «ماشین بردار پشتیبان» (Support Vector Machine | SVM) (در دهه ۱۹۹۰) برای حل مسائل داده کاوی ارائه شدند و تا به امروز این پژوهشها ادامه دارند.
مباحث اصلی داده کاوی چیست؟
برای پاسخ به پرسش داده کاوی چیست ، لازم است به مباحث اصلی این شاخه پژوهشی اشاره کنیم. میتوان گفت داده کاوی یک حیطه پژوهشی تلفیقی است که از سه حوزه آمار، «هوش مصنوعی» (Artificial Intelligence | AI) و یادگیری ماشین شکل گرفته است.
مباحث آمار در حوزه داده کاوی مفاهیم تئوری آن را شکل میدهند. تحلیل رگرسیون، واریانس و انحراف معیار، توزیعهای احتمالاتی، تحلیل خوشهها و فواصل اطمینان از مهمترین مفاهیم آماری در داده کاوی هستند که در تحلیل داده و ارتباط دادهها کاربرد دارند.

هوش مصنوعی از دیگر مباحث اصلی داده کاوی است که با کمک آن میتوان سیستمها و ابزارهای هوشمندی را طراحی کرد که همانند انسان به تحلیل مسائل مختلف و حل آنها میپردازند.
یادگیری ماشین نیز که بخش جدایی ناپذیر هوش مصنوعی است و بر پایه مفاهیم آماری و ریاضیات شکل گرفته است. با استفاده از الگوریتمهای یادگیری ماشین میتوان مدلهای هوشمندی طراحی کرد که اطلاعات ارزشمندی را از دادهها استخراج کنند و بر پایه آن اطلاعات، به حل مسائل بپردازند.
بسیاری از افراد در پاسخ به پرسش داده کاوی چیست به اشتباه این حوزه را با یادگیری ماشین اشتباه میگیرند و تفاوتی میان آنها قائل نمیشوند. باید گفت این دو حیطه با این که همپوشانی بسیاری دارند، اما اهداف مجزایی را در پیش میگیرند. در ادامه، برای روشن شدن تفاوت داده کاوی و یادگیری ماشین، به توضیح اهداف و کاربرد آنها میپردازیم.
تفاوت داده کاوی و یادگیری ماشین چیست؟
داده کاوی و ماشین لرنینگ به عنوان دو شاخه پژوهشی مهم در علوم کامپیوتر محسوب میشوند و توسط عموم گهگاه به اشتباه معادل یکدیگر به کار میروند. با این که از این دو حوزه برای پردازش دادهها استفاده میشود، هدف آنها متفاوت از یکدیگر است.
داده کاوی فرآیندی است که در پی آن به دنبال یافتن الگوهای پنهان موجود در دادهها هستیم. داده کاوی به ما کمک میکند تا به پرسشهایی پاسخ دهیم که حاصل از شناسایی الگوهای آماری دادهها هستند. به بیان دیگر، تا زمانی که الگوهای نهفته دادهها را شناسایی نکنیم، پرسشهای جدید و مهمی درباره دادهها در ذهن ما شکل نخواهند گرفت. بدین ترتیب، با کمک روشهای داده کاوی میتوان ویژگیها و اطلاعات مهمی از دادهها استخراج کرد که در مراتب بعدی تصمیمگیری پیرامون مسئله، در اختیار تحلیلگران و مدیران سازمان قرار میگیرند.
از طرف دیگر، یادگیری ماشین شامل روشهای مختلفی است که کامپیوتر با استفاده از آنها میتواند حل مسائل را مشابه انسان انجام دهد. با کمک الگوریتمهای یادگیری ماشین میتوان احتمالات وقوع رویدادها را بر اساس ویژگیها و الگوهای دادهها پیشبینی کرد. به عبارتی دیگر، یادگیری ماشین از داده کاوی برای رسیدن به هدف خود استفاده میکند. در بخش بعدی مطلب حاضر، به مراحل داده کاوی اشاره میکنیم و هر یک از این گامها را شرح خواهیم داد.
مراحل داده کاوی
در پاسخ به پرسش داده کاوی چیست میتوان به مراحل آن نیز اشاره کرد. فردی که علاقه دارد در این حیطه مشغول به کار شود، باید به شش مرحله از داده کاوی تسلط داشته باشد که در ادامه به این مراحل اشاره میکنیم:
- درک مسئله یا کسب و کار: در این گام باید مسئله را بهطور دقیق تعریف کنیم یا کسب و کار سازمان را کاملاً درک و اهداف نهایی پروژه را مشخص کنیم.
- درک دادهها: پس از درک کامل مسئله، باید نوع داده و نحوه تهیه آنها را مشخص کنیم. ممکن است نیاز باشد از چندین منبع مختلف دادههای مورد نیاز مسئله را گردآوری کنیم. بهعلاوه، باید زمان آمادهسازی دادهها را نیز مشخص کنیم.
- آمادهسازی دادهها: بعد از جمعآوری دادههای مورد نیاز مسئله، باید آنها در قالب مناسبی برای مدل هوش مصنوعی ذخیره کنیم. این مرحله از کار شامل «پاکسازی داده» (Data Cleaning) و نرمالسازی آنها نیز میشود. به مرحله آمادهسازی دادهها، مرحله پیش پردازش داده نیز میگویند.
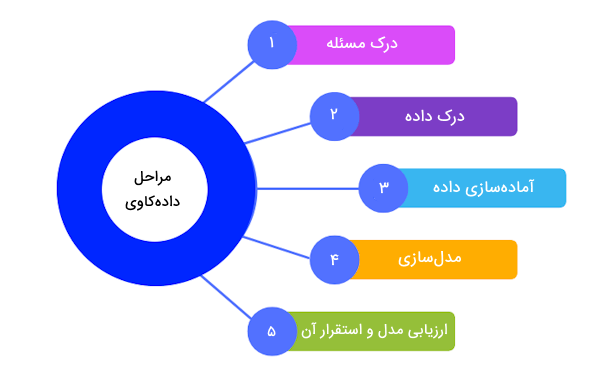
- مدلسازی مسئله: در این مرحله باید الگوریتم هوش مصنوعی مناسبی را برای حل مسئله انتخاب و آن را پیادهسازی کنیم. به منظور آموزش مدل نیز از دادههای جمعآوری شده در مرحله قبل استفاده میکنیم.
- ارزیابی مدل و ارائه مدل به کاربر نهایی: عملکرد مدل آموزش دیده را بر روی دادههای جدید تست کرده و نتایج حاصل شده از مدل را در این مرحله بررسی میکنیم و عملکرد مدل را میسنجینم که آیا هدف نهایی مسئله را محقق کرد است یا نیاز به اعمال تغییرات دارد. ممکن است نیاز شود الگوریتم انتخابی مسئله را تغییر دهیم یا نوع دادههای آموزشی مدل را عوض کنیم. پس از این که عملکرد مدل مورد قبول واقع شد و هدف نهایی مسئله محقق گردید، مدل نهایی را در اختیار کاربر قرار میدهیم که از آن برای تصمیمات خود استفاده کند.

مزایای داده کاوی
استفاده از روشهای داده کاوی در پیشبرد اهداف دارای مزیتهای مختلفی است که در ادامه به برخی از مهمترین آنها اشاره خواهیم کرد:
- سازمانها با استفاده از داده کاوی میتوانند اطلاعات ارزشمندی را از دادهها به دست آورند.
- روشهای داده کاوی به تصمیمگیری مدیران سازمان کمک بهسزایی میکنند که همین امر باعث پیشرفت در کسب و کار و میزان سوددهی سازمان میشود.
- با استفاده از روشهای داده کاوی میتوان فعالیتهای مشکوک و کلاهبرداریها را شناسایی کرد.
- افراد فعال در حوزه دیتا ساینس میتوانند با استفاده از روشهای داده کاوی، حجم زیادی از دادهها را در زمان کم تحلیل کنند.
معایب داده کاوی
داده کاوی همانند سایر شاخههای علوم دارای معایبی است که در ادامه به برخی از آنها میپردازیم:
- استفاده از ابزارهای تحلیل داده دشوار و پیچیده است و مهندس علم داده باید پیش از کار با ابزارهای داده کاوی، دانش تخصصی خود را در آن زمینه بالا ببرند.
- داده کاوی بر پایه الگوریتمهای یادگیری ماشین شکل گرفته است. این الگوریتمها بر پایه احتمالات کار میکنند. بنابراین، نمیتوان با اطمینان گفت خروجیهای مدل کاملاً صحیح هستند.
- این نگرانی وجود دارد که دادههای مشتریان در اختیار سایر کسب و کارها و سازمانها قرار بگیرد. بنابراین، مسئله امنیت داده در این حوزه نگرانکننده است.
- روشهای داده کاوی به حجم زیادی از داده احتیاج دارند که فراهم کردن آنها نیازمند هزینه مالی و زمانی است.
- معمولاً دادههای مورد نیاز روشهای داده کاوی بر روی پلتفرمهای مختلفی نظیر پایگاههای داده متفاوت، سیستمهای شخصی افراد و بستر اینترنت قرار دارند و جمعآوری و پیش پردازش آنها نیازمند ابزارهای مختلفی است که نیاز به یادگیری دارند.
پیش نیازهای داده کاوی
همانطور که در بخشهای پیشین مطلب حاضر از مجله فرادرس به پرسش داده کاوی چیست پاسخ دادیم، به این نکته پرداختیم که داده کاوی از سه شاخه اصلی آمار، هوش مصنوعی و یادگیری ماشین شکل گرفته است. افرادی که قصد دارند در حوزه داده کاوی قدم بگذارند، باید دانش تخصصی خود را در زمینههای مختلفی بالا ببرند که در ادامه به آنها اشاره شده است:
ابزارهایی نظیر RapidMiner و «آپاچی اسپارک» (Apache Spark) و SAS از جمله ابزارهای پرکاربردی هستند که در حوزه داده کاوی استفاده میشوند. زبان برنامه نویسی پایتون و زبان برنامه نویسی R به عنوان دو تا از زبانهای برنامه نویسی رایج در حوزه داده کاوی به شمار میروند. زبان پایتون دارای کتابخانههای وسیعی در حوزههای یادگیری ماشین و داده کاوی است و از این زبان میتوان بهراحتی برای توسعه پروژههای بزرگ با رویکرد شی گرایی بهره گرفت.
کاربردهای داده کاوی
با پیشرفتهتر شدن مطالعات در حوزه داده کاوی، از این شاخه در جنبههای مختلفی از زندگی انسان استفاده میشود که در ادامه به برخی از مهمترین آنها اشاره میکنیم:
- کاربرد دیتا ماینینگ در حوزه پزشکی
- استفاده از داده کاوی در حیطه مالی و بانکداری
- بهرهگیری از روشهای داده کاوی در حوزه آموزش
- کاربرد داده کاوی در بازاریابی و فروش
- تاثیر داده کاوی بر ارتباطات راه دور
- استفاده از روشهای داده کاوی در انجام پژوهشهای علمی
- تشخیص جرم با کمک داده کاوی
در ادامه این مطلب، به توضیحاتی پیرامون نحوه کاربرد داده کاوی در هر یک از حیطههای ذکر شده در فهرست بالا میپردازیم.
استفاده از دیتا ماینینگ در حوزه سلامت و پزشکی
حوزه سلامت و فعالیتهای پزشکی از جمله مهمترین حیطههایی هستند که با گسترش پژوهشهای شاخه کامپیوتر دستخوش تحولات مهم و موثری شدهاند. از داده کاوی به منظور بهبود و تسریع روشهای درمان و کاهش هزینههای مالی و زمانی آن استفاده میشود.
پزشکان از سیستمهای هوشمند مبتنی بر داده کاوی به منظور تحلیل دادههای پزشکی بیماران استفاده میکنند تا به طور دقیقتر درباره روند درمان آنها نظرات خود را اعلام کنند.

کاربرد داده کاوی در حوزه مالی و تشخیص کلاه برداری چیست؟
با دیجیتالی شدن دادهها، فعالیتهای حوزه مالی و بانکداری و روال پردازش دادههای آنها دستخوش تغییرات بزرگی شدهاند. روشهای داده کاوی میتوانند در تشخیص الگوهای دادهها، تحلیل ریسکهای بازار و سود و زبان مالی به مدیران کمک بهسزایی کنند. بهعلاوه، ابزارهای دیتا ماینینگ در روند تخصیص وامهای بانکی به مشتریان و بررسی فعالیتهای مالی آنها و همچنین تعیین کلاهبرداریهای مالی نقش مهمی را در صنعت بانکداری ایفا میکنند.

تشخیص دزدیها و کلاهبرداریهای مالی قدیمی زمانبر و پیچیده بود. با استفاده از تکنیکهای جدید داده کاوی میتوان با دقت بالا و در سریعترین زمان فعالیتهای مشکوک و غیر عادی کاربران را کنترل و از بروز چنین اتفاقاتی جلوگیری کرد.
داده کاوی و حوزه آموزش
در سالهای اخیر شاهد کاربرد داده کاوی در حوزه آموزش نیز هستیم. پیشبینی میزان پیشرفت و یادگیری دانشآموز، بررسی تاثیرات دستیار هوشمند آموزشی و بهبود روند یادگیری مفاهیم درسی توسط دانشآموز از مهمترین اهداف داده کاوی در حوزه آموزش است.

مراکز آموزشی میتوانند با بررسی شیوه عملکرد دانشآموز، سطح پیشرفت او را در دوران تحصیل پیشبینی کنند. با استفاده از چنین اطلاعاتی، دبیران مراکز آموزشی میتوانند درباره مفاهیم آموزشی و طریقه تدریس آن به دانشآموز تصمیمگیری کنند. به عبارتی، استفاده از اطلاعات مربوط عملکرد و سطح پیشرفت دانشآموزان در رویکردهای تدریس تاثیرات قابل توجهی خواهد داشت.
بازاریابی و داده کاوی
تحلیلات بازاریابی و مدیریت فروش محصولات میتوانند با استفاده از روشهای داده کاوی بهبود پیدا کنند. مدیران سازمانها و فروشگاهها با تحلیل خریدهای مشتریان خود میتوانند الگوی خرید آنها و سلایق و نیازشان را شناسایی کنند و بر اساس ویژگیهای هر مشتری، تبلیغات متناسبی را ارائه دهند تا در نهایت میزان سوددهی سازمان بیشتر شود.
صنعت ارتباطات از راه دور و دیتا ماینینگ
با ظهور اینترنت، رشد و توسعه پژوهشهای مربوط به صنعت ارتباطات از راه دور بهسرعت پیش رفتند و روشهای داده کاوی به این صنعت کمک کرد تا خدمات خود را با کیفیت بهتری ارائه دهد.
ارتباطات موبایل، رایانش موبایل و سرویسهای اطلاعاتی آنلاین بر پایه تحلیلهای الگوی پایگاههای داده کار میکنند. تشخیص دادههای پرت به منظور شناسایی کاربران جعلی در فضای اینترنت میتواند یکی از مهمترین کاربردهای داده کاوی در حوزه ارتباطات راه دور باشد.
کاربرد داده کاوی در مطالعات پژوهشی
انجام کارهای پژوهشی بر پایه تحلیل دادهها انجام میشوند. به عبارتی، تحقیقات علمی با بررسی ویژگیها و رفتار دادهها پیش میروند و میتوان گفت بدون وجود داده نمیتوان هیچ کار پژوهشی انجام داد.
محققان و پژوهشگران با استفاده از روشهای داده کاوی نظیر تمیز کردن داده و اعمال پیش پردازش بر روی دادهها و یکپارچهسازی آنها میتوانند به دادههای مناسبی برای پیشبرد تحقیقات علمی خود دست یابند.

بهعلاوه، روشهایی نظیر مصورسازی داده در دیتا ماینینگ میتواند اطلاعات جزئی و مهمی را در اختیار پژوهشگران قرار دهند و تصویر روشن و واضحی از روابط دادهها به مخاطب ارائه دهند.
تشخیص جرم با داده کاوی
روشهای داده کاوی در حیطه جرمشناسی نیز کاربر دارند. با استفاده از تکنینکهای دیتا ماینینگ متونی را که به عنوان گزارشات مهمی در جرمشناسی تلقی میشوند، به فایلهایی تبدیل میکنند که توسط الگوریتمهای داده کاوی قابل پردازش شوند. سپس، الگوهای پنهان این متون را استخراج میکنند و بر پایه آنها وقوع جرم را تشخیص میدهند.
روش های داده کاوی
امروزه، سازمانها بیش از پیش، داده در اختیار دارند که میتوانند از آنها در راستای افزایش منفعت و سوددهی کسب و کار خود استفاده کنند. اما برای تبدیل این دادههای خام به اطلاعات ارزشمند نیاز به روشهای مختلف داده کاوی داریم که در ادامه به فهرستی از این روشها اشاره شده است:
- تمیز کردن داده و آمادهسازی داده
- روش شناسایی «الگوهای ردیابی» (Tracking Patterns) دادهها
- روش «دستهبندی» (Classification) دادهها
- روش «یادگیری قواعد وابستگی» (Association Rule Learning)
- روش «خوشهبندی» (Clustering) دادهها
- تشخیص دادههای «پرت» (Outlier Detection)
- روش رگرسیون
- پیشبینی مقادیر
- الگوهای متوالی
- بصریسازی داده
- استفاده از شبکههای عصبی
- ذخیره دادهه در انبار داده
- روشهای یادگیری ماشین و هوش مصنوعی
در ادامه مطلب، به توضیح هر یک از روشهای داده کاوی خواهیم پرداخت.
تمیز کردن داده و آماده سازی داده
تمیز کردن داده و آمادهسازی آنها به عنوان یک مرحله مهم در فرآیند داده کاوی محسوب میشود. دادههای خام باید تمیز و نرمال شوند و در قالبی شکل بگیرند که مورد نیاز مدلهای داده کاوی است. آمادهسازی داده میتواند شامل مراحل مختلفی نظیر مدلسازی داده، تغییر شکل داده، «استخراج، تغییر، بارگذاری» (Extract, Transform, Load | ETL)، یکپارچهسازی داده و گردآوری داده باشد. در این مرحله، دانشمند داده شناخت اولیهای از ویژگیهای مهم داده به دست میآورد.
میتوان گفت آمادهسازی داده گام حیاتی برای کسب و کار محسوب میشود و بدون داده عملاً نمیتوان مراحل بعدی داده کاوی را پیش برد. موفقیت سازمانها تا حد زیادی در گرو دادههایی است که برای داده کاوی و تحلیل اطلاعات جمعآوری میشوند. بنابراین، این مرحله باید بهطور دقیق و با کمترین میزان خطا انجام شود.

شناسایی الگوهای ردیابی داده
تشخیص الگوهای ردیابی دادهها، یکی از روشهای اساسی و مهم در داده کاوی محسوب میشود. این روش شامل شناسایی و بررسی و کنترل الگوهای آماری موجود در داده است تا بتوان با تشخیص آنها به طور هوشمندانه درباره اهداف کسب و کار تصمیم گرفت.
به عنوان مثال، زمانی که سازمانی سیر دادههای فروش رو بررسی میکند، مشخص میشود که در چه بازه زمانی کدام محصول فروش بیشتری داشته است. بر اساس چنین اطلاعاتی سازمان میتواند خدمات یا محصولات مشابهی را ارائه دهد تا مشتریان بیشتری را به خود جذب کند.
روش دسته بندی داده در داده کاوی چیست؟
دستهبندی داده به عنوان یکی از مهمترین روشهای داده کاوی محسوب میشود و هدف از آن، دستهبندی دادهها در گروههای مختلفی است. سازمانها با بررسی دادههای خود، دستههای مختلفی را تعریف میکنند که هر یک از دادهها بر اساس ویژگیهای مشخص شده در این دستههای تعریف شده قرار میگیرند. سپس، با استفاده از روشهای دستهبندی داده کاوی، به طور خودکار دادههای جدید سازمان را در دستههای مشخص شده قرار میدهند.

از این روش میتوان برای سازماندهی دادهها در دستههای مشخص استفاده کرد. مسائلی نظیر تحلیل احساسات متون و عقیده کاوی و تشخیص ایمیل اسپم و غیر اسپم از جمله مسائل دستهبندی در داده کاوی هستند.
روش یادگیری قواعد وابستگی در داده کاوی چیست؟
یادگیری قواعد وابستگی یکی از روشهای داده کاوی است که بر پایه مفاهیم آماری تعریف میشود. هدف از این روش، شناسایی الگوهایی با قواعد شرطی «اگر – آنگاه» (If- Then) در بین متغیرهای مستقل است. روش یادگیری قواعد وابستگی مشابه مفهوم «همبستگی» (Correlation) در علم آمار است که رابطه بین دو رخداد را بررسی میکند.
میتوان برای درک این روش تشخیص وابستگی از مثالی در دنیای واقعی کمک گرفت. با بررسی تراکنشهای خرید افراد در فروشگاههای مختلف این نکته مشخص شده است فردی که از فروشگاه نان خریداری میکند، در لیست اقلام خرید او، کره نیز مشاهده میشود. به عبارتی، میتوان گفت احتمال خرید همزمان این دو جنس توسط مشتریان زیاد است. چنین الگوهایی، با روش یادگیری قواعد وابستگی به این صورت استخراج میشوند:
اگر نانی خریداری شود -> آنگاه کره نیز خریداری میشود.

با استخراج چنین اطلاعاتی از دادههای فروش فروشگاهها یا سازمانها میتوان به اطلاعات ارزشمندی دست پیدا کرد. به عنوان نمونه، در فروشگاهها اقلامی که مرتبط به هم هستند، در کنار هم چیده شدهاند تا مشتریان با خرید یکی از اجناس، به خرید جنس مرتبط با آن نیز اقدام کنند.
مفهوم خوشه بندی دادهها در داده کاوی چیست؟
خوشهبندی دادهها یکی از روشهای پرکاربرد داده کاوی تلقی میشود. با استفاده از این روش، دادهها بر اساس یک سری ویژگیهای مشابه، در خوشههای مجزا قرار میگیرند. دادههای درون خوشهها به هم شباهت بیشتری دارند و از دادههای سایر خوشهها بسیار متفاوت هستند. الگوریتمهای خوشهبندی داده کاوی، دادهها را به طور خودکار بر اساس میزان شباهتشان به یکدیگر در یک دسته قرار میدهند.
این روش گروهبندی دادهها، با روش دستهبندی داده متفاوت است. در روش دستهبندی، انواع و تعداد دستهها توسط تحلیلگران داده مشخص میشدند و برای آموزش الگوریتمهای دستهبند، یک سری داده آموزشی فراهم میکردند که نوع دسته دادهها مشخص بودند. اما در روش خوشهبندی، تحلیلگر داده، از قبل برای مدل نوع دسته دادهها را مشخص نمیکند و مدل با شناسایی الگوهای مشترک میان دادهها، آنها را در یک خوشه یکسان قرار میدهد. از روش خوشهبندی داده در مسائل مختلفی نظیر تحلیل وب، متن کاوی، محاسبات بیولوژیکی و تشخیص بیماریها استفاده میشود.
تشخیص داده های پرت در داده کاوی
با استفاده از روشهای تشخیص دادههای پرت یا Outlier، میتوان هرگونه داده بیربط و به اصطلاح ناهنجار را در مجموعه دادههای خود مشخص کرد. با تشخیص چنین دادههایی میتوان دلایل وجود این گونه دادهها را نیز معین و از تکرار وقوع آنها در آینده جلوگیری کرد.
از تشخیص دادههای پرت در مسائلی نظیر کلاهبرداریهای مالی به وفور استفاده میشود. در چنین مسائلی دادههایی که وقوع رخداد آنها غیرمعمول هستند و به ندرت اتفاق میافتند و ویژگیهایشان مشابه سایر دادههای بانک اطلاعاتی نیست، مشخص میشوند تا منبع و دلیل رویداد آنها معین گردد.
روش رگرسیون در داده کاوی
یکی دیگر از مسائلی که در حوزه داده کاوی مطرح میشود، مسئله رگرسیون است. در مسائل رگرسیون به دنبال پیدا کردن رابطه بین دو متغیر هستیم. به عبارتی، هدف از رگرسیون پیدا کردن تابعی است که بتواند رابطه میان دو متغیر را تشخیص دهد. به عنوان مثال، در رگرسیون خطی به دنبال یک تابع خطی (y = ax + b) هستیم که رابطه متغیرهای وابسته و مستقل را مشخص کند. از رگرسیون در حل مسائلی نظیر پیشبینی میزان دمای هوا یا قیمت مسکن بر اساس ویژگیهای مختلف مسئله استفاده میشود.
پیشبینی مقادیر در Data Mining
در پاسخ به پرسش داده کاوی چیست و به چه منظور از آن استفاده میشود، میتوان گفت یکی از کاربردهای مهم این شاخه از علوم کامپیوتر، پیشبینی رخدادهای آینده است. به عبارتی، در مسائل پیشبینی دیتا ماینینگ بر اساس دادههای موجود، وقوع یک سری رخدادها و رویدادهای آینده را پیشبینی میکنیم. چنین کاربردی به مدیران سازمانها کمک میکنند تا با دید وسیعتری درباره تصمیمات سازمان بیندیشند.
برای پیادهسازی مسائل پیشبینی داده کاوی میتوان از الگوریتمهای هوش مصنوعی جدید استفاده کرد. با این حال، چنانچه از الگوریتمهای سادهتر دیگری هم در این زمینه استفاده کنید، پاسخ قابل قبولی را خواهید گرفت.
بازشناسی الگوهای متوالی در Data Mining
از روشهای بازشناسی الگوهای متوالی داده کاوی برای کشف یک سری از رویدادهای متوالی استفاده میشود. در دنیای واقعی مسائلی وجود دارند که شامل یک سری رویدادهای وابسته به هم در یک توالی زمانی خاص اتفاق میافتند و هدف ما پیدا کردن الگوهای تکرار آن رویدادها است.
به عنوان مثال، روال خرید مشتریان یک فروشگاه را در نظر گرفتید. با بررسی اطلاعات خرید این مشتریان ممکن است به این نکته پی ببرید که مشتریان پس از خرید یک آیتم، با احتمال زیاد اجناس مرتبط دیگری را نیز خریداری میکنند. به عنوان نمونه، شخصی که از یک فروشگاه یک بارانی خریداری کرده، در پی آن تصمیم به خریدن لباسهای گرم یا کفشهای زمستانی نیز گرفته است.
مثال دیگر روشهای بازشناسی الگوهای متوالی را میتوان در حوزه پزشکی ملاحظه کرد. میتوان با کمک این روشها، میزان تاثیرات یک داروی خاص را بر روی بیماریهای دشوار نظیر سرطان در یک دوره زمانی خاص بررسی کرد. به طور کلی میتوان گفت از روشهای بازشناسی الگوی متوالی در پژوهشهایی نظیر مطالعات DNA، رخداد بلایای طبیعی، تغییران بورس و سهام، الگوهای خرید و فرآیندهای پزشکی میتوان استفاده کرد که در آنها احتمال رخداد رویدادها در یک بازه زمانی خاص سنجیده میشود.
بصری سازی داده در دیتا ماینینگ
بصریسازه داده از مباحث مهم داده کاوی به شمار میرود. با استفاده از روشهای بصریسازی میتوان دادهها را برای تحلیلگران داده و مدیران سازمان به نمایش درآورد تا بتوانند درباره مسئله با دید جزئیتری تصمیم بگیرند. امروزه، از ابزارهای گرافیکی مختلفی برای مصورسازی دادهها استفاده میشود که در مقایسه با روشهای گزارشدهی عددی قدیمی، جزئیات بهتری را در اختیار کاربران قرار میدهند.

شبکه عصبی در داده کاوی
شبکه عصبی و یادگیری عمیق شاخههای جزئیتری از ماشین لرنینگ و هوش مصنوعی محسوب میشوند. شبکههای عصبی ساختار پیچیدهتری نسبت به الگوریتمهای یادگیری ماشین دارند و درک و پیادهسازی آنها ممکن است سختتر و زمانبرتر باشد.
با این حساب، مدلهای شبکه عصبی در بسیاری از مسائل دقت بسیار بالایی را به دست میآورند و مدیران سازمان بر اساس نوع نیازشان تصمیم میگیرند از این مدلها در پیادهسازی مسائل سازمان بهره ببرند یا به روشهای یادگیری ماشین اکتفا کنند.
کاربرد انبار داده در دیتا ماینینگ
انبار داده و ذخیرهسازی دادهها در آن یکی از بخشهای مهم داده کاوی به شمار میرود. در گذشته، دادههای ساختاریافته سازمان در سیستمهای مدیریت پایگاه داده رابطهای ذخیره میشد و تحلیلگران داده از ابزارهای هوش تجاری برای تجزیه و تحلیل آنها و تهیه گزارش و ساخت داشبوردهای مختلف استفاده میکردند.
امروزه، تحلیلگران داده با مفاهیمی همچون انبار داده و ابزارهایی نظیر «هادوپ» (Hadoop) کار میکنند که این امکان را به کاربر میدهند تا پردازشهای بلادرنگ بر روی دادهها انجام دهند.
کاربرد روش های یادگیری ماشین و هوش مصنوعی در داده کاوی چیست؟
در مسائل پیچیده داده کاوی نظیر «بینایی ماشین» (Computer Vision)، پردازش تصویر، بازشناسی گفتار و «پردازش زبان طبیعی» (Natural Language Processing | NLP) از الگوریتمهای جدید هوش مصنوعی و یادگیری ماشین نظیر شبکههای عمیق استفاده میشوند.
این نوع الگوریتمها برای یادگیری به حجم زیادی داده احتیاج دارند و میتوانند مسائل را با دقت بسیار خوبی حل کنند. چنانچه با مسائلی روبهرو هستید که دادههای آنها از نوع نیمه ساختاریافته یا غیرساختاریافته هستند، روشهای یادگیری عمیق و شبکههای عصبی میتوانند به عنوان بهترین روشها برای مدلسازی باشند.
جمعبندی
داده کاوی یکی از شاخههای کاربردی میان رشتهای است که با کمک روشهای آن میتوانید از دادههای خام خود، اطلاعات ارزشمندی به دست آورید. البته برای وارد شدن به این حیطه باید دانش خود را در حوزه آمار و هوش مصنوعی و یادگیری ماشین بالا ببرید تا با کمک روشهای دیتا ماینینگ اطلاعات ارزشمندی را از دادهها استخراج کنید. در مطلب حاضر از مجله فرادرس، سعی کردیم به این پرسش پاسخ دهیم که مفهوم داده کاوی چیست و به علت پیدایش این شاخه از علوم کامپیوتر اشاره کردیم و کاربردها و مزایا و معایب آن را شرح دادیم. همچنین، به مراحل داده کاوی پرداختیم تا افرادی که قصد دارند وارد این حوزه شوند، یک شناخت کلی از آن به دست آورند.
source