فرض کنید دو مجموعه داده داریم که به نوعی با هم در ارتباط هستند. برای اینکه بتوانیم نوع این ارتباط را پیشبینی کنیم و آن را در قالب یک معادله ریاضیاتی یا یک نمودار نشان دهیم، باید بدانیم «رگرسیون» (Regression) چیست. رگرسیون به ما کمک میکند تا بفهمیم رابطه بین متغیرهای مختلف به چه صورت است. در رگرسیون دو نوع متغیر داریم، «متغیر مستقل» (Independent Variable) و «متغیر وابسته» (Dependent Variable). بین این دو نوع متغیر، یک رابطه علت و معلولی برقرار است، به این صورت که با تغییر یکی، دیگری تغییر خواهد کرد.


در این نوشته از مجله فرادرس ابتدا توضیح میدهیم که رگرسیون چیست و انواع متغیرهای آن به چه صورت است. سپس با توجه به نوع ارتباط بین متغیرها (خطی یا غیرخطی)، انواع مدلهای رگرسیون را معرفی میکنیم و معادلات حاکم بر هر کدام را توضیح میدهیم. همچنین با توجه به تعداد متغیرهای مستقل، با انواع رگرسیونهای ساده و چندگانه نیز آشنا خواهید شد.
رگرسیون چیست؟
رگرسیون یک روش تحلیل آماری است که از آن در اقتصاد، سرمایهگذاری و تجارت، به منظور تشخیص نوع ارتباط بین یک متغیر وابسته و یک یا چند متغیر مستقل استفاده میشود. همچنین میزان قدرت یا قوی بودن رابطه بین متغیرها میتواند در ارائه یک تحلیل و پیشبینی قوی بسیار کمککننده باشد. در رگرسیون تلاش بر این است که اثر یک یا چند متغیر روی متغیرهای دیگر بررسی و پیشبینی شود. برای مثال ممکن است یک سرمایهگذار دنبال این باشد که قیمت فولاد روی فروش ماشین چه اثری دارد. در این مثال آن متغیری که تاثیر میپذیرد، متغیر وابسته نام دارد، در حالی که متغیر دیگر، متغیر مستقل است.
رگرسیون انواع مختلفی دارد که مرسومترین و سادهترین نوع آن، «رگرسیون خطی ساده» (Simple Linear Regression) است. در رگرسیون خطی ساده، فقط یک متغیر مستقل داریم. اما زمانی که بیشتر از یک متغیر مستقل داشته باشیم، دیگر با رگرسیون خطی ساده مواجه نیستیم، بلکه رگرسیون از نوع «خطی چندگانه» (Multiple Linear Regression) است. یک نمونه رگرسیون خطی چندگانه، فروش ماشین است که در آن میزان علاقه مردم به سرعت، قیمت فولاد، قیمت نفت و درآمد ناشی از قیمت سهام متغیرهای مستقل مسئله هستند.
اگر بخواهیم در مورد کاربردهای رگرسیون صحبت کنیم، یک نمونه از کاربردهای آن در تعیین «همبستگی» (Correlation) و «کواریانس یا هم وردایی» (Covariance) است که از آن در سرمایهگذاریها زیاد استفاده میشود. روند کار به این صورت است که برای مثال، تعیین این دو پارامتر میتواند نشان دهد دو روند سرمایهگذاری چقدر در یک راستا پیش میروند. گفتیم در رگرسیون با دو نوع متغیر سروکار داریم. اینکه هر کدام چه تعدادی داشته باشند، مهم نیست، اما لازم است تمام متغیرهای مسئله بررسی شوند و در یکی از این دو گروه قرار بگیرند:
- متغیرهای مستقل
- متغیرهای وابسته
در ادامه ویژگیهای هر کدام از این دو نوع متغیر را توضیح خواهیم داد تا بهتر متوجه تفاوت آنها شوید.

متغیر وابسته چیست؟
ابتدا میخواهیم ببینیم متغیر وابسته در رگرسیون چیست. اغلب متغیر وابسته همان خروجی یا متغیر پاسخ مسئله ما است که میخواهیم علت تغییرات آن را بررسی کنیم و ببینیم چه عامل یا عواملی روی آن اثرگذار هستند. در واقع هدف از بررسی رگرسیون این است که تغییرات و رفتار متغیر وابسته را بفهمیم و پیشبینی کنیم.
متغیر مستقل چیست؟
پس از اینکه یاد گرفتیم متغیر وابسته چه خصوصیاتی دارد، تشخیص متغیر مستقل در رگرسیون چندان مشکل نیست. متغیر مستقل همان عامل یا عواملی هستند که علت ایجاد تغییرات بودهاند. به عبارت دیگر، متغیر مستقل همان علت و متغیر وابسته همان معلول است. متغیر مستقل ممکن است یک یا چند عدد باشد. در ادامه خواهید دید که بر مبنای تعداد متغیرهای مستقل، میتوانیم رگرسیون را به گروههای مختلفی تقسیمبندی کنیم. متغیر مستقل را پیشبینی کننده یا متغیر کمکی هم مینامند.
یادگیری مقدمات رگرسیون با فرادرس
پیش از اینکه به ادامه مطلب بپردازیم و ببینیم انواع رگرسیون چیست و چگونه تعریف میشود، در این قسمت قصد داریم چند فیلم آموزشی مرتبط با این موضوع از مجموعه فرادرس را به شما معرفی کنیم. با مشاهده این دورهها به تعاریف و محاسبات مرتبط با تحلیلهای رگرسیون کاملا مسلط خواهید شد و در نتیجه میتوانید به خوبی از آن در مباحث علوم انسانی یا در تحلیل مباحث اقتصادی بهره بگیرید:

- فیلم آموزش رایگان رگرسیون فرادرس
- فیلم آموزش رایگان رگرسیون خطی ساده فرادرس
- فیلم آموزش آمار و احتمال مهندسی فرادرس
- فیلم آموزش رگرسیون ۱ – رگرسیون خطی فرادرس
- فیلم آموزش رگرسیون ۲ فرادرس
- فیلم آموزش رایگان کاربرد رگرسیون و همبستگی در آمار استنباطی برای مدیریت و علوم انسانی فرادرس
- فیلم آموزش آمار استنباطی برای مدیریت و علوم انسانی فرادرس
- فیلم آموزش رایگان آموزش تعریف اقتصاد سنجی فرادرس
- فیلم آموزش اقتصاد سنجی فرادرس
رگرسیون خطی چیست؟
برای اینکه بهتر متوجه شویم رگرسیون چیست، لازم است بار دیگر به تعریف آن بازگردیم. گفتیم در رگرسیون با دو گروه متغیر سروکار داریم که تعداد آنها ممکن است روند بررسی ما را متفاوت کند. همچنین عامل دیگری که در نوع رگرسیون مهم است، نوع ارتباط متغیرهای مستقل و وابسته با هم است.
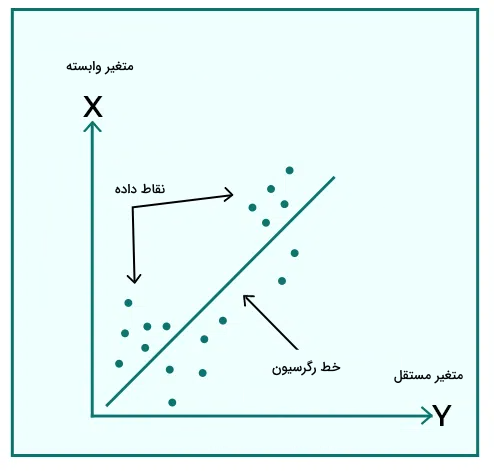
گاهی ارتباط بین متغیرهای مستقل و وابسته، یک ارتباط خطی است، یعنی با افزایش یا کاهش متغیر مستقل، متغیر وابسته هم افزایش یا کاهش دارد. پس نوع وابستگی متغیرها میتواند تعیینکننده نوع رگرسیون باشند. اگر ارتباط بین متغیرهای وابسته و مستقل خطی باشد، در این صورت رگرسیون ما از نوع خطی است و «خط رگرسیون» (Regression Line) داریم. در رگرسیون خطی نکته مهم این است که بهترین خط مستقیم را جهت توصیف نوع ارتباط دادههای خود پیدا کنیم. در مثال زیر بهتر متوجه خواهید شد که چگونه میتوانیم دادههای خود را در قابل یک نمودار نقطهای نمایش دهیم.
مثال رگرسیون خطی
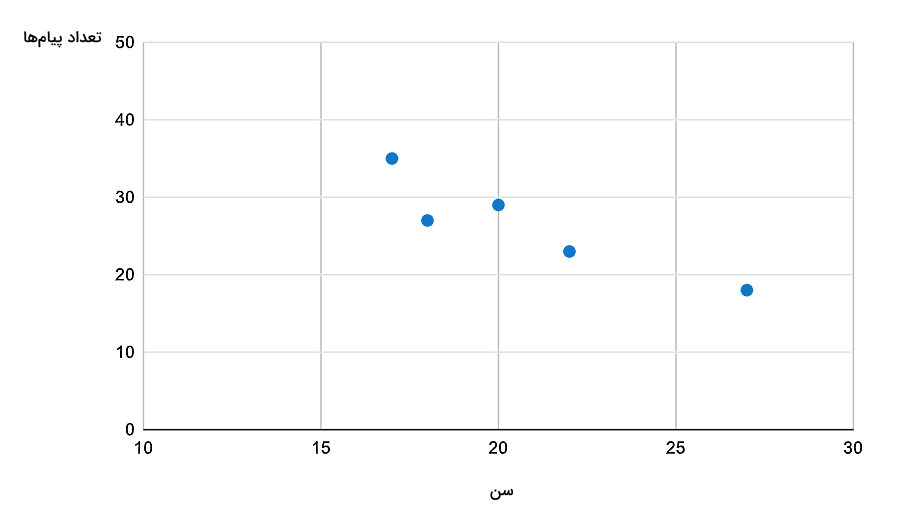
فرض کنید قصد دارید میزان اعتیاد افراد به تلفن همراه را بررسی کنید و در کلاس هنر خود، از ۵ نفر سوال میکنید که در طول این کلاس چند عدد پیام ارسال کردهاند. همچنین اگر سن این ۵ نفر را در یک ستون از جدولی به شکل زیر و بهترتیب از کمتر به بیشتر وارد کنید، با نوشتن تعداد پیامهای هر شخص در کنار سن، حالا میتوانید بررسی کنید که آیا بین سن افراد و تعداد پیامهای ارسال شده ارتباطی وجود دارد یا خیر؟ اگر جواب مثبت است، آیا این ارتباط خطی است؟ چگونه میتوانید معادله ریاضیاتی حاکم بر این ارتباط را پیدا کنید؟
| سن | تعداد پیامهای ارسال شده |
| ۱۷ | ۳۵ |
| ۱۸ | ۲۷ |
| ۲۰ | ۲۹ |
| ۲۲ | ۲۳ |
| ۲۷ | ۱۸ |
جهت پاسخدهی به سوالات بالا، میتوانید نمودار نقطهای زیر را بر اساس جدول بالا رسم کنید. در نگاه اول، ممکن است بنظر برسد برای توصیف ارتباط خطی بین این متغیرها میتوانیم چند خط مختلف انتخاب کنیم. اما بهترین انتخاب خطی است که از سه نقطه اول، سوم و چهارم میگذرد. پس از مطالعه بخش «مدل رگرسیون خطی چیست؟»، معادله این خط را بهدست میآوریم و آن را رسم میکنیم.
پیش از اینکه به ادامه مبحث رگرسیون خطی بپردازیم، اگر علاقهمندید اطلاعات خود را در زمینه تحلیل رگرسیون با نرمافزار SPSS افزایش دهید، پیشنهاد ما این است که فیلم آموزشی تحلیل های رگرسیونی با اس پی اس اس SPSS فرادرس را مشاهده کنید. لینک این دوره آموزشی از مجموعه فرادرس را در ادامه برای شما قرار دادهایم:
انواع رگرسیون خطی چیست؟
در بخش های قبل یاد گرفتیم رگرسیون چیست و ارتباط چه نوع متغیرهایی را بررسی میکند. در این بخش با انواع رگرسیون خطی آشنا میشویم تا بهتر متوجه شویم در شرایطی که تعداد متغیرهای مستقل بیشتر از یک عدد بود و دادهها خطی بودند، چگونه عمل کنیم. انواع رگرسیون خطی عبارتاند از:
- رگرسیون خطی ساده
- رگرسیون خطی چندگانه
- رگرسیون لجستیک یا Logistic
- رگرسیون ترتیبی یا Ordinal
- رگرسیون چند جملهای یا Multinomial
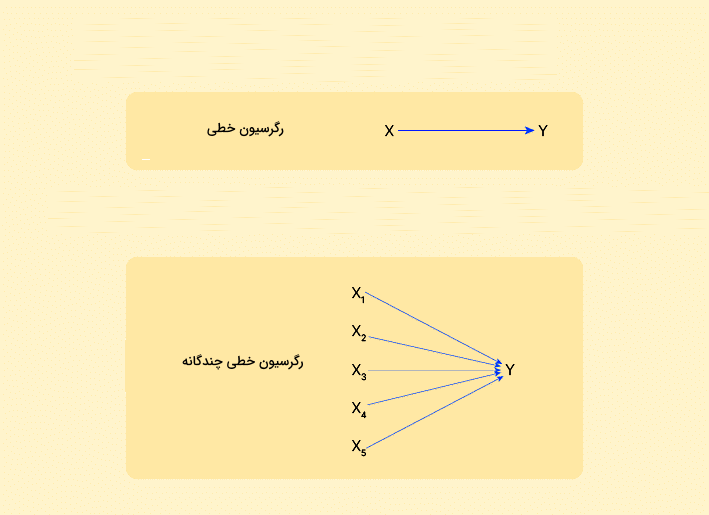
در ادامه مشخصات هر کدام از این گروهها را توضیح میدهیم.
رگرسیون خطی ساده چیست؟
اگر متغیر مستقل را X و متغیر وابسته را Y در نظر بگیریم، در رگرسیون خطی ساده فقط یک X و یک Y داریم که یک رابطه خطی با هم دارند. بهعبارت دیگر، در رگرسیون خطی ساده فقط به یک عدد متغیر مستقل X نیاز داریم تا خروجی تک متغیر وابسته Y را توضیح دهیم. بهترین توصیف برای چنین وضعیتی فرمول زیر است که همان معادله خط راست در ریاضیات است و نشان میدهد نوع خطی ساده رگرسیون چیست:
- Y: متغیر وابسته
- X: متغیر مستقل
- a: عرض از مبدا یا intercept
- b: شیب یا slope
- u: باقیمانده رگرسیون
در این رابطه Y همان متغیری است که تلاش میکنیم رفتار آن را پیشبینی کنیم. در مقابل، X متغیری است که برای پیشبینی رفتار Y از آن استفاده میکنیم. اگر خط مستقیم محور y را قطع کند، مقدار Y برابر با b خواهد شد. برای مثال، اگر قد را بهعنوان تنها عامل تعیینکننده وزن در نظر بگیریم، در این شرایط رگرسیون خطی میتواند در پیشبینی یا توضیح اثر تغییرات قد روی وزن، به ما کمک کند.
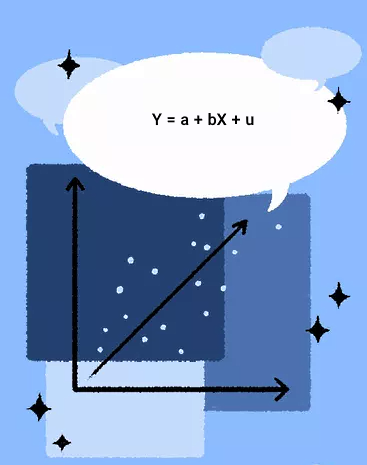
مثال رگرسیون خطی ساده
در این بخش با توضیح یک مثال کوچک متوجه خواهید شد که منظورمان از رابطه خطی در رگرسیون چیست. فرض کنید قیمت هر کیلوگرم منگو در آمریکا برابر با ۱٫۸ دلار باشد، در این صورت قیمت ۲ کیلوگرم منگو معادل است با ۳٫۶ دلار. همانطور که احتمالا شما هم در ذهن خود بهراحتی این نسبت را محاسبه کردید، بین قیمت و وزن منگو یک رابطه مشخص و خطی وجود دارد که میتوانیم آن را در قابل معادله زیر بنویسیم:
یعنی متغیر مستقل ما X یا وزن منگو است و متغیر وابسته یا Y قیمت است. بنابراین قیمت منگو بر اساس وزن آن و بهصورت بالا مشخص میشود.
رگرسیون خطی چندگانه چیست؟
اگر متغیر مستقل را X و متغیر وابسته را X در نظر بگیریم، در رگرسیون خطی چندگانه دو یا چند X و فقط یک Y داریم که رابطه هر کدام از Xها با Y، یک رابطه خطی است. پس در رگرسیون خطی چندگانه از دو یا چند متغیر مستقل X برای توضیح خروجی تک متغیر وابسته Y استفاده میشود. فرمولی که برای توصیف رگرسیون خطی چندگانه بکار میرود، بهصورت زیر است:
- Y: متغیر وابسته
- : متغیرهای مستقل
- a: عرض از مبدا یا intercept
- : شیب یا slope
- u: باقیمانده رگرسیون یا خطا
در حقیقت وقتی که برای توضیح عوامل مختلف موثر روی خروجی تک متغیر وابسته ما، رگرسیون خطی ساده کافی نباشد، از رگرسیون خطی چندگانه استفاده میکنیم. اگر مثال بخش قبل در مورد ارتباط قد و وزن را در نظر بگیریم، میدانیم که در واقعیت، وزن فقط به قد بستگی ندارد. بلکه عوامل مختلفی وزن افراد را تعیین میکند، از جمله نوع تغذیه، ورزش، بیماری و …. پس برای اینکه بتوانیم در مورد متغیر وابسته وزن و عوامل موثر روی آن توصیف دقیقتری ارائه کنیم، لازم است از یک مدل رگرسیون واقعیتر مانند رگرسیون خطی چندگانه استفاده کنیم. اصولا در مدلهای واقعی، تعداد متغیرهای مستقل X بیشتر از یک عدد است.
رگرسیون لجستیک چیست؟
این نوع رگرسیون زمانی بکار میرود که با دادههای دوتایی یا دو حالته مانند اینکه آیا شخصی روی یک گزینه خاص موردنظر ما کلیک میکند یا خیر، مواجه هستیم.
رگرسیون ترتیبی چیست؟
گاهی اوقات مسئلهای که به دنبال پیشبینی آن هستیم ماهیت عددی ندارد، بلکه بهصورت منظم، رتبهای یا ترتیبی است. برای مثال، زمانی که به محصولی از یک تا پنج امتیاز میدهید. این نوع رگرسیون به ما کمک میکند تا چنین خروجیهای رتبهبندی شدهای را پیشبینی کنیم.
رگرسیون چند جملهای چیست؟
در نهایت میخواهیم بررسی کنیم در این مطلب آخرین نوع خطی رگرسیون چیست و چگونه تعریف میشود. چنانچه خروجیهای ما در طبقهبندیهای مختلفی که دارای ترتیب مشخصی نباشند، قرار بگیرند، در این صورت باید از رگرسیون چند جملهای استفاده کنیم. برای مثال پیشبینی اینکه رنگ موردعلاقه یک نفر در میان چند رنگ موردنظر کدام است.
ضریب همبستگی چیست؟
در یکی از مثالهای بخشهای قبل گفتیم برای اینکه متوجه شویم آیا دو مجموعه داده بهصورت خطی با هم در ارتباط هستند یا نه، بهتر است نمودار نقطهای آنها را رسم کنیم و روند قرارگیری دادهها در کنار هم را بررسی کنیم. یکی از راههای تشخیص خطی بودن رابطه بین دادهها این است که «ضریب همبستگی پیرسون» (Pearson Correlation Coefficient) یا همان ضریب همبستگی را محاسبه کنیم.
با در نظر گرفتن متغیرهای x و y بهترتیب به صورت متغیر مستقل و وابسته، اگر μx و sx بهترتیب برابر باشند با مقدار میانگین و انحراف معیار نمونه x و μy و sy بهترتیب برابر باشند با مقدار میانگین و انحراف معیار نمونه y، ضریب همبستگی r توسط رابطه زیر محاسبه میشود:
که در آن n اندازه نمونه است. همچنین مقادیر zx و zy برابر هستند با:
ضریب همبستگی ویژگیهای خاصی دارد که با دانستن آنها میتوانیم تشخیص دهیم بهطور مثال، آیا همبستگی مثبت است یا نه. این ویژگیها شامل موارد زیر هستند:
- مقادیر ضریب همبستگی همواره بین ۱- تا ۱ است.
- اگر باشد، در این صورت رابطه بین متغیرهای x و y کاملا خطی است.
- اگر r = ۰ باشد، در این صورت هیچ رابطه خطی بین متغیرهای x و y وجود ندارد.
- اگر r › ۰ باشد، چنانچه x زیاد شود، y هم به سمت زیاد شدن پیش میرود و اگر x کم شود، y نیز متمایل به کاهش است (همبستگی مثبت)
- اگر r ‹ ۰ باشد، چنانچه x زیاد شود، y به سمت کم شدن پیش میرود و اگر x کم شود، y متمایل به افزایش است (همبستگی منفی)

همچنین فرضیاتی که لازم است در مورد رگرسیون خطی چک شوند، شامل موارد زیر است:
- کمی بودن متغیرها: همبستگی زمانی اعمال میشود که هر دو متغیر مورد بررسی ما کمی باشند.
- خط مستقیم: با توجه به نمودار نقطهای مشخص است که دادههای شما قابل توصیف با رابطه خطی هستند. در این صورت همبستگی فقط میزان یا قدرت این خطی بودن را میسنجد.
- دادههای پرت: وجود دادههای پرت باعث میشود همبستگی کم شود. بنابراین در شرایطی که دادههای پرت در مسئله وجود دارند، بهترین راهکار این است که یک همبستگی با وجود دادههای پرت و یک همبستگی بدون در نظر گرفتن این دادهها محاسبه شود.
در بخش بعد با حل مثال نشان میدهیم چگونه میتوان ضریب همبستگی را در مثال ارتباط ارسال پیام و سن محاسبه کرد.
مثال ضریب همبستگی
برای اینکه در مثال بخش قبل بتوانیم تحلیل درستتری داشته باشیم، یک راه این بود که نمودار نقطهای را بررسی کنیم و بهترین خط مستقیم توصیف کننده رابطه بین دادهها را پیدا کنیم. راه دیگر این است که ضریب همبستگی را پیدا کنیم که در این بخش این روش را بررسی خواهیم کرد. ابتدا فرمول بخش قبل را مینویسیم:
سپس فرضیات خود را بهصورت زیر در نظر میگیریم:
- متغیر مستقل x: سن
- متغیر وابسته y: تعداد پیامهای ارسال شده
مرحله بعدی این است که مقادیر میانگین و انحراف معیار را برای هر متغیر جداگانه محاسبه کنیم و آنها را در روابط زیر قرار دهیم:
میدانیم فرمول محاسبه میانگین برای متغیر x و y بهصورت زیر است:
| x یا سن | y یا تعداد پیامهای ارسال شده |
با در نظر گرفتن جدول بالا بهعنوان دادههای مسئله، خواهیم داشت:
حالا میرویم سراغ محاسبه انحراف معیار با روابط زیر:
برای اینکه فرمولهای بالا را بهتر درک کنید، قدم به قدم پیش میرویم. ابتدا هر مقدار x یعنی متغیر سن را از میانگین آن کم میکنیم. برای مثال در مورد اولین مقدار یعنی عدد ۱۷، حاصل بهصورت زیر است:
به این ترتیب برای سایر مقادیر خواهیم داشت:
در مرحله بعد مقادیر بهدست آمده را به توان دو میرسانیم و نتایج را با هم جمع میکنیم:
با قرار دادن مقدار بالا در فرمول sx و با توجه به اینکه n-۱ برابر است با ۴، خواهیم داشت:
همین روند را برای متغیر y نیز تکرار میکنیم:
قدم بعدی محاسبه مقادیر zx است که طبق جدول زیر بهدست میآید:
| x یا سن | ||
اگر برای zy هم همین روند تکرار شود، حاصل به شکل زیر است:
| y یا تعداد پیامهای ارسال شده | |
حالا میتوانیم از فرمول ضریب همبستگی بهراحتی استفاده کنیم، کافی است مقادیر بالا را در آن قرار دهیم:
ضریب همبستگی منفی شد. پس همبستگی منفی است، یعنی میتوانیم این پیشبینی را بر اساس این آزمایش داشته باشیم که با افزایش سن تعداد پیامهای ارسال شده کم خواهد شد. همچنین مقدار ضریب همبستگی به یک نزدیک است اما برابر با یک نیست. پس با اینکه نوع ارتباط دادههای ما کاملا خطی نیست، اما مدل رگرسیون خطی انتخاب کاملا مناسبی برای توصیف و تحلیل این آزمایش است.
رگرسیون غیرخطی چیست؟
آموختیم نوع خطی رگرسیون چیست و ارتباط متغیرها در آن چگونه است. در این بخش به بیان ویژگیهای رگرسیون غیرخطی میپردازیم. در رگرسیون غیرخطی رابطه بین متغیرهای مستقل و وابسته بهصورت سر راست و یک خط مستقیم نیست، بلکه به شکل پیچیدهتری و در قالب یک منحنی است.
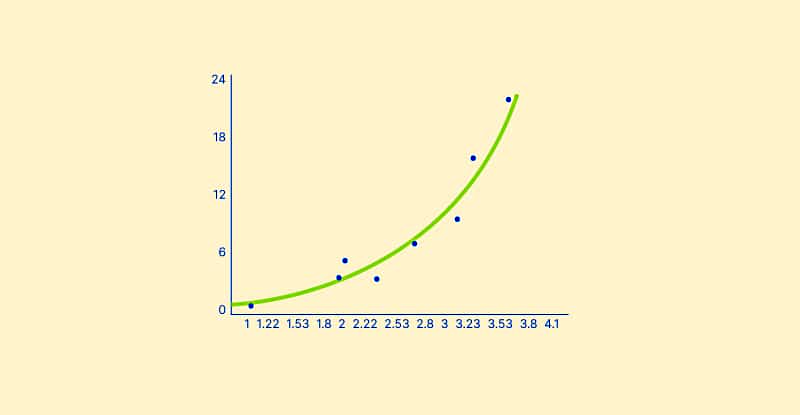
در مورد رگرسیون غیرخطی، ممکن است معادله خط رگرسیون به شکل باشد که یک معادله درجه ۲ است و گاهی معادلات درجه بالاتر را نیز شامل میشود.
مدل رگرسیون چیست و چه انواعی دارد؟
در بخشهای قبل آموختیم انواع رگرسیون چیست. در این بخش به بررسی مدلهای رگرسیون خواهیم پرداخت که در حقیقت بر پایه انواع رگرسیون تقسیمبندی شدهاند. در یک مدل رگرسیون، تابعی معرفی میشود که توصیفکننده رابطه بین متغیرهای مستقل و متغیرهای وابسته است. به این ترتیب با فرمولبندی کردن رگرسیون، میتوانیم پیشبینی دقیقتری روی آثار متغیرهای مستقل روی متغیر وابسته ارائه کنیم.
برای مثال، اگر رابطه بین قد و سن هر نفر در بازه سنی یک تا بیست سال را در نظر بگیرید، با افزایش سن افراد، قد آنها نیز زیاد میشود. پس رابطه بین قد و سن در این بازه، یک رابطه خطی است و میتوانیم این ارتباط خطی را با یک مدل رگرسیون خطی توصیف کنیم. رگرسیون مدلهای مختلفی دارد که در چهار گروه طبقهبندی میشوند:
- رگرسیون خطی (Linear Regression)
- رگرسیون غیرخطی (Non-linear Regression)
- رگرسیون چندگانه (Multiple Regression)
- رگرسیون گام به گام (Stepwise Regression)
در ادامه پس از توضیح و بررسی مثال، با هر کدام از این مدلها بیشتر آشنا خواهیم شد.
مدل رگرسیون خطی چیست؟
یک مدل رگرسیون خطی جهت به تصویر کشیدن و توصیف رابطه بین متغیرهایی بهکار میرود که به نوعی با هم متناسب هستند، به این معنا که متغیر وابسته با کم یا زیاد شدن متغیر مستقل، کم یا زیاد میشود. بنابراین نمودار مدل رگرسیون خطی به شکل یک خط مستقیم است.

این خط از کنار هم قرار دادن نقاط مختلف بهعنوان داده حاصل میشود، هر چند ممکن است این نقاط دقیقا روی یک خط قرار نگیرند، اما اگر نزدیک به یک خط مستقیم باشند با تقریب میتوان این الگو را برای مدل رگرسیون خطی در نظر گرفت. برای مثال، اگر سن شخصی زیاد شود، سطح گلوکز در بدن آن شخص نیز افزایش مییابد. بنابراین این گزاره را میتوانیم با مدل رگرسیون خطی و در قالب یک نمودار با خط مستقیم توصیف کنیم.
با مفهوم خط رگرسیون در بخشهای قبل آشنا شدهایم. خط رگرسیون همیشه یک خط بدون نقص و کاملی که شامل تمام دادهها یا نقاط باشد، نیست. بنابراین طبیعی است که پس از رسم نمودار، نقاطی داشته باشیم که روی این خط قرار ندارند. ممکن است برخی نقاط بالاتر و برخی زیر این خط قرار بگیرند. اما بهترین حالت که در آن «مجموع مربعات باقیماندهها» (Sum of Squares of the Residuals) برابر با کمترین مقدار ممکن میشود، در همین شرایط است.
محاسبات برای یافتن خط رگرسیون اغلب وقتگیر است. به همین دلیل از نرمافزارهای آماری استفاده میشود. خط رگرسیونی که بیشترین میزان مچشدگی با دادهها را دارد، «خط رگرسیون حداقل مربعات» (Least Square Regression Line) نامیده میشود و معادله آن به شکل زیر است:
که در آن داریم:
و
در بخشهای قبل فرم سادهتر این معادله که همان معادله خط راست بود را بررسی کردیم. اما اگر بخواهیم بررسی دقیقتری داشته باشیم، لازم است معادله بالا را بهعنوان خط رگرسیون در نظر بگیریم که در آن به معنای مقدار پیشبینی شده y است و با جایگزینی مقدار ویژه x در معادله بالا بهدست خواهد آمد. چون فقط یک پیشبینی است، اختلاف بین و مقدار واقعی y، باقیمانده یا residual نامیده میشود:
در بخشهای بعدی با حل چند مثال و تمرین، با مفهوم باقیمانده و روش استفاده از معادله خط رگرسیون بهتر آشنا خواهید شد.
مدل رگرسیون غیرخطی چیست؟
در بخش قبل یاد گرفتیم نوع خطی رگرسیون چیست و دیدیم که در این مدل، رابطه خیلی سادهای بین متغیرها برقرار است. اما اگر رابطه بین متغیرهای مختلف پیچیدهتر باشد، نمیتوانیم از مدل رگرسیون خطی برای توصیف این ارتباط استفاده کنیم. در این شرایط استفاده از مدل رگرسیون غیرخطی میتواند به ما کمک کند.
در این مدل برخلاف یک خط مستقیم، نوع ارتباط بین متغیرها توسط یک تابع غیرخطی توصیف میشود. البته چنین تابعی ممکن است دارای پارامترهای مختلفی باشد که لازم است با توجه به دادههای جمعآوری شده و تحلیل آماری، آنها را تخمین بزنید. بنابراین روند مدل کردن رابطه بین متغیرها در این مدل نسبت به مدل خطی، پیچیدهتر است. این مدل معمولا زمانی مفید است که رابطه بین متغیرها را با یک مدل خطی نمیتوانید به تصویر بکشید.
مدل رگرسیون چندگانه چیست؟
یک مدل رگرسیون چندگانه زمانی به کار میرود که بیشتر از یک متغیر مستقل در مسئله خود داشته باشیم. در این شرایط در حالی که باید خروجی را پیشبینی کنیم، مهم است که به نحوه تغییرات یا پیشروی متغیرهای مستقل در محیط و اینکه تغییرات آنها چه تاثیری روی خروجی میگذارد، دقت کنیم. برای نمونه، شانس اینکه دانشآموزان در یک آزمون موفق نشوند، به عوامل مختلفی مثل میزان پشتکار و تمرین، شرایط خانواده، وضعیت سلامتی و … وابسته است. اگر در این زمینه نیاز دارید اطلاعات بیشتری کسب کنید، در مطلب «رگرسیون چندگانه در SPSS — راهنمای کاربردی» از مجله فرادرس این نوع رگرسیون و نحوه کار با آن در نرمافزار SPSS آموزش داده شده است.
مدل رگرسیون گام به گام چیست؟
برخلاف مدلهای رگرسیونی که در بخشهای قبل توضیح داده شد، مدل رگرسیون گام به گام زمانی بکار میرود که متغیرهای ورودی مختلفی داریم که روی یک متغیر خروجی اثر میگذارند. در چنین وضعیتی تحلیلگر متغیری را انداره میگیرد که مستقیما به متغیر خروجی مرتبط است و به این ترتیب مدلی را بر این اساس میسازد. بقیه متغیرها زمانی در نظر گرفته میشوند که او بخواهد مدل کاملی ارائه دهد.

ممکن است تحلیلگر ورودیهای باقیمانده را یکی پس از دیگری بر اساس میزان اهمیت و اینکه چقدر روی هدف تاثیرگذاراند، اضافه کند. برای مثال، فرض کنید قیمت سبزیجات در مناطق خاصی افزایش یافته است. علت این مسئله ممکن است موارد مختلفی باشد، از جمله تغییرات آب و هوایی یا تغییرات در سیستم حمل و نقل یا مدیریت زنجیره تامین. در چنین شرایطی زمانی که تحلیلگر میخواهد این عوامل را بررسی کند و مدلی ارائه دهد، واضحترین یا محتملترین علت را انتخاب میکند، برای مثال بارش شدید باران در مناطق کشاورزی. به محض اینکه مدل ساخته شد، میتواند باقی دلایل یا عوامل موثر را بر اساس اهمیت و میزان رخداد آنها به مدل خود اضافه کند.
حل مثال و تمرین مدل رگرسیون خطی
در این بخش با حل چند مثال به شما نشان میدهیم که چگونه میتوان معادله خط رگرسیون را محاسبه کرد و به این ترتیب، درک بهتری نسبت به این موضوع بهدست خواهید آورد که رگرسیون چیست. همچنین در انتها دو تمرین برای شما در نظر گرفتهایم که با پاسخدهی به آنها میتوانید دانش خود را در مورد این مبحث بیازمایید.
مثال ۱
اگر مجددا به مثال ارسال پیام در بخشهای قبل بازگردیم، معادله خط رگرسیون حداقل مربعات بهصورت زیر میشود:
در ادامه نشان میدهیم چگونه این معادله بهدست میآید. برای نوشتن معادله خط رگرسیون حداقل مربعات، اولین قدم این است که مقدار b را پیدا کنیم و سپس از آن برای محاسبه a استفاده کنیم:
| y یا تعداد پیامهای ارسال شده | |
| x یا سن | |
حالا با داشتن مقادیر a و b معادله خط رگرسیون بهصورت زیر نوشته میشود:
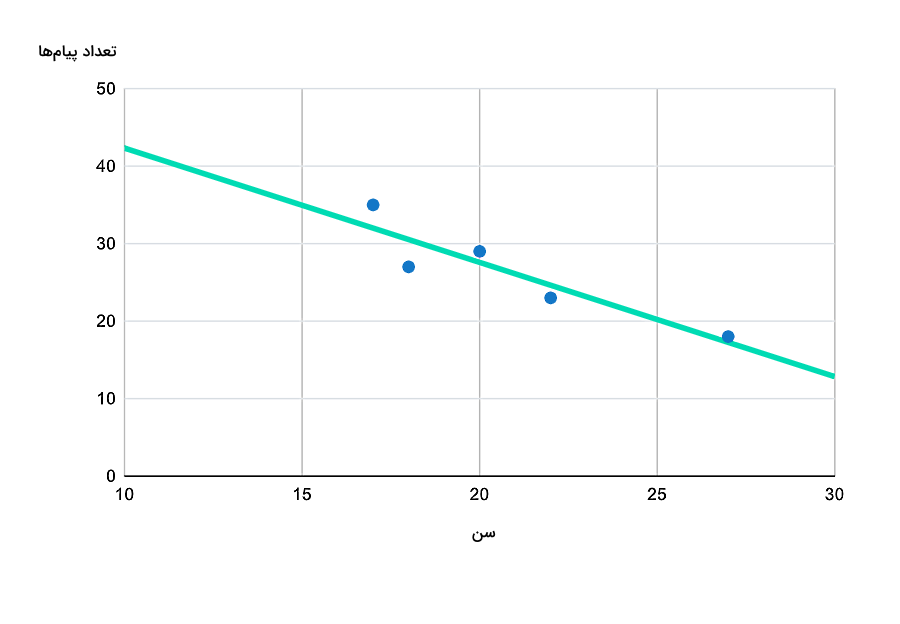
بنابراین با داشتن معادله خط رگرسیون حداقل مربعات میتوانید خط رگرسیون را مطابق شکل بالا رسم کنید. همچنین با استفاده از این معادله شما میتوانید پیشبینی کنید که برای مثال، چه تعداد پیام توسط یک شخص ۲۵ ساله ممکن است ارسال شود:
دقت کنید در مدل رگرسیون خطی باید توجه کنیم پیشبینیهای انجام شده فقط در مورد مقادیری از x است که در دامنه مقادیر ممکن برای x قرار میگیرند. در مورد این مثال نمیتوانیم بگوییم تعداد پیامهای ارسال شده توسط یک بچه یک ساله تقریبا برابر با ۵۵ عدد است! چرا که چنین محدوده سنی جزء دامنه بررسی این مسئله نیست.
مثال ۲
در این مثال قصد داریم ببینیم اثر دادههای پرت روی رگرسیون چیست، این دادهها باعث میشوند خط رگرسیون چقدر تغییر کند و در چنین شرایطی چه انتخابی بهتر است. فرض کنید نمودار نقطهای شکلهای زیر بیانگر نمراتی است که ۲۰ دانشآموز در امتحان ریاضی کسب کردهاند. همچنین تعداد ساعات مطالعه برای هر نمره نیز جمعآوری شده است. در واقع میخواهیم ببینیم ارتباط بین نمرات کسب شده و میزان مطالعه بر حسب ساعت چیست.
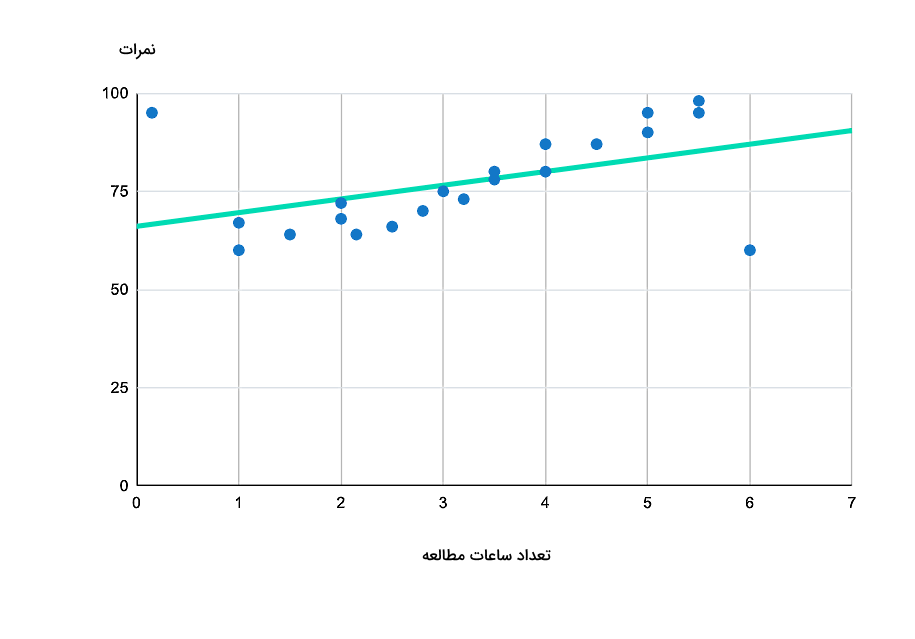
در این نمودار همانطور که مشاهده میکنید، رگرسیون خطی با در نظر گرفتن تمام دادهها از جمله دادههای پرت محاسبه شده و خط رگرسیون آن رسم شده است. اما در نمودار زیر، از دادههای پرت صرفنظر شده است. در واقع دانشآموزی که به مدت ۱۵ دقیقه و ۹۵ ثانیه مطالعه داشته است (اولین نقطه از سمت چپ) و دانشآموز دیگری که به مدت ۶ ساعت مطالعه کرده است (اولین نقطه از سمت راست)، از این بررسی حذف شدهاند.
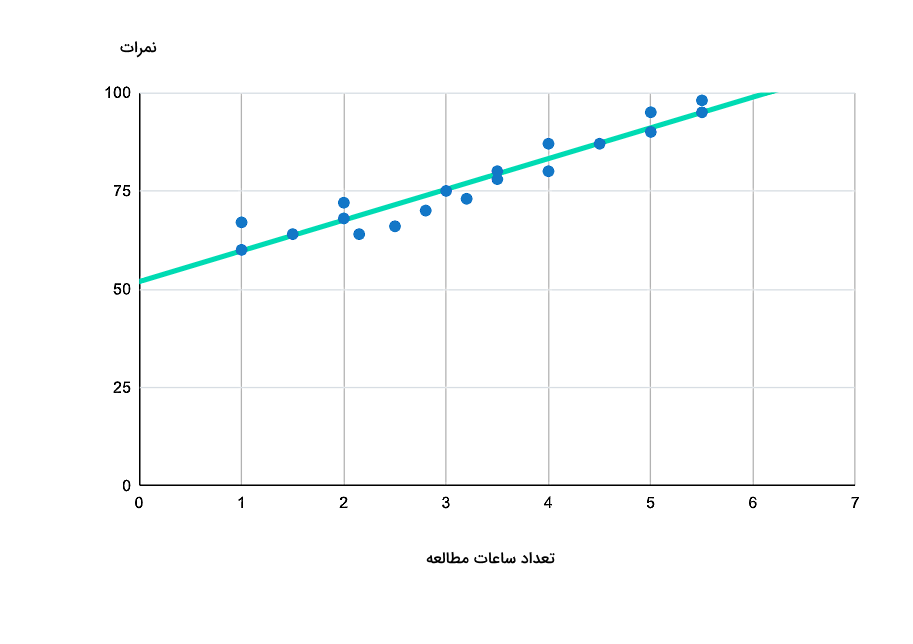
حالا سوال این است که کدام خط توصیف و پیشبینی دقیقتری به ما میدهد؟ پاسخ این است که در نمودار اول با در نظر گرفتن دادههای پرت، دادههای زیادی داریم که از خط رگرسیون دورتر قرار گرفتهاند. اما در تصویر دوم با حذف دو داده پرت، اغلب دادهها به خط رگرسیون نزدیکتر هستند. بنابراین خط دوم با دادههای ما بیشتر فیت است و کاربرد آن بهعنوان خط رگرسیون انتخاب دقیقتری خواهد بود.
مثال ۳
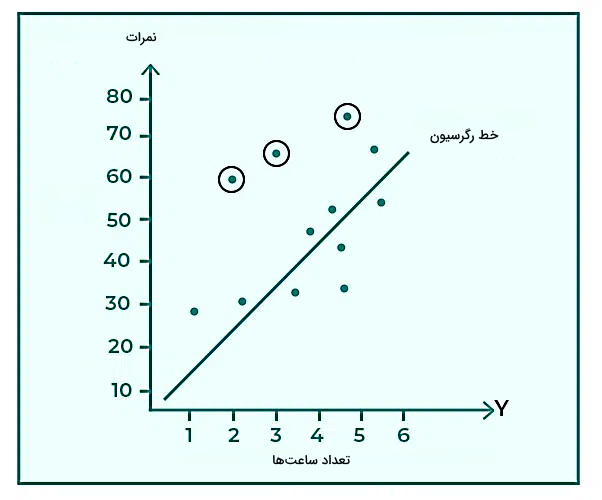
فرض کنید معادله خط رگرسیون همان تابعی است که نمرات هر شخص را بر اساس میزان ساعتهای مطالعهاش مشخص میکند. اگر شیب و عرض از مبدا این خط بهترتیب برابر با مقادیر ۵ و ۵۰ باشند،
- معادله خط رگرسیون را بنویسید:
- فرض کنید دانشآموز شماره ۱ نمره ۶۰ را با ۲ ساعت مطالعه و دانشآموز شماره ۲، نمره ۶۵ را با ۳ ساعت مطالعه کسب کرده باشند، اگر دانشآموز شماره ۴ به مدت ۵ ساعت مطالعه کرده باشد، چه نمرهای دریافت میکند؟
- خط رگرسیون را رسم کنید.
در مورد اولین بخش، با توجه به اینکه مقدار شیب و عرض از مبدا مشخص است، بهراحتی میتوانیم معادله خط را بنویسیم. با توجه به اینکه داشتیم:
- Y: متغیر وابسته
- X: متغیر مستقل
- a = ۵۰
- b = ۵
در نتیجه خواهیم داشت:
در مورد سوال بعدی، از معادله بخش قبل استفاده میکنیم. برای چهارمین دانشآموز که به مدت ۵ ساعت مطالعه کرده است، X = ۵ است. پس برای پیدا کردن Y یا نمره این دانشآموز، کافی است از معادله خط رگرسیون استفاده کنیم و مقدار ۵ را در آن بهجای X قرار دهیم تا Y برای این مقدار بهدست آید:
در آخرین مرحله، رسم نمودار نقطهای بر اساس نقاط مربوط به هر داده و خط رگرسیون را داریم که شکل زیر حاصل خواهد شد:
تمرین ۱
معادله رگرسیون خطی برای دادههای زیر برابر با کدام گزینه است؟
گزینه اول صحیح است. برای نوشتن معادله خط رگرسیون در این سوال، از فرمول زیر استفاده میکنیم:
اما برای محاسبه b لازم است ابتدا مقادیر میانگین x و y یا μx و μy تعیین شوند:
بنابراین با در نظر گرفتن n = ۴، خواهیم داشت:
حالا میتوانیم b را بهدست آوریم:
حالا با داشتن b محاسبه a نیز با فرمول زیر امکانپذیر است:
بنابراین با قرار دادن مقادیر a و b در معادله خط خواهیم داشت:
تمرین ۲
با توجه به دادههای زیر، شیب خط رگرسیون چقدر است؟
گزینه سوم درست است. برای بهدست آوردن شیب خط رگرسیون، کافی است فرمول b را بنویسیم و از دادههای صورت سوال استفاده کنیم:
دقت کنید برای اینکه بتوانیم از این فرمول استفاده کنیم، باید مقادیر میانگین و مقدار دادههای x و y را داشته باشیم. پیدا کردن μx و μy با فرمولهای زیر امکانپذیر است اما در نهایت باز هم مقادیر x و y را نداریم.
اگر فرمولهای بالا را در b قرار دهیم، خواهیم داشت:
حالا عبارت بالا را ساده میکنیم:
در نهایت به رابطه زیر میرسیم:
روش حداقل مربعات چیست؟
در بخشهای قبل پس از اینکه تعریف کردیم رگرسیون چیست و چه انواعی دارد، در قسمت رگرسیون خطی به خط رگرسیون حداقل مربعات اشاره کردیم. در این بخش میخواهیم این مبحث را دقیقتر بررسی کنیم. منحنی مورد بررسی در این روش همان خط رگرسیون است و هدف از کاربرد آن این است که مجموع مربعات خطاها را تا حد امکان کاهش دهیم. به همین دلیل این روش با حداقل مربعات نامگذاری شده است.
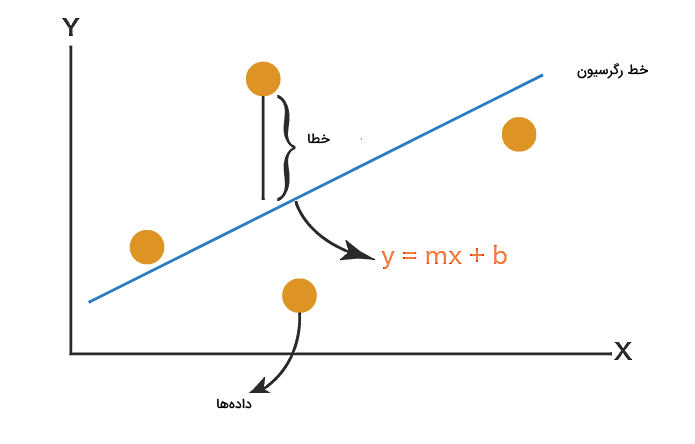
برای مثال در تصویر بالا چهار نقطه یا چهار داده داریم که با کاربرد این روش، خط رگرسیون بهصورتی که مشاهده میکنید، رسم شده است. اما این روش هم دارای محدودیتهایی است که عبارتاند از:
- این روش تنها برای نشان دادن ارتباط بین دو متغیر بکار میرود. در حقیقت بقیه علتها یا آثار در نظر گرفته نمیشوند.
- اگر دادهها به شکل یکنواختی توزیع نشده باشند، این روش چندان قابل اعتماد نیست.
- در این روش دادههای پرت بسیار موثر هستند و باعث خمیدگی نتایج تحلیل حداقل مربعات خواهند شد.
برای اینکه بهتر متوجه شوید این روش چگونه کار میکند، به تصویر زیر دقت کنید. خط مستقیم نشاندهنده نوع رابطه بین متغیرهای مستقل و وابسته است. هر چه باقیماندهها در این شکل کمتر باشند، مدل ما بهتر فیت شده است. به همین دلیل لازم است دادهها با کاهش باقیماندههای هر نقطه نسبت به خط رگرسیون، به حداقل مقدار ممکن خود برسند. فرض کنید نقاط دادههای ما به صورت زیر باشند:
که در آن تمام xها متغیر مستقل هستند و تمام yها متغیر وابسته.
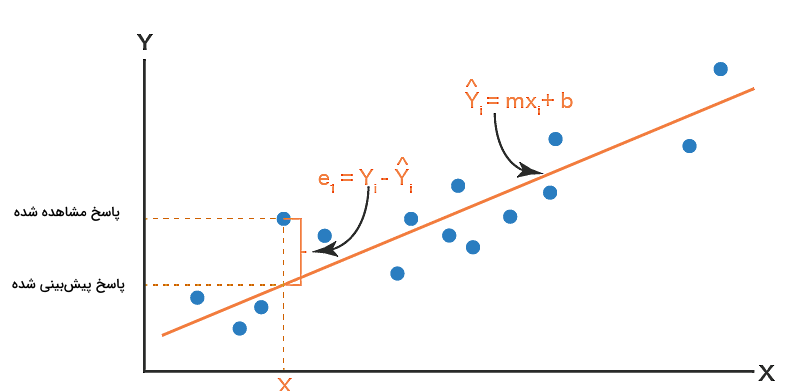
دنبال معادله خطی به فرم نشان داده شده در بخشهای قبل یعنی هستیم که در آن a عرض از مبدا و b شیب خط رگرسیون است. برای محاسبه a و b با توجه به این دو مجموعه متغیر، از فرمولهای زیر استفاده میکنیم:
اگر آخرین تمرین را حل کرده باشید، تا حدی با روند بهدست آوردن این دو ضریب آشنا شدهاید. n در روابط بالا برابر است با تعداد نقاط دادهها. برای محاسبه حداقل مربعات توسط فرمولهای بالا، بهتر است مراحل زیر را انجام دهیم تا از پیچیدگی و اشتباه در محاسبات جلوگیری شود:
- جدولی با چهار ستون رسم کنید که دو ستون اول آن به نقاط x و y اختصاص دارد.
- در دو ستون دیگر این جدول، مقادیر و را محاسبه کنید.
- مقادیر ، ، و را پیدا کنید.
- حالا میتوانید شیب b را با فرمول بالا بهدست آورید.
- در مرحله بعد میتوانید عرض از مبدا a را حساب کنید.
- مقادیر a و b را در معادله خط قرار دهید.
در مثال زیر این مراحل را با هم انجام میدهیم.
مثال روش حداقل مربعات
فرض کنید دو مجموعه داده بهصورت زیر داریم و میخواهیم خط رگرسیون را با روش حداقل مربعات پیدا کنیم:
طبق مراحلی که در بالا توضیح دادیم، پیش میرویم:
در چهارمین مرحله از فرمولهایی که در ابتدای این بخش برای شیب و عرض از مبدا نوشتیم، استفاده میکنیم:
بنابراین طبق معادله خط به شکل ، خواهیم داشت:
تمرین روش حداقل مربعات
فرض کنید مجموعه دادههای زیر میزان فروش یک شرکت بر حسب میلیون تومان در هر سال را نشان میدهد. برآورد شما از فروش این شرکت در سال ۲۰۲۰ کدام گزینه است؟
| سال | فروش |
گزینه دوم صحیح است. دقت کنید برای حال این سوال باید معادله خط گرسیون را بهدست آوریم و سپس با در نظر گرفتن سال ۲۰۲۰ ببینیم چه مقدار فروش برای این سال پیشبینی میشود. پس اول باید متغیرهای مستقل و وابسته را مشخص کنیم.
فروش متغیر وابسته یا y و سال متغیر مستقل یا x است. در اینجا برای اینکه تحلیل درستی داشته باشیم لازم است از تغییر متغیر استفاده کنیم، چون اصولا محاسبه مجموع مقادیر سال معنایی ندارد. به همین علت متغیر t را با x جایگزین میکنیم که آن را به شکل زیر تعریف کردهایم:
همچنین تعداد نقاط دادههای ما در این مسئله یا n برابر است با ۵. پس جدول را به شکل زیر رسم میکنیم:
دقت کنید ستون اول با توجه به متغیر جدیدی که تعریف کردیم، چگونه مجددا محاسبه و نوشته شد. در مرحله بعدی جدول چهار ستونی را رسم کرده و مقادیر موردنیاز آن را بهدست میآوریم:
حالا از فرمولهای مربوط به محاسبه a و b استفاده میکنیم:
بنابراین معادله خط رگرسیون خواهد شد:
دقت کنید معادله خط برحسب متغیر t نوشته میشود، نه x. پس برای اینکه سال ۲۰۲۰ را در نظر بگیریم کافی است آن را در اولین فرمولی که برای تغییر متغیر در این مسئله بکار بردیم، جایگذاری کنیم:
حالا مقدار t برابر با ۵ را در معادله خط بالا قرار میدهیم تا فروش در سال ۲۰۲۰ یا y برای این سال محاسبه شود:
تحلیل مدلهای رگرسیون چگونه انجام میشود؟
در بخشهای قبل با انواع مدلهای رگرسیون آشنا شدیم و برای مثال یاد گرفتیم تفاوت نوع خطی و غیرخطی یا چندگانه و گام به گام در مدلهای رگرسیون چیست. حالا میخواهیم ببینیم چگونه این مدلها را بسازیم و سپس آنها را تحلیل کنیم. روند کار با انواع مدلهای رگرسیون شامل مراحل زیر است:
- تعریف متغیرها
- ترسیم دادهها
- ارزیابی همبستگی
- تشخیص خط رگرسیون
- تفسیر فرمول مدل رگرسیون
- در نظر گرفتن خطا
در ادامه هر کدام از این مراحل را توضیح میدهیم.
تعریف متغیرها
همانطور که در ابتدای مطلب اشاره شد، در رگرسیون با دو نوع متغیر سروکار داریم، متغیرهای وابسته و متغیرهای مستقل. پس اولین قدم در تحلیل مدل، این است که تشخیص دهیم چه متغیرهایی داریم و کدام وابسته و کدام مستقل هستند. تعریفهای زیر در مورد این دو نوع متغیر کمککننده است:
- متغیر وابسته: متغیری که سعی میکنید آن را تشخیص دهید و اثر آن را روی متغیر مستقل مطالعه کنید.
- متغیر مستقل: متغیری است که قصد دارید تغییرات یا ویژگیهای آن را کنترل یا دست کاری کنید.
ترسیم دادهها
پس از اینکه متغیرهای خود را تعریف کردید، باید برای هر متغیر داده جمعآوری کنید. در مرحله بعد باید این دادهها را بر اساس تعداد متغیرهای مستقل و وابسته خود، در قالب یک گراف رسم کنید. اینکه چه نوع گرافی برای رسم دادههای شما مناسب است، به این بستگی دارد که چه مدلی را انتخاب کرده باشید. برای مثال اگر یک متغیر مستقل و یک متغیر وابسته دارید، نمودار نقطهای رسم کنید. اگر چند متغیر مستقل دارید، ممکن است نیاز باشد برای هر جفت از متغیرهای خود نمودار نقطهای جداگانهای رسم کنید. اما همیشه، متغیر وابسته روی محور عمودی یا قائم و متغیر مستقل روی محور افقی قرار میگیرد.
ارزیابی همبستگی
مرحله بعدی برای اینکه بتوانید مدل رگرسیون خود را تحلیل کنید، بررسی نموداری است که در مرحله قبل رسم کردید. نمودار رسم شده به مشا کمک میکند بفهمید رابطه بین متغیرهای وابسته و متغیرهای مستقل شما به چه صورت است. معمولا در این بررسی باید به دنبال یک الگو یا روند خاصی باشید که شما را به نوعی همبستگی برساند. محاسبه ضریب همبستگی طبق آنچه در بخشهای قبل گفتیم، اطلاعات خوبی به شما خواهد داد.
تشخیص خط رگرسیون
در شرایطی که مدل رگرسیون شما خطی است، همانطور که توضیح دادیم دادههای شما تقریبا حول یک خط مستقیم قرار دارند. در واقع این خط مستقیم که بیانگر رابطه بین دو متغیر شما است، خط رگرسیون نامیده میشود. اگر خط رگرسیون را با روشهای آماری بهدست آورید، در این صورت قادر خواهید بود تفاوت میان نقاط دادههای واقعی و مقادیر پیشبینی شده روی خط را به کمترین مقدار خود برسانید. در بخشهای قبل توضیح دادیم که چگونه میتوانید با انجام محاسبات دقیق، معادله این خط را بهدست آورید. برای ترسیم این خط میتوانید از نرمافزار اکسل نیز کمک بگیرید.
تفسیر فرمول مدل رگرسیون
فرمول مدل رگرسیون یکی دیگر از ابزارهایی است که میتواند رابطه بین متغیرهای مستقل و وابسته را در قالب ریاضیات نمایش دهد. در مورد مدل رگرسیون خطی ساده، شکل ساده شده فرمول به صورت زیر است:
در این رابطه که قبلا به آن اشاره شد، عرض از مبدا یا a برابر است با مقدار Y زمانی که X = 0. شیب b نیز برابر است با تغییرات در Y همزمان با یک واحد تغییر در X. میزان خطا یا u همان تفاوت بین مقادیر مشاهده شده و مقادیر پیشبینی شده Y است.
در نظر گرفتن خطا
در نهایت مهم است که همیشه در نظر داشته باشیم سطحی از خطا در روابط بین متغیرها وجود دارد که باید تخمین زده شود. این مسئله باعث میشود قابلیت اطمینان و دقت نتایج تحلیل رگرسیون مطمئنتر باشد.
بیشبرازش یا overfitting در رگرسیون
برای اینکه متوجه شویم راهکار تشخیص میزان خطا در رگرسیون چیست، آشنایی با مفهوم اورفیتینگ مهم است. بیش برازش نوعی خطای مدلسازی است که اغلب در تحلیل رگرسیون و زمانی که یک تابع یا یک مدل خیلی پیچیده است یا پارامترهای خیلی زیادی از یک نمونه کوچک تخمین زده شدهاند، اتفاق میافتد. گاهی ممکن است مدل بیشبرازش شده کاملا با دادههای شما فیت باشد، اما قطعا با امتحان کردن نمونههای بیشتر یا کل جمعیت هدف کار نخواهد کرد.
اگر مدلی بیشبرازش شده باشد، مقادیر احتمال یا p-values، ضریب تشخیص یا R-squared و ضرایب رگرسیون آن احتمالا گمراهکننده باشند. بنابراین خیلی مهم است که بدانیم چطور از این وضعیت اجتناب کنیم. یکی از روشهای جلوگیری از بیشبرازش دادهها این است که دادههای بیشتری جمعآوری شود. اگر دادههای بیشتری جمع کنید، دقت مدل شما بیشتر و احتمال خطا کمتر خواهد شد.
یادگیری پیشرفته رگرسیون با فرادرس
در انتهای این مطلب از مجله فرادرس، چنانچه تمایل دارید با مباحث پیشرفتهتر رگرسیون در سطوح دانشگاهی آشنا شوید، پیشنهاد ما این است که دورههای آموزشی زیر از مجموعه فرادرس را مشاهده کنید. بهعلاوه مشاهده فیلمهای زیر در زمینه آشنایی با نرمافزارهای مرتبط با رگرسیون یا کاربردهای این روش تحلیل آماری در بررسی موضوعات مختلف، بسیار کمککننده خواهد بود:

- مجموعه آموزش تخمین و رگرسیون – مقدماتی تا پیشرفته فرادرس
- مجموعه آموزش اس پی اس اس SPSS – مقدماتی تا پیشرفته فرادرس
- فیلم آموزش رایگان رگرسیون غیرخطی و لجستیک در تحلیل اطلاعات با SAS فرادرس
- فیلم آموزش رایگان رگرسیون خطی و شبکه عصبی MLP در پایتون برای پیش بینی چربی بدن فرادرس
- فیلم آموزش رایگان رگرسیون لجستیک در یادگیری ماشین فرادرس
- فیلم آموزش همبستگی و رگرسیون خطی در اس پی اس اس SPSS فرادرس
- فیلم ٰآموزش ماشین بردار پشتیبان و رگرسیون لجستیک + پیاده سازی در پایتون فرادرس
- فیلم آموزش تحلیل های رگرسیونی با اس پی اس اس SPSS فرادرس
- فیلم آموزش محاسبات آماری در اکسل Excel فرادرس
جمعبندی
رگرسیون روش یا تکنیکی است که با مدلسازی رابطه بین متغیرهای مستقل و وابسته به ما کمک میکند تا قدرت و جهت رابطه آنها را تشخیص دهیم. بنابراین در رگرسیون سه مورد مهم است، کدام متغیرها مستقل هستند، کدام متغیرها وابسته هستند و چه نوع ارتباطی بین این دو گروه متغیر وجود دارد. بر این اساس میتوانیم تقسیمبندی خطی و غیرخطی را برای رگرسیون داشته باشیم. در مورد رگرسیون خطی ساده، معادله حاکم بر خط رگرسشیون معادله یک خط راست است.
source