الگوریتم SJF در سیستم عامل برای ایجاد نظم در فرایندهایی استفاده میشود که درخواست استفاده از منابع سختافزاری مانند CPU را دارند. سیستم عاملها برای مدیریت این عملیات از مجموعه بزرگی از الگوریتمهای متنوع استفاده میکنند. واژه SJF سرنامی از کلمات عبارت انگلیسی «اول کوتاهترین کار» برابر با «Shortest Job First» است. در الگوریتم اول کوتاهترین کار، همیشه اولین وظیفهای که به CPU، اختصاص داده میشود، کوچکترین «زمان تکمیل فرایند» (Burst Time) را دارد. برای همین، فرایندهایی که در ساختمان داده صف اجرا زمان تکمیل کار کوتاهتری دارند، با سرعت بیشتری توسط CPU پذیرفته شده و اجرا میشوند.


در این مطلب از مجله فرادرس به صورت کامل و همراه با جزئیات به بررسی الگوریتم SJF در سیستم عامل پرداختهایم. از تعریف این الگوریتم و بررسی روش کار آن شروع کرده و سپس با کمک زبان جاوا به پیادهسازی کدهای آن پرداختیم. در نهایت هم انواع استراتژیهای مورد استفاده SJF را همراه با معایب و مزایای استفاده از این الگوریتم بیان کردهایم.
الگوریتم SJF در سیستم عامل چیست؟
الگوریتم SJF در سیستم عامل، برای زمانبندی منابع مورد استفاده – به طور خاص CPU، حافظه و ماژولهای ورودی و خروجی – به کار برده میشود. مهمترین ویژگیها برای شناخت این الگوریتم را در فهرست زیر بیان کردهایم.
- SJF یکی از الگوریتمهای زمان بندی پردازشها در سیستم عامل است که الگوریتمها را بر اساس کوتاهترین زمان اجرا مرتب کرده و به CPU ارسال میکند. بعد از آن به سراغ فرایندی میرود که زمان اجرایش از باقی فرایندهای موجود در صف کوتاهتر است و البته از فرایند قبلی زمان اجرای بیشتری دارد.
- الگوریتم SJF با دو استراتژی «انحصاری» (Non-Preemptive) و «غیرانحصاری» (Preemptive) کار میکند.
- یکی از مزیتهای چشمگیر الگوریتم SJF، کاهش میانگین زمان انتظار برای اجرا شدن فرایندها است.
- الگوریتم اول کوتاهترین کار را با نامهای «بعدی، کوتاهترین کار» (Shortest Job Next | SJN) یا «بعدی، کوتاهترین فرایند» (Shortest Process Next | SPN) نیز میشناسند.
- از الگوریتمهای RR و FCFS و HRRN میتوان به عنوان بعضی از رقبای SJF برای زمانبندی CPU نام برد.
اگرچه محاسبه زمان تکمیل کار فرایندها ممکن است که کار بسیار مشکلی باشد و به همین دلیل استفاده از این تکنیک در فرایند زمانبندی کارهای سیستم عامل خیلی سخت است. در ادامه مطلب، روشهای مختلف مدیریت این چالش بزرگ در سیستم عامل را بررسی کردهایم.
روش های محاسبه زمان تکمیل فرایند
زمان تکمیل فرایندها را فقط میتوان پیشبینی کرد یا به صورت تقریبی بدست آورد. برای اینکه الگوریتم SJF بهترین عملکرد ممکن را ارائه دهد، تخمینهای زده شده باید دقیق باشند. روشهای بسیار زیادی برای پیشبینی زمان کار CPU بر روی فرایندها تعریف شدهاند که میتوان از بین آنها انتخاب و استفاده کرد. به طور کلی این روشها به دو دسته زیر تقسیم میشوند.
- روشهای ایستا
- روشهای پویا
در ادامه، این دو دسته روش را به صورت جزئیتری توضیح دادهایم.
روش های ایستا برای تخمین Burst Time
برای تخمین تقریبی زمان تکمیل هر فرایند با روشهای ایستا، دو راهکار مختلف در دسترس است. تمام روشهای ایستا از این راهکارها استفاده میکنند. در پایین، هر دو راهکار را معرفی کرده و توضیح دادهایم.
- اندازه فرایند: در این روش زمان تکمیل کار فرایند بعدی را با استفاده از زمان تکمیل کار فرایند قدیمی، تخمین میزنیم که اندازهای برابر با اندازه فرایند بعدی دارد.
- نوع فرایند: بسته به نوع فرایند، میتوان زمان تکمیل کار آن را تخمین زد. چندین نوع مختلف برای فرایندها وجود دارد. برای مثال، میتوان به «فرایندهای پشت صحنه» (Background Processes)، فرایندهای مربوط به کاربر، فرایندهای مربوط به سیستم عامل و غیره اشاره کرد.

روش های پویا برای تخمین Burst Time
در این قسمت از مطلب، روشهای پویا برای تخمین زمان تکمیل فرایند را به دو دسته مختلف تقسیم کردهایم. تمام روشهای پویا در این دو دسته قرار میگیرند. در پایین، هر دو روش را معرفی کرده و توضیح دادهایم.
- میانگینگیری ساده: در روش میانگینگیری ساده، لیستی از فرایند مختلف به صورت P(1) و P(2) و P(3) و الی P(n) فراهم شده است. سپس از متغیر برای نمایش زمان تکمیل کار فرایند i -ام استفاده میکنیم. مقدار برابر با زمان تکمیل کار تخمین زده شده برای فرایند شماره P است.
در نتیجه، زمان تخمین زده شده برای تکمیل فرایند را میتوان با کمک فرمول زیر محاسبه کرد.
در فرمول بالا، اگر باشد، برابر با مجموعه زمان تکمیل کار همه فرایندها است.
- «میانگینگیری یا سالخوردگی تصاعدی» (Exponential Averaging or Aging): فرض کنیم که نشان دهنده زمان دقیق تکمیل کار فرایند شماره -ام است. اگر زمان تخمینزده شده فرایند -ام برابر با باشد. زمان تخمینی انجام کار فرایند بعدی – یعنی - در CPU را میتوان با کمک فرمول زیر محاسبه کرد.
در فرمول بالا، متغیر نشاندهنده فاکتور هموارسازی در محاسبات است و محدوده مقادیر آن بین تا را شامل میشود.
ویژگی های الگوریتم زمان بندی SJF
این الگوریتم دارای ویژگیهای خاصی است که باعث شده با بقیه تکنیکهای زمانبندی به صورت واضح فرق داشته باشد. در فهرست زیر، ویژگیهای الگوریتم زمانبندی SJF را بیان کردهایم.
- الگوریتم زمانبندی SJF، کوتاهترین میانگین زمان انتظار را در بین تمام روشهای زمانبندی به خود اختصاص داده است.
- الگوریتم SJF در دسته الگوریتمهای «حریصانه» (Greedy) دستهبندی میشود.
- اگر فرایندهای کوتاه دائما در حال تولید باشند، به طور قطع میتوان گفت که با «مشکل گرسنگی» (Starvation Problem) روبهرو میشویم. برای مدیریت این اتفاق میتوان از تکنیک «Ageing» استفاده کرد.
- سیستم عامل نمیتواند زمان دقیق مربوط به تکمیل فرایندها را محاسبه کند. بنابراین مرتبکردن فرایندها بر اساس زمان تکمیل کار آنها و قبل از ارسال به CPU تقریبا غیر ممکن است. اگرچه زمان تکمیل فرایند را نمیتوان محاسبه کرد اما با استفاده از تکنیکهای متنوعی میتوان حد تقریبی آن را تخمین زد. برای مثال میتوان از روش «میانگین وزنداده شده زمانهای اجرای قبلی» استفاده کرد.
- از این الگوریتم میتوان در محیطهای اختصاصیسازی شدهای استفاده کرد که تخمینهای دقیقی از زمان تکمیل فرایند یا زمان اجرای اپلیکیشنها در دسترس است.

نکته: Ageing به روشی گفته میشود که در طی آن به فرایندهای موجود در صف بر اساس زمان انتظار آنها نمره داده میشود. با بیشتر شدن زمان انتظار، نمره هم بیشتر میشود. در نهایت برای انتخاب فرایند با هدف ارسال به CPU، به غیر از کوتاهترین زمان تکمیل کار، نمرههای آنها هم تاثیر دارد.
آموزش طراحی الگوریتم در فرادرس
در مطلب حاضر درباره الگوریتم SJF برای زمانبندی CPU صحبت کردهایم. اما نکته مهم این است که علاوه بر شناخت این الگوریتمها باید نسبت به روش کلی طراحی و نوشتن الگوریتم نیز آشنا باشیم. در حال حاضر، الگوریتمها نقش بسیار مهمی، تقریبا در همه عرصههای علوم کامیپوتری و مهندسی ایفا میکنند. به همین ترتیب، در مدیریت منابعی مانند CPU و حافظه هم از الگوریتمها استفاده میشود. در برنامههای بزرگتر و و پیچیدهتر، مدیریت مصرف منابعی مانند پردازشگر از اهمیت بیشتری برخوردار است.

وبسایت آموزشی فرادرس، تلاش میکند تمام مطالب مربوط به هر رشته علمی، صنعتی و غیره را در فیلمهای خود پوشش دهد. طراحی و نوشتن الگوریتمهای برنامهنویسی، یکی از اهداف مهم فرادرس برای آموزش و انتشار محتوی در کشور است. دانشجویان علوم کامپیوتر با کمک این فیلمها میتوانند خود را برای آزمونهای دانشگاهی، مانند کنکور ارشد و دکتری آماده کنند. در ادامه این بخش، چند مورد از فیلمهای آموزشی فرادرس درباره طراحی الگوریتم را معرفی کردهایم. مخاطبان فرادرس، میتوانند هر کدام از موارد پایین را انتخاب کرده یا با کلیک بر روی تصویر بالا به صفحه اصلی این مجموعه آموزشی هدایت شده و سایر فیلمها را مشاهده کنند.
روش کار الگوریتم SJF در سیستم عامل
الگوریتمهای زمانبندی متنوعی برای بهینهسازی کار سیستم عامل طراحی و ارائه شدهاند. بعضی از این موارد برای کمک به زمانبندی انجام فرایندها در CPU استفاده میشوند. برخی دیگر هم برای کمک به زمانبندی بهتر عملیات نوشتن و خواند از دیسک حافظه به کار برده میشوند. داشتن مهارت ایجاد الگوریتمهای زمانبندی سیستمعامل و مدیریت حافظه با کمک زبان Java یکی از بهترین مهارتهای هر توسعهدهندهی سیستم عامل است. به همین منظور پیشنهاد میکنیم که فیلم آموزش الگوریتم های زمان بندی سیستم عامل با جاوا درباره پیاده سازی ۷ الگوریتم مختلف را از فرادرس مشاهده کنید. برای کمک، لینک مربوط به این فیلم را در پایین نیز قرار دادهایم.
به صورت خلاصه، کل مراحل کار الگوریتم SJF را در سه بخش اصلی میتوان تقسیم کرد. همه این بخشها را در فهرست زیر، توضیح دادهایم.
- در ابتدای کار، همه فرایندهایی خواهان CPU را بر اساس زمان رسیدن درخواست هر کدام مرتب میکنیم. با این کار اولین فرایندی که باید اجرا شود مشخص میشود. با این تکنیک مطمئن میشویم فرایندی که اول از همه رسیده و کوتاهترین زمان تکمیل کار را دارد، اول از همه به CPU ارسال شده و اجرا میشود.
- بهجای اینکه به صورت مستقیم به لیست فرایندهای صفبندی شده مراجعه کنیم و آنها را یک به یک برای پیدا کردن کوتاهترین زمان فرایند بررسی کنیم، از ساختمان داده «درخت بازهها» (Segment Trees) برای پیدا کردن کمترین زمان اجرای فرایند استفاده میکنیم.
- بعد از پیدا کردن فرایند دارای صلاحیت ارسال به CPU، از اطلاعات «زمان رسیدن» (Arrival Time | AT) به صف و «زمان تکمیل فرایند» (Burst Time | BT) برای محاسبه زمانهای مختلف استفاده میکنیم.
به عنوان مثالی از زمانهای مختلف، میتوان به «زمان مورد نیاز برای انجام فعالیت» (Turn-Around Time | TAT) در هر فرایند، «زمان انتظار» (Waiting Time | WT) در صف هر فرایند برای رسیدن به منبع درخواست شده و «زمان تکمیل عملیات» (Completion Time | CT) اشاره کرد.
برای نمونه، در تصویر زیر روند کاری این الگوریتم با به صورت خلاصه نمایش دادهایم.
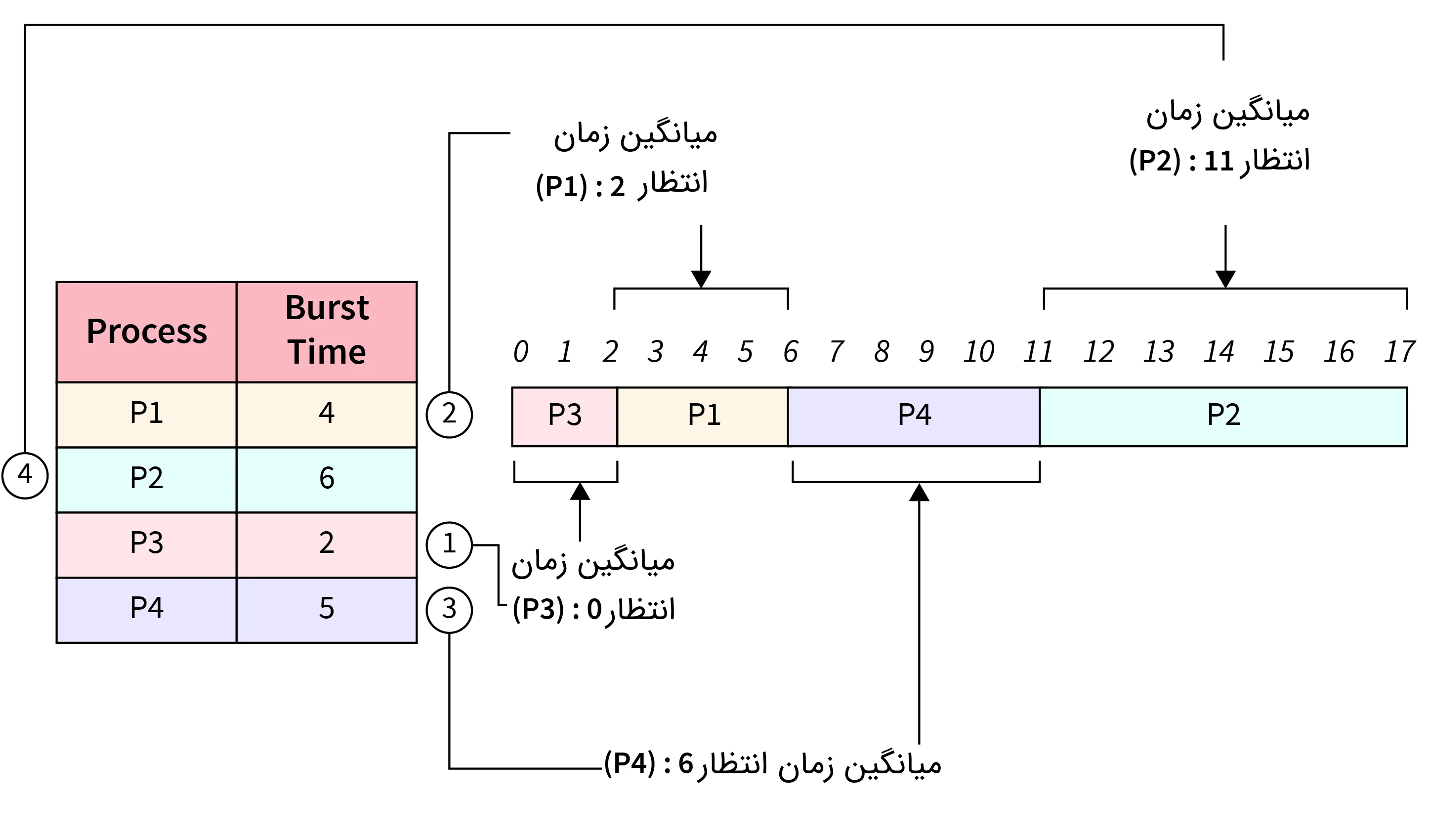
در مثال بالا، زمان رسیدن هر فرایند را برابر با 0 در نظر گرفتهایم. فرایندها بر طبق زمان تکمیل کار به صورت صعودی مرتب شدهاند. زیرا زمان رسیدن همه آنها 0است. در نتیجه فرایندها با ترتیب زیر اجرا میشوند.
تمام مراحل زمانبندی فرایندهای بالا را شمارهگذاری کردهایم. سپس اتفاق رخ داده شده در هر شماره را به ترتیب در پایین توضیح دادیم.
- از آنجا که فرایند P3 کوتاهترین زمان تکمیل فرایند – 2 واحد زمانی – را دارد، اول از همه هم اجرا میشود.
- در مرحله دوم فرایند P2 اجرا میشود. زیرا زمان تکمیل فرایند P2 برابر با 4 است. بنابراین بعد از فرایند P3 و قبل از فرایندهای P1 و P4 اجرا میشود.
- زمان تکمیل فرایند P4 برابر با 5 است بنابراین به عنوان سومین فرایند اجرا میشود.
- در نهایت هم، به دلیل اینکه زمان تکمیل فرایند P2 در بین بقیه فرایندها از همه بیشتر است – برابر با 6 واحد زمانی – P2 آخر از همه نیز اجرا میشود.
محاسبه زمان های مختلف هر فرایند در SJF
منظور از زمانهای فرایند، همان زمانهای نام برده شده در بخش بالایی، یعنی زمان تکمیل عملیات، زمان مورد نیاز برای انجام فعالیت و زمان انتظار است. برای محاسبه زمانهای مختلف هر فرایند باید با زمانبندی CPU و انواع الگوریتمهای زمان بندی در سیستم عامل آشنا باشیم.
زمان تکمیل عملیات CT
«زمان تکمیل عملیات» (Completion Time | CT) فرایندها در CPU، به زمان به پایان رسیدن اجرای آنها گفته میشود. با جمع بستن زمان شروع به اجرای کار فرایند (ST) و زمان تکمیل کار فرایند (BT)، زمان تکمیل عملیات هر فرایند (CT) را محاسبه میکنند.
زمان مورد نیاز برای انجام فعالیت TAT
«زمان مورد نیاز برای انجام فعالیت» (Turn-Around Time | TAT) به تفاوت بین زمان تکمیل فرایند (CT) و زمان رسیدن به صف اجرا (AT) گفته میشود. با کمک فرمول زیر میتوان زمان مورد نیاز برای انجام فعالیت هر فرایند را محاسبه کرد.
زمان انتظار WT
«زمان انتظار» (Waiting Time | WT) به تفاوت بین زمان مورد نیاز برای انجام فعالیت (TAT) و و زمان تکمیل کار فرایند (BT) گفته میشود. با کمک فرمولهای زیر میتوان این زمان را محاسبه کرد.
پیاده سازی SJF با زبان جاوا
در این قسمت از مطلب، الگوریتم SJF در سیستم عامل را با استفاده از زبان برنامه نویسی جاوا کدنویسی کردهایم.
1import java.util.*;
2
3public class SJF {
4 public static void main(String[] args)
5 {
6 int NumberOfProcesses = 5;
7
8 // process and burst time initialization
9 range.processID = Integer.MAX_VALUE;
10 range.burstTime = Integer.MAX_VALUE;
11
12 for (int i = 1; i <= 4 * sh + 1; i++)
13 {
14 segmentTree[i].processID = Integer.MAX_VALUE;
15 segmentTree[i].burstTime = Integer.MAX_VALUE;
16 }
17
18 // Assigning Arrival time, Burst time and Process ID
19 // to all the static array of processInfo for SJF implementation
20 processInfo[1].arrival_time = 1;
21 processInfo[1].burst_time = 7;
22 processInfo[1].process_id = 1;
23
24 processInfo[2].arrival_time = 2;
25 processInfo[2].burst_time = 5;
26 processInfo[2].process_id = 2;
27
28 processInfo[3].arrival_time = 3;
29 processInfo[3].burst_time = 1;
30 processInfo[3].process_id = 3;
31
32 processInfo[4].arrival_time = 4;
33 processInfo[4].burst_time = 2;
34 processInfo[4].process_id = 4;
35
36 processInfo[5].arrival_time = 5;
37 processInfo[5].burst_time = 8;
38 processInfo[5].process_id = 5;
39
40 executeSJF(NumberOfProcesses);
41
42 printCalculatedTimes(NumberOfProcesses);
43 }
44
45 static int sh = 100000;
46
47 static class info
48 {
49 int process_id; // PID
50 int arrival_time; // AT
51 int burst_time; // BT
52 int completion_time; // CT
53 int turn_around_time; // TAT
54 int waiting_time; // WT
55 }
56
57 // processInfo Array to contain all the process information of type info
58 static info[] processInfo = new info[sh + 1];
59
60 // static block code for array initialization
61 static
62 {
63 for (int i = 0; i < sh + 1; i++)
64 {
65 processInfo[i] = new info();
66 }
67 }
68
69 static class info1
70 {
71 int processID;
72 int burstTime;
73 }
74
75 static info1 range = new info1();
76
77 // Segment tree array processing the queries with
78 // time complexity O(N(logN))
79 static info1[] segmentTree = new info1[4 * sh + 5];
80 static {
81 for (int i = 0; i < 4 * sh + 5; i++) {
82 segmentTree[i] = new info1();
83 }
84 }
85
86 // keeping a check where
87 // a PID is present in our segmentTree info1 type array
88 static int[] mp = new int[sh + 1];
89
90 // method to update BT and PID in our segmentTree
91 static void updateTree(int node, int start, int end,
92 int index, int pID, int bTime)
93 {
94 if (start == end) {
95 segmentTree[node].processID = pID;
96 segmentTree[node].burstTime = bTime;
97 return;
98 }
99 int mid = (start + end) / 2;
100
101 // recursive call to update
102 if (index <= mid) {
103 updateTree(2 * node, start, mid, index, pID, bTime);
104 }
105 else {
106 updateTree(2 * node + 1, mid + 1, end, index, pID, bTime);
107 }
108
109 if (segmentTree[2 * node].burstTime < segmentTree[2 * node + 1].burstTime) {
110 segmentTree[node].burstTime = segmentTree[2 * node].burstTime;
111 segmentTree[node].processID = segmentTree[2 * node].processID;
112 } else {
113 segmentTree[node].burstTime = segmentTree[2 * node + 1].burstTime;
114 segmentTree[node].processID = segmentTree[2 * node + 1].processID;
115 }
116 }
117
118 // method to return the range minimum of the burst time
119 // of all the arrived processes using segment tree
120 static info1 queryProcess(int node, int start, int end,
121 int left, int right) {
122 if ((end < left) || (start > right)) {
123 return range;
124 }
125 if ((start >= left) && (end <= right)) {
126 return segmentTree[node];
127 }
128 int mid = (start + end) / 2;
129 info1 lm = queryProcess(2 * node, start, mid, left, right);
130 info1 rm = queryProcess(2 * node + 1, mid + 1, end, left, right);
131
132 if (lm.burstTime < rm.burstTime){
133 return lm;
134 }
135 return rm;
136 }
137
138 // method to execute non_preemptive SJF and return the
139 // CT, TAT and WT
140 static void nonPreemptiveSJF(int n) {
141
142 // to keep a count of the finished processes
143 int count = n;
144
145 // To keep the range of the processes that have arrived in the array
146 int upper_range = 0;
147
148 // Current running time
149 int runningTime = Math.min(Integer.MAX_VALUE, processInfo[upper_range + 1].arrival_time);
150
151 // to find the CPU processes where AT is less than or equal to their CT
152 while (count != 0) {
153 while (upper_range <= n) {
154 upper_range++;
155 if (processInfo[upper_range].arrival_time > runningTime || upper_range > n) {
156 upper_range--;
157 break;
158 }
159
160 updateTree(1, 1, n, upper_range, processInfo[upper_range].process_id,
161 processInfo[upper_range].burst_time);
162 }
163
164 // To find the minimum CT from the processes whose
165 // AT is less than or equal to their CT
166 info1 result = queryProcess(1, 1, n, 1, upper_range);
167
168 // Checking if the process has already been executed
169 if (result.burstTime != Integer.MAX_VALUE) {
170 count--;
171 int index = mp[result.processID];
172 runningTime += (result.burstTime);
173
174 // Calculating and updating the array with
175 //The CT, TAT and WT
176 processInfo[index].completion_time = runningTime;
177 processInfo[index].turn_around_time = processInfo[index].completion_time - processInfo[index].arrival_time;
178 processInfo[index].waiting_time = processInfo[index].turn_around_time - processInfo[index].burst_time;
179
180 // Updating the burst time to infinity, when the process has finished executing
181 updateTree(1, 1, n, index, Integer.MAX_VALUE, Integer.MAX_VALUE);
182 } else {
183 runningTime = processInfo[upper_range + 1].arrival_time;
184 }
185 }
186 }
187
188 // to execute the SJF algorithm and related methods in the program
189 static void executeSJF(int n) {
190
191 // Sorting the processInfo array based on the arrival times of the processes
192 Arrays.sort(processInfo, 1, n, (a, b) -> {
193 if (a.arrival_time == b.arrival_time)
194 return a.process_id - b.process_id;
195 return a.arrival_time - b.arrival_time;
196 });
197 for (int i = 1; i <= n; i++)
198 mp[processInfo[i].process_id] = i;
199
200 // invoking to perform non-preemptive-sjf
201 nonPreemptiveSJF(n);
202 }
203
204 // print calculated times of each processID after the SJF execution
205 static void printCalculatedTimes(int n) {
206 System.out.println("PID ArrivalT BurstT CompletionT TAT WaitingT");
207 for (int i = 1; i <= n; i++) {
208 System.out.printf("%dtt%dtt%dtt%dtt%dtt%dn",
209 processInfo[i].process_id, processInfo[i].arrival_time, processInfo[i].burst_time, processInfo[i].completion_time, processInfo[i].turn_around_time,
210 processInfo[i].waiting_time);
211 }
212 }
213}بعد از اجرای کدهای بالا، خروجی زیر تولید شده و به کاربر نمایش داده میشود.
PID ArrivalT BurstT CompletionT TAT WaitingT 1 1 7 8 7 0 2 2 5 16 14 9 3 3 1 9 6 5 4 4 2 11 7 5 5 5 8 24 19 11 === Code Execution Successful ===
انواع استراتژی های الگوریتم SJF در سیستم عامل
همینطور که در بخشهای بالایی این مطلب اشاره شد، الگوریتم SJF یکی از چندین الگوریتم موجود برای زمانبندی انجام کارها در سیستم عامل است. هر کدام از این الگوریتمها رویکردهای خاصی را برای پیادهسازی دنبال میکنند. به منظور آشنایی با انواع الگوریتمهای زمانبندی در سیستم عامل میتوانید مطلب راهنمای جامع الگوریتم های زمان بندی (Scheduling Algorithms) در سیستم عامل را از مجله فرادرس مطالعه کنید.
برای پیادهسازی و استفاده از الگوریتم SJF در سیستم عامل دو استراتژی بسیار رایج وجود دارد.
- الگوریتم SJF با رویکرد «انحصاری» (Non-Preemptive)
- الگوریتم SJF با رویکرد «غیرانحصاری» (Preemptive)
در این قسمت از مطلب، روش کار این دو استراتژی متفاوت را توضیح داده و با کمک مثال سادهای بررسی میکنیم.
الگوریتم SJF با رویکرد انحصاری
در رویکرد انحصاری الگوریتم SJF، وقتی که فرایندی CPU را در اختیار گرفت، دیگر تا زمان به پایان رسیدن اجرای عملیات خود یا صدور دستور توقف اجرای فرایند از خارج – برای مثال توسط کاربر – CPU را رها نمیکند. برای درک بهتر این رویکرد اجرای الگوریتم مثالی را نمای دادهایم.
در این مثال، جدولی به شکل زیر شامل چهار فرایند مختلف داده شده است. این فرایندها برای در اختیار گرفتن CPU به سیستم عامل درخواست دادهاند.
| صف فرایندهای آماده به اجرا | زمان تکمیل فرایند BT | زمان رسیدن فرایند AT |
|---|---|---|
| P1 | ۲ | ۲ |
| P2 | ۵ | ۴ |
| P3 | ۳ | ۰ |
| P4 | ۴ | ۱ |
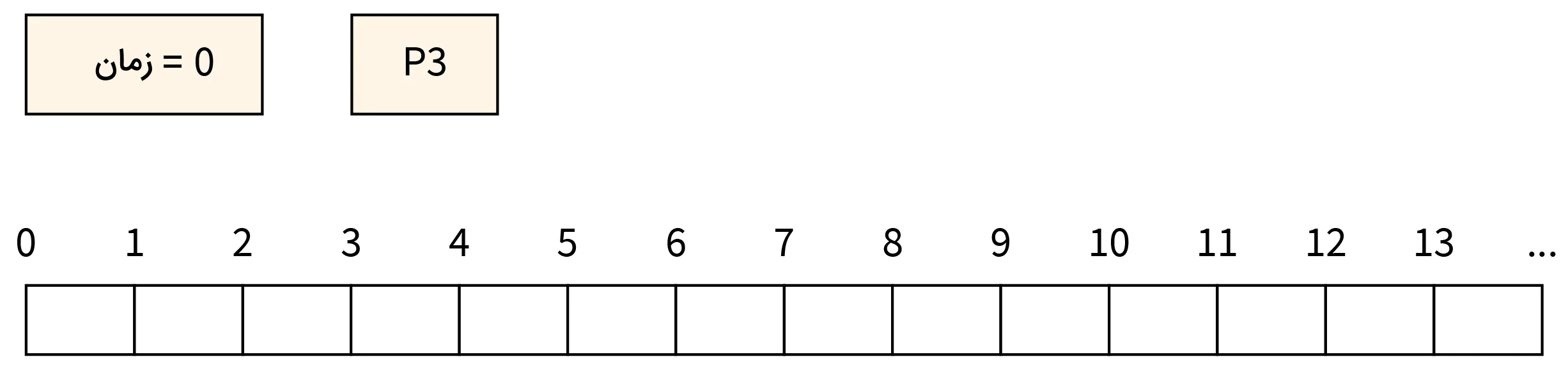
- مرحله صفر: در این مرحله، زمان برابر با صِفر است. P3 به صف وارد شده و به دلیل نبود هیچ رقیبی شروع به اجرای عملیات خود میکند.
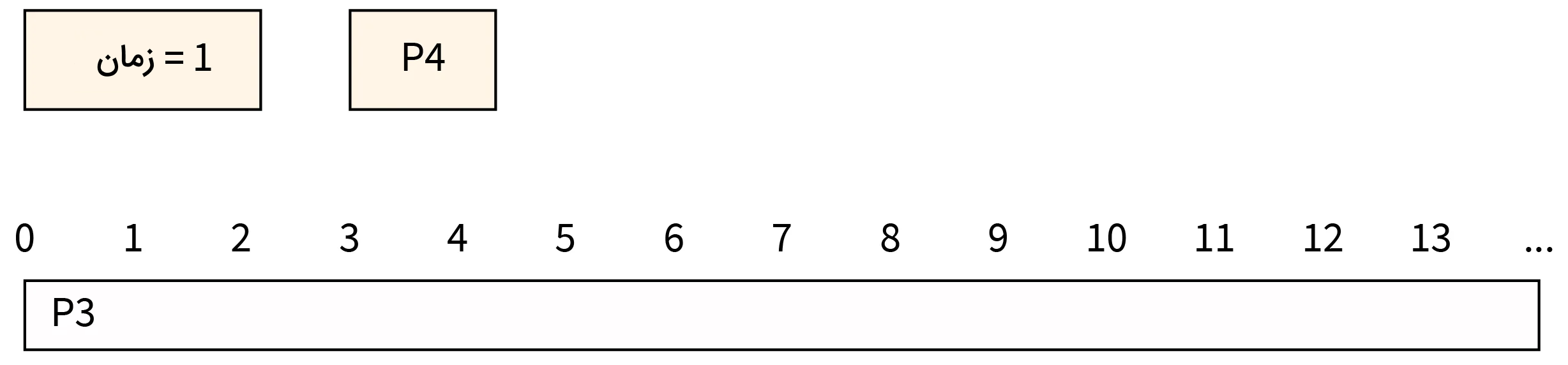
- مرحله اول: در زمان برابر با ۱ فرایند P4 از راه میرسد. اگرچه فرایند P3 هنوز به دو واحد زمانی برای اتمام عملیات خود نیاز دارد. بنابراین، P3 به اجرای باقیمانده کار خود بر روی CPU پرداخته و P4 به صف اجرا افزوده میشود.
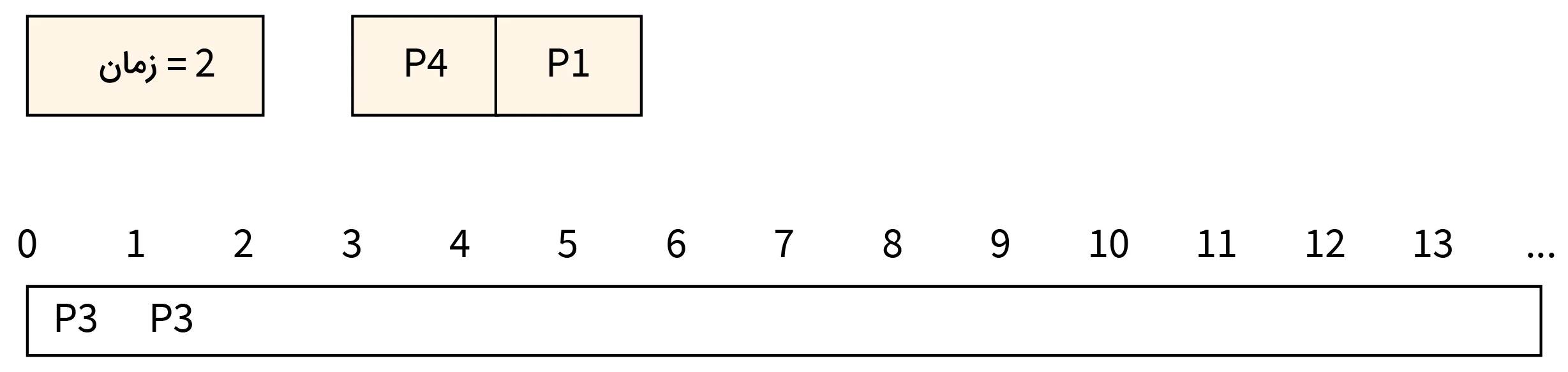
- مرحله دوم: در زمان برابر با ۲، فرایند P1 رسیده و به صف اجرا افزوده میشود. فرایند P3 هم ادامه کار خود را در CPU انجام میدهد.
- مرحله سوم: در زمان برابر با ۳، اجرای فرایند P3 به پایان میرسد. در نتیجه، برای ارسال فرایند بعدی به CPU باید زمان تکمیل عملیات P4 و P1 را با هم مقایسه کنیم. فرایند P1 برای اجرا به CPU منتقل میشود. زیرا – بر طبق اطلاعات داده شده در جدول بالا – زمان تکمیل فرایند P1 از زمان تکمیل فرایند P4 کوتاهتر است.
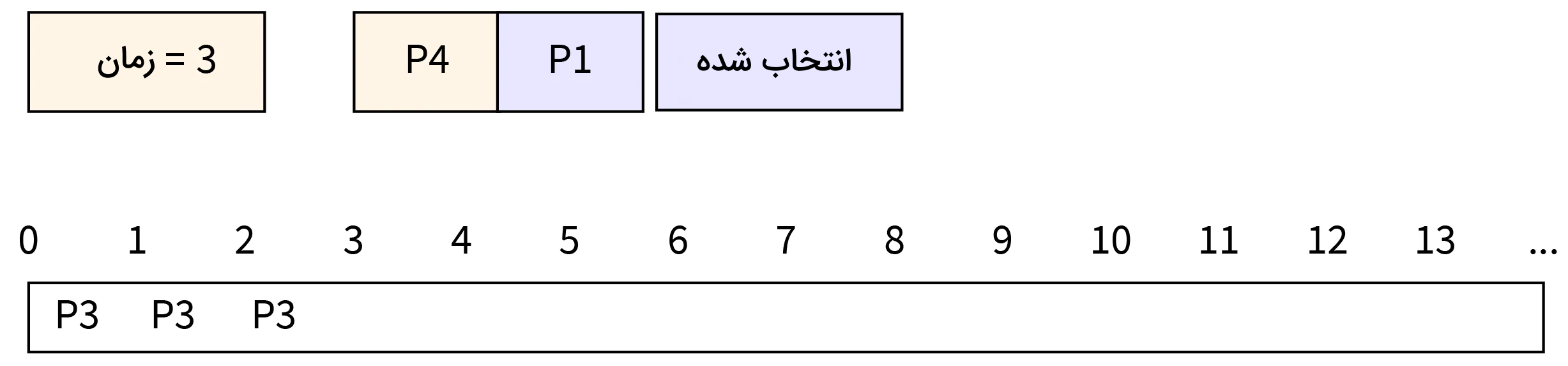
- مرحله چهارم: در زمان ۴، فرایند P2 رسیده و به صف اجرا افزوده میشود. در این زمان فرایند P1 همچنان به کار خود در CPU ادامه داده و فرایند P4 هم در صف باقی میماند.
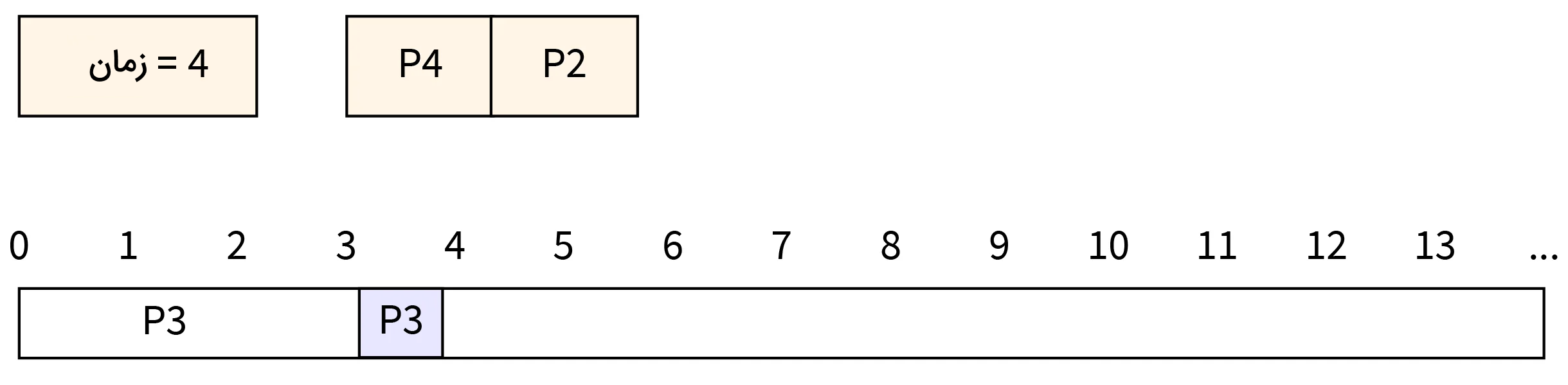
- مرحله پنجم: در زمان ۵، اجرای فرایند P1 تکمیل شده و این فرایند CPU را آزاد میکند. به همین صورت باید زمان تکمیل اجرای فرایندهای P4 و P2 را با یکدیگر مقایسه کنیم. از آنجا که فرایند P4 زمان تکمیل فرایند کوتاهتری نسبت به P2 دارد، CPU به فرایند P4 اختصاص داده میشود.
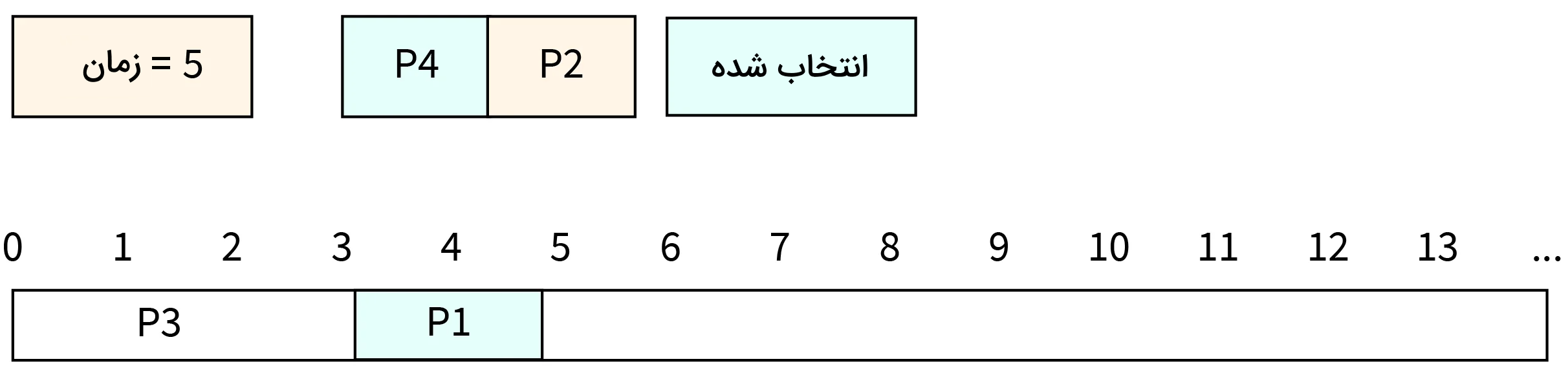
- مرحله ششم: در زمان ۶، فرایند P4 همچنان به کار خود در CPU ادامه میدهد.
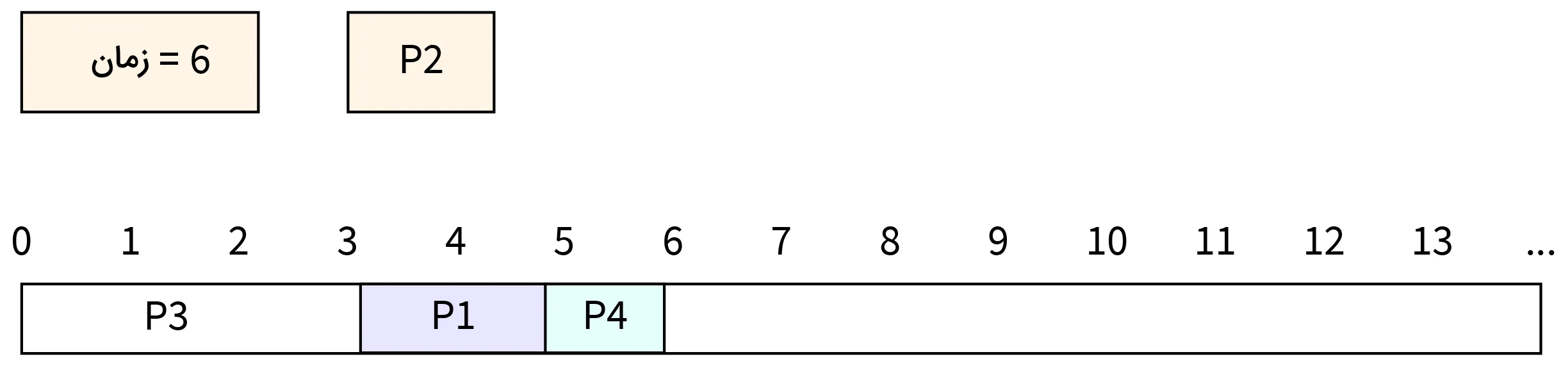
- مرحله هفتم: در زمان ۹، اجرای فرایند P4 تکمیل شده و این فرایند CPU را آزاد میکند. در نتیجه اکنون CPU به فرایند P2 اختصاص داده میشود.
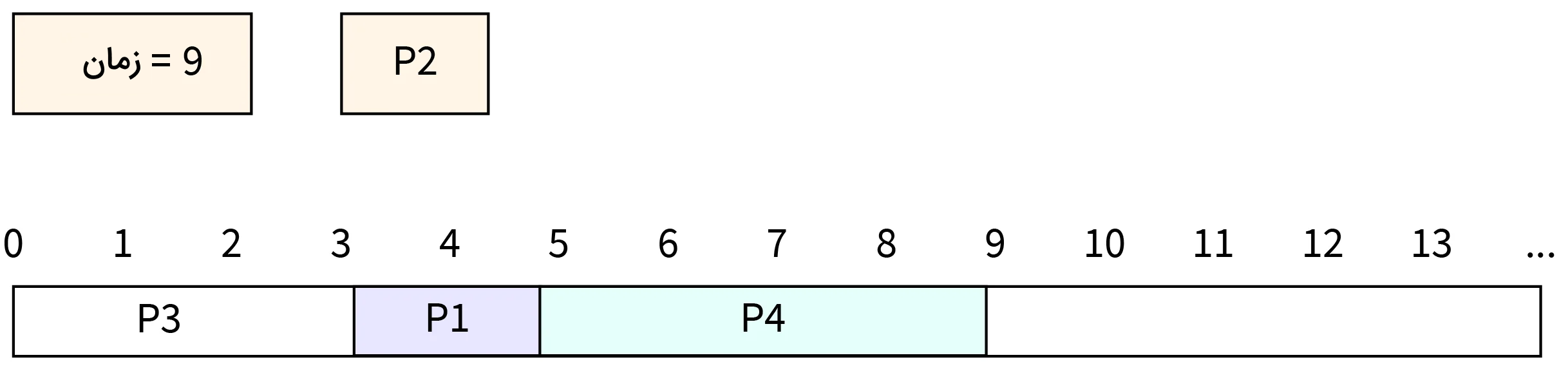
- مرحله هشتم: در زمان ۱۴، اجرای فرایند P2 تکمیل شده و این فرایند نیز CPU را آزاد میکند.
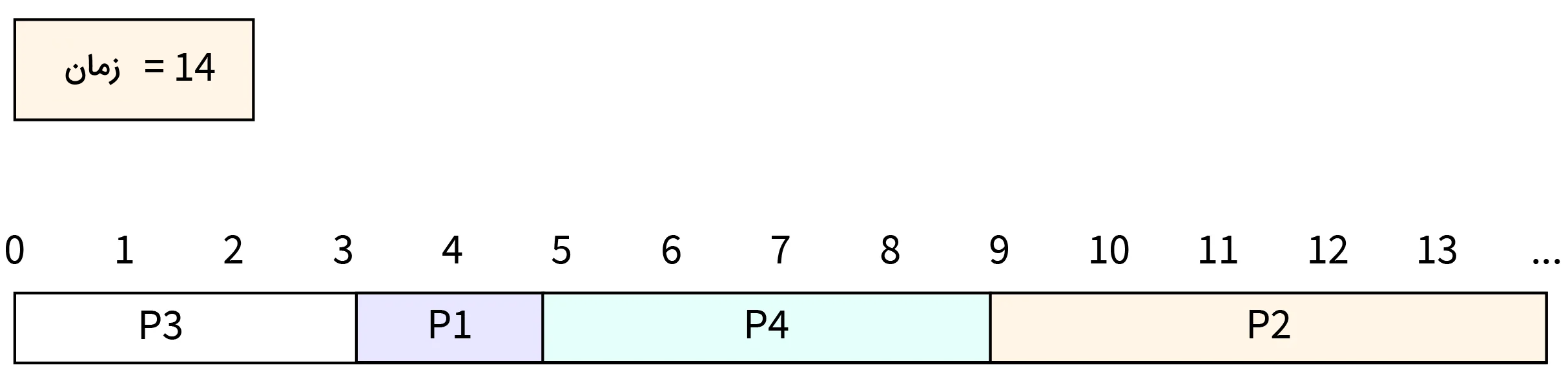
- مرحله نهم: در این مرحله میخواهیم میانگین زمان انتظار را برای فرایندها محاسبه کنیم. در ابتدا زمان انتظار هر کدام از فرایندها را به صورت مجزا حساب میکنیم.
سپس با کمک دادههای بدست آمده، میانگین زمان انتظار کلی (AWT) را برای فرایندها حساب میکنیم.
الگوریتم SJF با رویکرد غیرانحصاری
در رویکرد غیرانحصاری الگوریتم SJF هم همه وظایف به محض رسیدن به صف اجرا افزوده میشوند. فرایندی که کمترین زمان تکمیل کار را دارد، CPU را اشغال کرده و کار خود را شروع میکند. به همچنین اگر وظیفهای وارد صف شود که زمان تکمیل کار کمتری دارد، فرایند جاری مختومه شده یا از ادامه کار آن جلوگیری میشود. سپس فرایند متوقف شده به صف اجرا برمیگردد تا فرایند با کار کوتاهتر، CPU را اشغال کرده کار خود را شروع کند.
در مثال زیر، جدولی شامل چهار فرایند مختلف داده شده است. این فرایندها برای در اختیار گرفتن CPU به سیستم عامل درخواست دادهاند. در ادامه روش اختصاص CPU به این فرایندها را با کمک الگوریتم SJF و رویکرد غیرانحصاری نمایش دادهایم.
| صف فرایندهای آماده به اجرا | زمان تکمیل فرایند BT | زمان رسیدن فرایند AT |
|---|---|---|
| P1 | ۳ | ۰ |
| P2 | ۱ | ۴ |
| P3 | ۵ | ۱ |
| P4 | ۴ | ۲ |
- مرحله صفر: در این مرحله، زمان صِفر در نظر گرفته میشود. اول از همه، فرایند P1 از راه رسیده و بلافاصله اجرای خود را بر روی CPU شروع میکند. در این حالت، زمان رسیدن برابر با صفر و زمان تکمیل کار این فرایند برابر با ۳ است. این اطلاعات را در جدول بالا نمایش دادهایم.
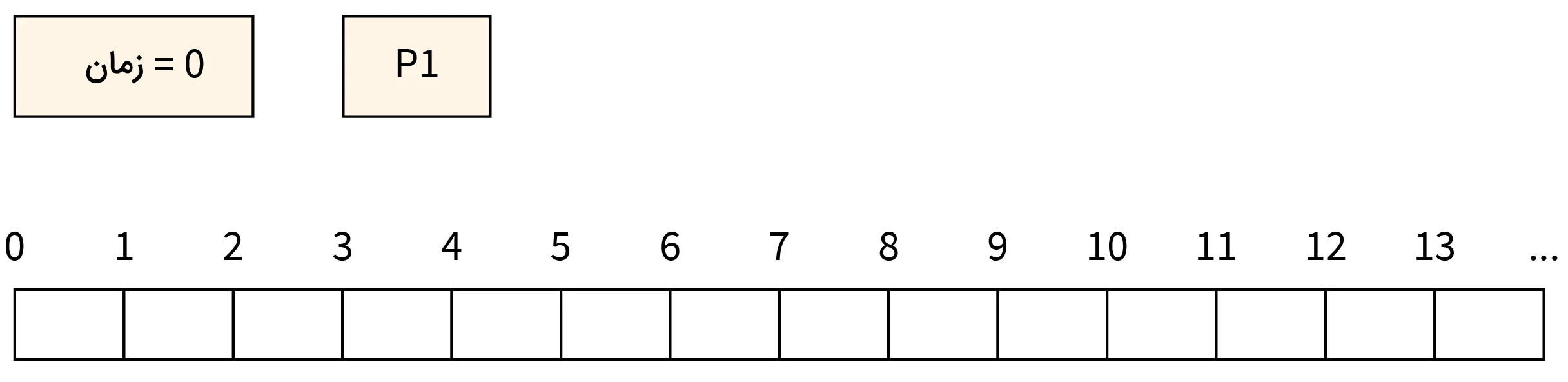
- مرحله یک: در زمان ۱ فرایند P3 از راه میرسد. زمان تکمیل فرایند P3 برابر با ۵ است. در نتیجه، P1 زمان تکمیل فرایند کوتاهتری داشته و به اجرای خود بر روی CPU ادامه میدهد. در همین حال P3 نیز به صف اجرا افزوده میشود.
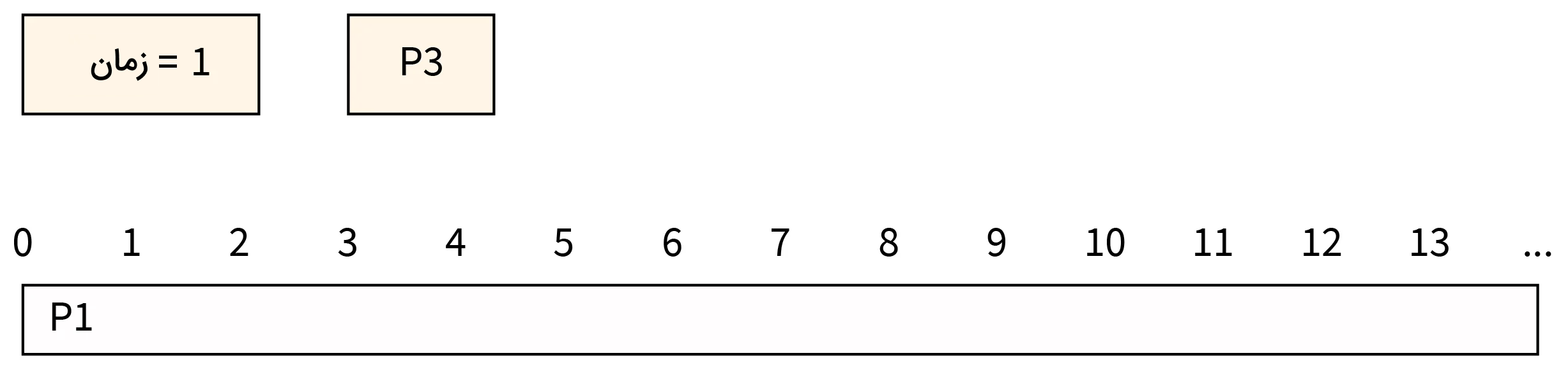
- مرحله دو: در زمان ۲، فرایند P4 از راه میرسد. زمان تکمیل کار این فرایند برابر با ۴ است. بنابراین این فرایند هم به صف اجرا افزوده شده و برای دسترسی به CPU منتظر میماند.
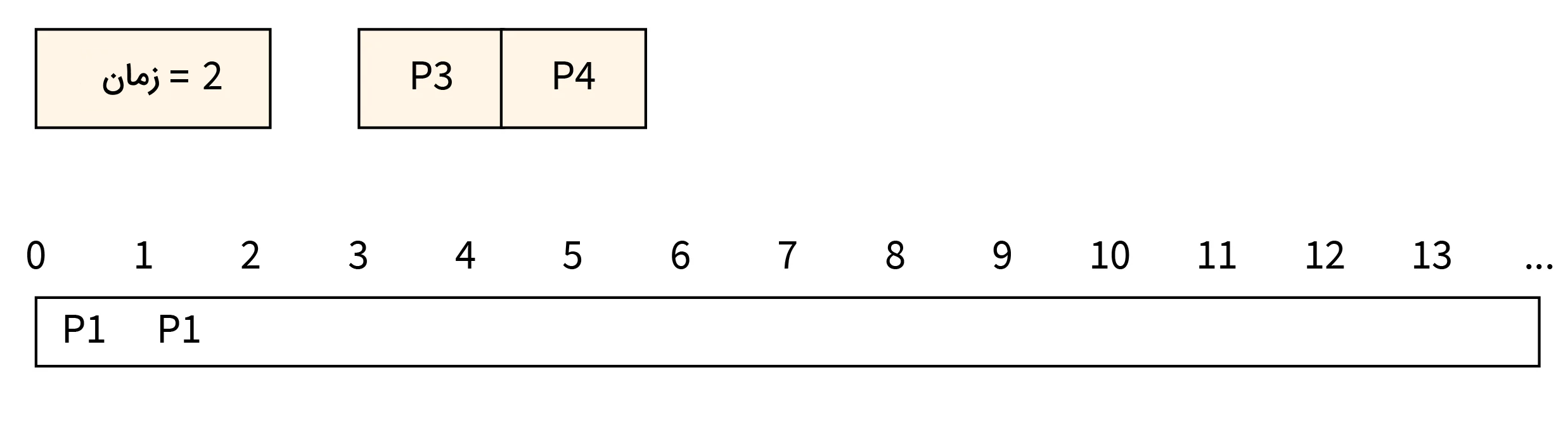
- مرحله سه: در زمان ۳، کار فرایند P1 تکمیل شده و CPU را آزاد میکند. پس زمان تکمیل عملیات P4 و P3 را با هم مقایسه میکنیم. فرایند P4 برای اجرا به CPU منتقل میشود. زیرا زمان تکمیل فرایند P4 از زمان تکمیل فرایند P3 کوتاهتر است.
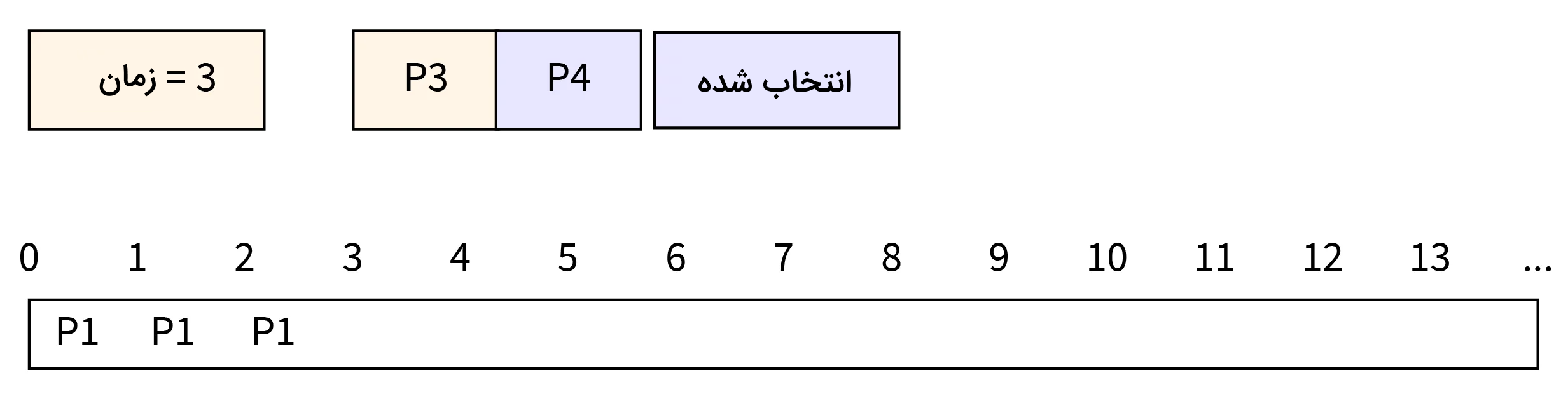
- مرحله چهار: در زمان ۴، فرایند P2 از راه میرسد. زمان تکمیل کار این فرایند برابر با ۱ است. در نتیجه در مقایسه با فرایند P4 که در حال اجرا بر روی CPU است، زمان تکمیل کار کوتاهتری دارد. در این حالت از ادامه کار فرایند P4 جلوگیری شده و فرایند P2، برای انجام کار خود به CPU ارسال میشود.
در این مرحله، جدول فرایندها چیزی شبیه به شکل زیر است.
| صف فرایندهای آماده به اجرا | زمان تکمیل فرایند BT | زمان رسیدن فرایند AT |
|---|---|---|
| P1 | صِفر باقیمانده | ۰ |
| P2 | ۱ | ۴ |
| P3 | ۵ | ۱ |
| P4 | باقیمانده | ۲ |
در تصویر پایتون، نمودار زمان اشغال CPU را تا این زمان نشان دادهایم.
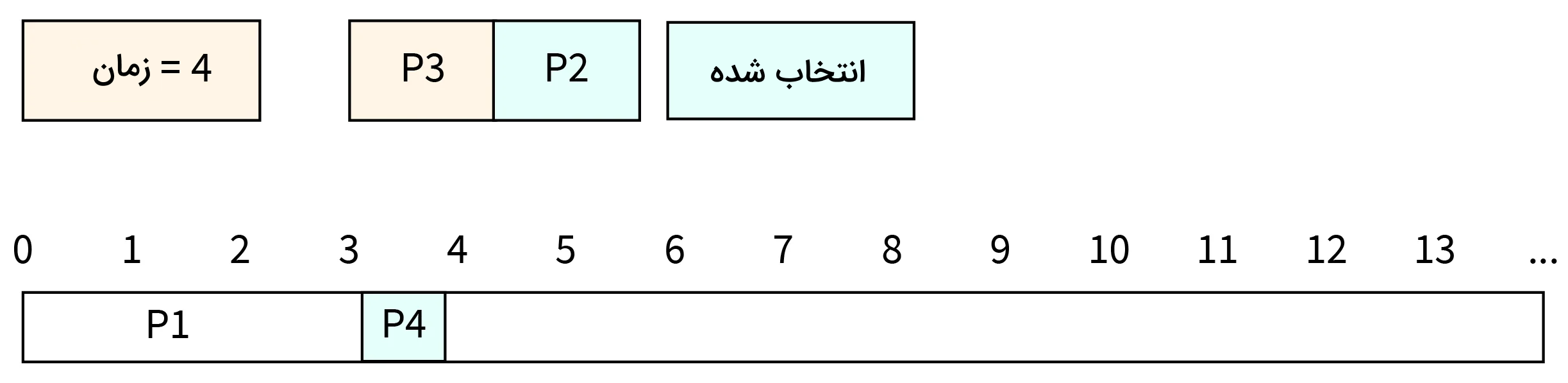
- مرحله پنج: در زمان ۵، اجرای فرایند P2 تکمیل شده و این فرایند CPU را آزاد میکند. از آنجا که P4 زمان تکمیل فرایند کوتاهتری نسبت به P3 دارد، پس فرایند P4 دوباره CPU را اشغال کرده و به تکمیل کار خود میپردازد.
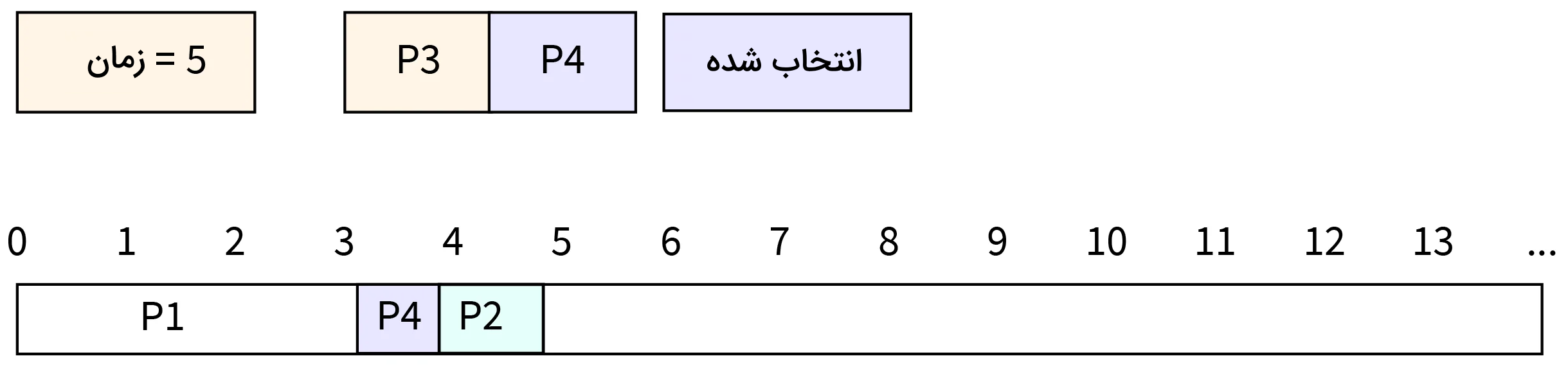
- مرحله شش: در زمان ۸ فرایند P4 اجرای خود را تکمیل کرده و CPU را آزاد میکند. فرایند P3 کار خود را در CPU شروع میکند.
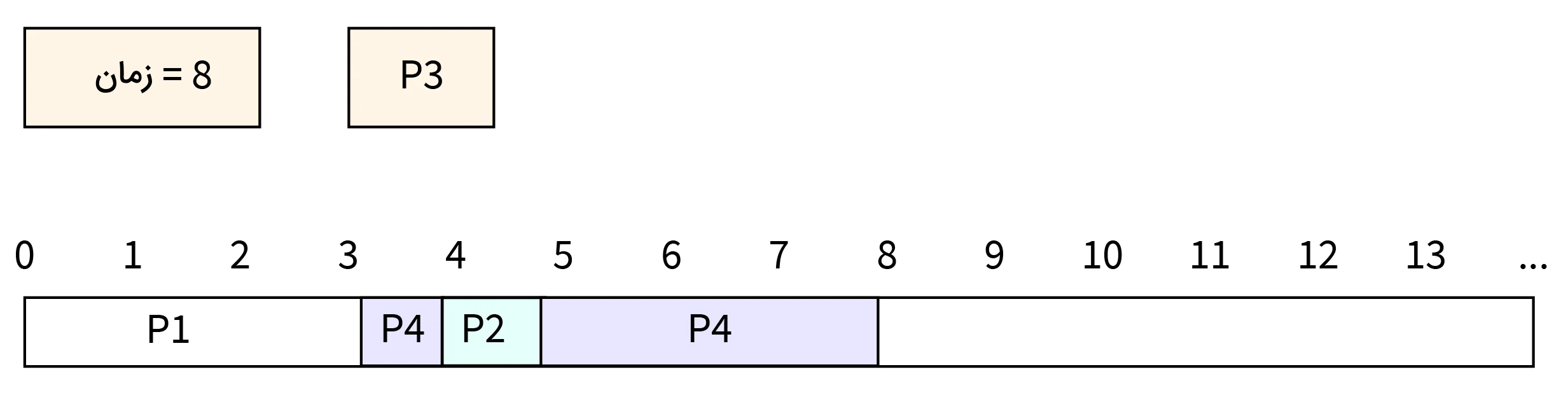
- مرحله هفت: در زمان ۱۳، فرایند P3 اجرای خود را تکمیل کرده و CPU را آزاد میکند.
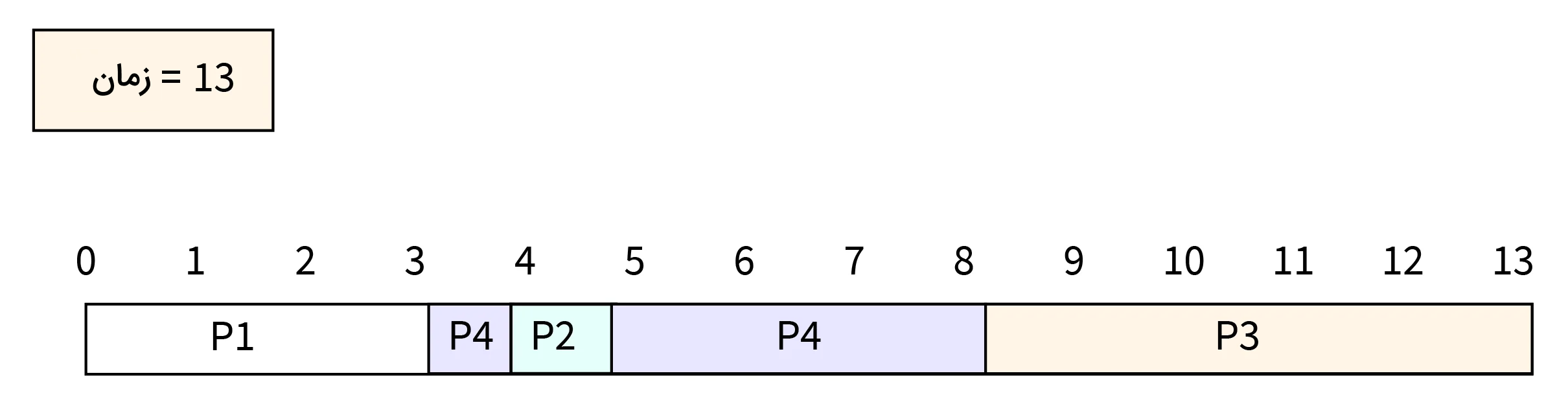
- مرحله هشت: در این مرحله میخواهیم میانگین زمان انتظار را برای فرایندها محاسبه کنیم. در ابتدا زمان انتظار هر کدام از فرایندها را به صورت مجزا حساب میکنیم.
سپس با کمک دادههای بدست آمده، میانگین زمان انتظار کلی که در اینجا برای سادگی آن را (AWT) نوشتهایم را میتوانیم برای فرایندها حساب کنیم.
آموزش درس های مربوط به الگوریتم و ساختمان داده
درسهای طراحی و نوشتن الگوریتم تقریبا در همه حوزههای مربوط به نرمافزار در دانشگاهها تدریس میشوند. دانشجویان برای موفقیت در تحصیل خود باید در این حوزهها هم مطالعه داشته باشند. فرادرس به عنوان تولید کننده انواع محتوای آموزشی، همیشه در تلاش بود تا بهترین فیلمها و مطالب را به شکل با کیفیت و بسیار کامل در اختیار مخاطبان خود قرار دهد. تماشای فیلمهای آموزشی فرادرس باعث کاهش هزینهها، افزایش بهرهوری و یادگیری بهتر درسها توسط دانشجویان همه رشتهها میشود. وبسایت آموزشی فرادرس، فیلمهای کاملی درباره طراحی الگوریتم و ساختمان دادهها تولید کرده است. در ادامه، چند مورد از این فیلمهای آموزشی را معرفی کردهایم.
مشاهده فیلمهای فرادرس برای اشخاص علاقهمند به استفاده کاربردی از علم نیز مفید است. زیرا فیلمهای فرادرس شامل مطالب کاربردی و مرتبط به پروژههای روز دنیا هستند. در صورت تمایل برای مشاهده فیلمهای بیشتر درباره الگوریتمها بر روی تصویر زیر کلیک کنید.

مزایا و معایب الگوریتم SJF در سیستم عامل
الگوریتم SJF هم دارای مزایا و معایب مختص به خود است. برای استفاده از هر الگوریتمی باید مزایا و معایب آن را در نظر گرفت و با سایر الگوریتمهای موجود مقایسه کرد. در این صورت همیشه میتوانیم بهترین گزینه را برای پیادهسازی ساختار مورد نظر انتخاب کنیم.
در این بخش از مطلب مزایا و معایب الگوریتم SJF را بیان کردهایم.
مزایای الگوریتم SJF
در فهرست پایین، چند مورد از مهمترین مزایای استفاده از الگوریتم SJF را ذکر کردهایم.
- الگوریتم «اول، کوتاهترین کار» یا SJF، در مقایسه با الگوریتم «اولین ورودی، اولین خدمترسانی شده» یا FCFS میانگین زمان انتظار کوتاهتری دارد.
- الگوریتم SJF را میتوان برای کار زمانبندی به صورت طولانی مدت استفاده کرد.
- الگوریتم SJF برای کار با وظایفی که به صورت دستهای ارسال میشوند و زمان اجرای آنها از پیش مشخص شده، گزینه بسیار خوبی است.
- به احتمال زیاد، SJF بهترین الگوریتم برای کاهش میانگین زمان تکمیل فعالیت برای همه فرایندهاست.
معایب الگوریتم SJF
در فهرست پایین چند مورد از برجستهترین معایب استفاده از الگوریتم SJF را فهرست کردهایم.
- الگوریتم «اول، کوتاهترین کار» با افزایش زمان تکمیل فعالیت – بهخصوص برای فرایندهای بزرگ – میتواند باعث بروز گرسنگی در آن فرایندها شود.
- در الگوریتم SJF، زمان تکمیل فعالیت فرایند باید از قبل تعیین شده باشد. باید توجه داشت که بعضی از وقتها تعیین زمان تکمیل فعالیت، بسیار مشکل است.
- از آنجا که نمیتوان به صورت دقیق زمان تکمیل فعالیت فرایندها را بر روی CPU تعیین کرد، نمیتوان از SJF برای زمانبندیهای کوتاه مدت در CPU استفاده کرد.
- در الگوریتم SJF نمیتوان به فرایندها اولویت داد.
جمعبندی
در این مطلب از مجله فرادرس با الگوریتم SJF آشنا شدیم. در الگوریتم SJF یا «اول کوتاهترین کار»، اول از همه، CPU به فرایندی اختصاص داده میشود که کوتاهترین زمان تکمیل فعالیت را داشته باشد. بنابراین فرایندهای موجود در صف اجرای که زمان تکمیل کار کوتاهی دارند، با سرعت بالایی پردازش میشوند. میانگین زمان انتظار در این الگوریتم برای همه فرایندهای در حال انتظار در صف اجرا، به میزان چشمگیری کوتاهتر است. معمولا از الگوریتم SJF در سیستم عامل برای زمانبندی CPU استفاده نمیشود. زیرا تخمین زمان تکمیل فعالیت فرایندها پیش از اجرا بسیار مشکل است.
میتوان از الگوریتم SJF با هر دو رویکرد انحصاری و غیرانحصاری استفاده کرد. به الگوریتم SJF در حالت غیر انحصاری الگوریتم «اول کوتاهترین زمان باقیمانده» (Shortest Remaining Time First | SRTF) نیز گفته میشود. برای پیدا کردن کمترین زمان تکمیل فعالیت در میان همه فرایندهای رسیده به صف از «درخت بازهها» (Segment Trees) استفاده میشود.
source