11 اردیبهشت 1404 ساعت 12:06
شیائومی با معرفی مدل هوش مصنوعی MiMo به طور رسمی وارد عرصه رقابتی هوش مصنوعی شد. این اقدام، شیائومی را در کنار سایر غولهای فناوری دنیا قرار میدهد.
به نظر میرسد که هوش مصنوعی متنباز روزبهروز جذابتر میشود. شیائومی با معرفی رسمی MiMo، وارد این عرصه رقابتی شده است. این صرفاً یک مدل زبانی بزرگ دیگر نیست، بلکه هدف شیائومی بهطور خاص ارتقای قابلیتهای استدلال با این مدل است.
هوش مصنوعی MiMo شیائومی معرفی شد
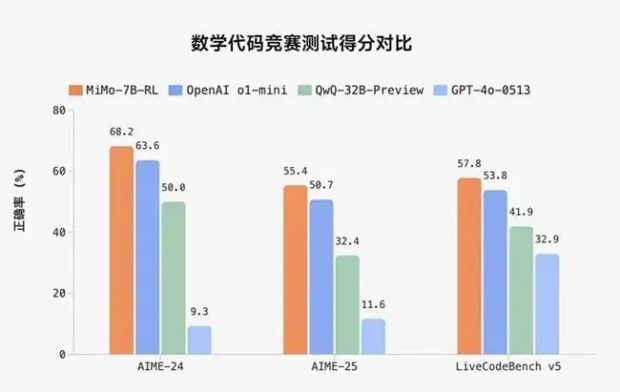
به گفته شیائومی، MiMo یک مدل هوش مصنوعی با 7 میلیارد پارامتر است. این عدد در مقایسه با برخی غولهای موجود، چندان عظیم به نظر نمیرسد. اما شیائومی مدعی است که میمو در زمینه استدلال ریاضی و تولید کد، عملکردی فراتر از انتظارات نشان میدهد. این شرکت میگوید که MiMo در سطحی همتراز با مدلهای به مراتب بزرگتر عمل میکند و حتی قادر به رقابت با مدلهایی مانند o1-mini متعلق به OpenAI و Qwen با 32 میلیارد پارامتر متعلق به علیبابا است.

دستیابی به چنین قابلیت استدلالی از یک مدل کوچکتر، کار آسانی نیست و شیائومی نیز به این امر واقف است. شیائومی درباره رمز موفقیت این مدل میگوید که این امر ناشی از به حداکثر رساندن ظرفیتهای نهفته در همان مدل پایه 7B است که شامل اتخاذ راهبردهای بسیار سنجیده در هر دو مرحله پیشآموزش و پسآموزش میشود. و یک مزیت بالقوه آن اندازه نسبتاً کوچک مدل است که برای کسبوکارهایی که خوشههای GPU عظیم ندارند، بسیار مناسب خواهد بود.
به نظر میرسد که بنیان کار MiMo، استفاده از یک فرایند پیشآموزش بهشدت بهینهسازیشده است. شیائومی میگوید که آنها به طور جدی بر مدیریت دادههای خود متمرکز شدهاند که این کار شامل بهبود روش پردازش دادههای خام، ارتقاء ابزارهای مورد استفاده برای استخراج متون مرتبط و به کارگیری لایههای فیلترینگ گوناگون میشود. بنابراین، آنها صرفاً دادهها را به سیستم تزریق نمیکنند، بلکه با دقت بسیار زیادی آنها را انتخاب میکنند.
آنها یک مجموعه داده تخصصی را گردآوری کردند که تقریباً شامل 200 میلیارد توکن استدلال بود. در ادامه، آنها یک راهبرد ترکیبی سه مرحلهای داده را به کار بستند و مدل را به تدریج در سه فاز و روی مجموعاً 25 تریلیون توکن آموزش دادند. آنها همچنین از یک تکنیک به نام Multiple-Token Prediction استفاده کردند که نه تنها عملکرد مدل را بهبود بخشیده، بلکه به آن کمک کرده تا پاسخها را با سرعت بیشتری تولید کند.
پس از ایجاد ساختار اولیه، آنها با استفاده از یادگیری تقویتی (RL) به تنظیم دقیق آن پرداختند. این فرآیند شامل تغذیه مدل MiMo با حدود 130,000 مسئله ریاضی و برنامهنویسی بود. نکته حائز اهمیت اینکه این مسائل از نظر صحت و میزان دشواری با استفاده از سیستمهای مبتنی بر قانون مورد تأیید قرار گرفته بودند.
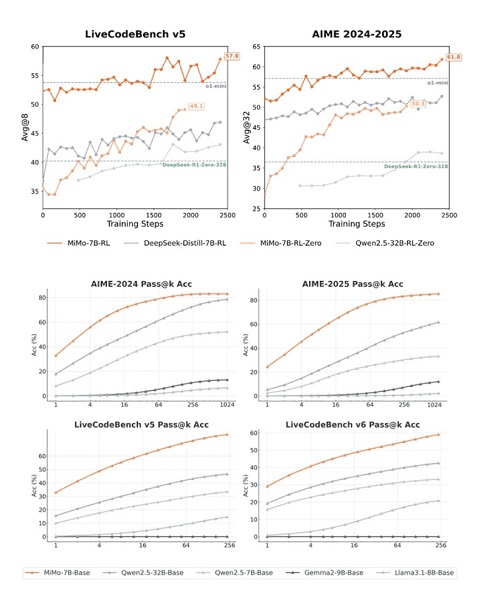
شیائومی فقط یک نسخه از MiMo منتشر نکرده، بلکه سری MiMo-7B شامل چهار نسخه است که میتوانید آنها را بررسی کنید:
- MiMo-7B-Base: مدل پایه که گفته میشود پتانسیل استدلال قوی دارد.
- MiMo-7B-RL-Zero: یک مدل یادگیری تقویتی که مستقیماً از آن نسخه پایه آموزش داده شده است.
- MiMo-7B-SFT: نسخهای که با استفاده از تنظیم دقیق نظارتشده (نشان دادن مثالها به آن) ایجاد شده است.
- MiMo-7B-RL: یک مدل یادگیری تقویتی است که از نسخه SFT آموزش داده شده و مدلی است که شیائومی آن را در برابر مدلهایی مانند o1-mini محک میزند.
شيائومي کل مجموعه هوش مصنوعی MiMo-7B را به صورت متنباز درآورده است. شما ميتوانيد اين مدلها را در Hugging Face پیدا کنید. اگر ميخواهيد به جزئيات فني عميقتر را بدانید، گزارش کاملي در GitHub منتشر شده است.
source