Apache Kafka یک فریمورک متنباز برای پردازش «دادههای جریانی» (Streaming Data) است که تبدیل به سنگ بنای معماری مدرن داده شده است. این فریمورک قدرتمند به منظور مدیریت حجم زیادی از داده در لحظه با توان عملیاتی بالا و تاخیر کم طراحی شده است. توانایی Kafka در یکپارچهسازی منابع مختلف داده و پردازش مقادیر زیاد اطلاعات به صورت لحظهای این فریمورک را به یک عنصر حیاتی در محیطهای مبتنی بر داده تبدیل کرده است. بسیاری از اپلیکیشنهای مبتنی بر داده نظیر برنامههای مالی، سرویسهای حملونقل و فروشگاههای اینترنتی از آپاچی کافکا برای مدیریت و پردازش دادههای خود در لحظه استفاده میکنند. بر همین اساس در این مطلب از مجله فرادرس به این سوال پاسخ خواهیم داد که Kafka چیست و چگونه دنیای داده را متحول کرده است.


با مطالعه این مطلب ضمن آشنایی با بخشهای اصلی Kafka، نحوه تعامل و ارتباط این بخشها با یکدیگر را نیز یاد خواهید گرفت. علاوه بر این، یاد خواهید گرفت که کاربردهای Apache Kafka چیست و چگونه میتوان از این ابزار در دنیای واقعی استفاده کرد. در ادامه مطلب نیز مراحل نصب و راهاندازی کافکا در ویندوز به صورت گامبهگام آموزش داده شده است.
Kafka چیست؟
قبل از پاسخ به این سوال که Kafka چیست قصد داریم تا دلیل پیدایش این پلتفرم را مورد بررسی قرار دهیم. امروزه معماری اپلیکیشنهای کاربردی مدرن به استفاده از میکروسرویسها و معماری مبتنی بر رویداد تغییر پیدا کرده است. در واقع میتوان گفت که دوران «پردازش دستهای» (Batch Processing) دادهها به اتمام رسیده است. توسعه دهندگان به منظور افزایش سرعت و بهبود دسترسی پذیری به اطلاعات معماری اپلیکیشنها را تغییر دادهاند. سیستمهای مبتنی بر رویداد از چندین برنامه کاربردی جدا از هم تشکیل میشوند که برای کمک به یکپارچهسازی سرویسهای مختلف مورد استفاده قرار میگیرند. در معماری مبتنی بر رویداد منطق تمام بخشهای برنامه برحسب رویدادها تعریف میشود. آپاچی کافکا در اینجا خود را نشان میدهد.
Apache Kafka یک فریمورک متنباز توزیع شده برای پردازش دادههای جریانی است که توسط یک تیم ۳ نفره نخستین بار در شرکت LinkedIn توسعه یافته است. این ابزار به منظور دریافت و پردازش دادههای جریانی در زمان واقعی بهینهسازی شده است. بنابراین، میتوان از این ابزار برای پیادهسازی خطوط انتقال دادههای جریانی، اپلیکیشنهای تجزیه و تحلیل جریان و خدمات «یکپارچهسازی دادهها» (Data Integration) استفاده کرد. در حقیقت Apache Kafka یک فریمورک برای رویدادهای توزیع شده و پردازش جریان است که میتواند به عنوان واسطه ارسال پیام، منبع رویداد، سیستم مدیریت صف و سایر موارد به کار گرفته شود. برای یادگیری بیشتر در خصوص انواع پردازش داده میتوانید مطلب پردازش داده از مجله فرادرس را مطالعه کنید که لینک آن در ادامه آورده شده است.
چرا باید از کافکا استفاده کنیم؟
پلتفرم کافکا بعد از ذخیرهسازی رویدادها آنها را به سرویس مربوطه هدایت میکند. توسعه دهندگان میتوانند چنین سیستمی را بدون وابستگی به سایر سرویسها مقیاسبندی و نگهداری کنند. Kafka یک بسته همهکاره است که میتواند به عنوان واسط ارسال پیام، ذخیرهساز رویداد یا فریمورک پردازش جریان مورد استفاده قرار گیرد.
این فریمورک با توان عملیاتی و پایداری بالا توانایی پردازش متوالی صدها منبع جریان داده را به طور همزمان دارد. به طور کلی مهمترین دلایل استفاده از آپاچی کافکا عبارتنداز:
- توان عملیاتی بالا
- مقیاس پذیری
- زمان تاخیر بسیار کم
- دوام و قابلیت اطمینان بالا
- دسترسی پذیری بالا
در ادامه این بخش هر کدام از موارد ارائه شده در بالا به طور کامل توضیح داده خواهد شد.
توان عملیاتی بالا
Kafka از معماری بسیار خوبی برخوردار است که شامل تقسیمبندی دادهها، پردازش دستهای، تکنیکهای بدون کپی و گزارشهای پیوست میشود. به لطف این معماری قدرتمند کافکا به توان عملیاتی بالایی دست پیدا کرده است و امکان مدیریت میلیونها پیام را در ثانیه دارد. همچنین، کافکا سناریوهای مربوط به داده با سرعت و حجم بالا را نیز برآورده میسازد. بنابراین، پروتکل ارتباطی سبک وزن تعامل موثر بین مشتری و کارگزار را تسهیل میکند و جریان داده در زمان واقعی را امکانپذیر میسازد.

مقیاس پذیری
یکی دیگر از دلایل استفاده از کافکا مقیاسپذیری بالا این پلتفرم است. آپاچی کافکا با تقسیم اطلاعات به چندین بخش تعادل بار در سرور را فراهم میکند. این مورد به کاربران امکان میدهد تا خوشههای تولید را بین مناطق در دسترس توزیع کنند و آنها را متناسب با نیاز خود افزایش یا کاهش دهند. به عبارت دیگر، آپاچی کافکا میتواند تریلیونها پیام در روز را با توزیع آنها در بخشهای مختلف مدیریت کند.
زمان تاخیر بسیار کم
Apache Kafka از خوشهای از سرورها با تاخیر بسیار کم (در حدود ۲ میلی ثانیه) استفاده میکند و با جداسازی جریانهای داده پیامها را به طور موثر در توان عملیاتی محدود شبکه تحویل میدهد.
دوام و قابلیت اطمینان بالا
Kafka تحمل خطا و دوام داده را به دو روش کلیدی زیر افزایش میدهد.
- با توزیع ذخیرهسازی جریان داده در یک خوشه تحمل کننده خطا از خراب شدن سرور محافظت میکند.
- با ذخیرهسازی پیامها روی دیسک تکرار درون خوشهای را ارائه میدهد.
دسترسی پذیری بالا
معماری کارگزاران کافکا مبتنی بر خوشه است. در نتیجه، حتی در صورت قطع شدن سرور این پلتفرم همچنان فعال است. در واقع، زمانی که یکی از سرورها با مشکل مواجه میشود، آنگاه کافکا درخواستهایی را برای کارگزاران دیگر ارسال میکند. برای آشنایی بیشتر با خوشهبندی و شیوههای مختلف آن میتوانید مطلب زیر از مجله فرادرس را مطالعه کنید.
چگونه تحلیل داده را با فرادرس یاد بگیریم؟
امروزه تجزیه و تحلیل داده نقش بسیار مهمی در دنیای فناوری دارد و بر جنبههای مختلف فناوری، تجارت و جامعه تاثیر میگذارد. متخصصان این حوزه از تجزیه و تحلیل داده به منظور شناسایی روندها، درک علاقهمندیهای مشتری و ارائه استراتژیهای بازاریابی استفاده میکنند. امروزه با توجه به رشد روزافزون تکنولوژی توانایی تجزیه و تحلیل داده تبدیل به امری ضروری شده است. بر همین اساس در پلتفرم فرادرس دورههای آموزشی متعددی در این حوزه منتشر شده است که میتوانید از این آموزشها برای آشنایی بیشتر با این حوزه استفاده کنید.

برای دسترسی به مجموعه فیلمهای آموزش تحلیل داده فرادرس میتوانید از لینک زیر استفاده کنید.
در ادامه برخی از عناوین پیشنهادی که در فهرست آموزشهای تحلیل داده قرار دارند، آورده شده است.
کاربردهای Apache Kafka چیست؟
به احتمال زیاد این سوال برای شما پیش آمده باشد که کاربردهای Kafka چیست و این فریمورک در دنیای واقعی ما چه نقشی دارد. Apache Kafka به عنوان یک فریمورک پخش رویداد توزیع شده به طور گسترده در برنامههای مختلف مورد استفاده قرار میگیرد. این فریمورک پیامرسانی، ذخیرهسازی و پردازش دادههای جریانی را با یکدیگر ترکیب میکند تا امکان ذخیره و تجزیه و تحلیل دادههای بلادرنگ را داشته باشد. از کافکا در توسعه اپلیکیشنهای مبتنی بر دادههای بلادرنگ نظیر اپلیکیشنهای بانکی، سرویسهای حملونقل، فروشگاههای اینترنتی و سایر موارد به طور گسترده استفاده میشود. در یک دستهبندی کلی کاربردهای کافکا را به موارد زیر میتوان تقسیم کرد.
- ردیابی فعالیت کاربران
- پیامرسانی
- تجمیع گزارش
- پردازش جریان
- جمعآوری آمار
ردیابی فعالیت کاربران
شاید برای شما هم این سوال پیش آمده باشد که مهمترین کاربرد Kafka چیست. پلتفرم کافکا کاربردهای عملی متعددی دارد که یکی از جذابترین کاربردهای کافکا استفاده از آن برای ردیابی فعالیتهای کاربران است. به عنوان مثال، یک فروشگاه آنلاین اینترنتی میتواند از Kafka برای ردیابی فعالیتهای کاربرانش در لحظه استفاده کند. با استفاده از کافکا امکان رصد و ذخیرهسازی تمام فعالیتهای کاربران از جمله مشاهده محصولات، افزودن موارد به سبد خرید، جستجو، گذاشتن نظر و سایر موارد وجود دارد. در واقع، کافکا این موارد را به عنوان رویداد برای topicها ارسال میکند. علاوه بر این، با ادغام کافکا با سایر میکروسرویسها میتوان از این اطلاعات ذخیره شده به منظور کشف تقلب در سیستم، گزارشدهی و ارائه پیشنهادات شخصیسازی شده به کاربران استفاده کرد.

پیامرسانی
Apache Kafka با توجه به امکانات و قابلیتهای خود همچون پارتیشنبندی داخلی، تکرار، تحمل خطا و مقیاسبندی جایگزین بسیار خوبی برای کارگزاران پیام رایج است. سرویسهای حملونقل آنلاین مبتنی بر میکروسرویس همچون تاکسیهای اینترنتی میتوانند از Kafka برای تسهیل تبادل پیام در سرویسهای مختلف استفاده کنند. به عنوان مثال، یک اپلیکیشن تاکسی اینترنتی میتواند از کافکا برای برقراری ارتباط با سرویس تطبیق راننده در لحظه درخواست سفر توسط مسافر استفاده کند. سرویس تطبیق راننده در لحظه میتواند یک راننده را در منظقه مورد نظر پیدا کرده و به درخواست مسافر پاسخ دهد.
تجمیع گزارش
یکی دیگر از کاربردهای کافکا استفاده از آن به منظور گزارشگیری و ذخیره آنها در سرور است. Apache Kafka دادههای دریافتی را به عنوان جریانی از پیامها انتزاع و اطلاعات مربوط به فایل را فیلتر میکند. استفاده از کافکا امکان پردازش دادهها با تاخیر کم را فراهم میسازد. پس از انتشار گزارش توسط کافکا میتوان از اطلاعات حاصل به منظور عیبیابی، نظارت بر امنیت، تجزیه و تحلیل عملکرد و سایر موارد استفاده کرد.
پردازش جریان
دادهها در آپاچی کافکا در خطوط لوله به صورت چند مرحلهای پردازش میشوند. دادههای خام از topicهای کافکا گرفته شده و پس از تجمیع پردازش میشوند. در نهایت، این اطلاعات پردازش شده به منظور مصرف به topicهای جدید ارسال خواهند شد. به عنوان مثال، یک بانک از Kafka برای پردازش لحظهای تراکنشها میتواند استفاده کند. با انجام هر تراکنش توسط مشتری بانک یک رویداد جدید به topic کافکا ارسال میشود. در نتیجه، با استفاده از یک اپلیکیشن کاربردی میتوان اقدامات لازم نسبت به انجام این رویدادها، تایید و مدیریت تراکنشها، توقف و حذف تراکنشهای مشکوک و بهروزرسانی موجودی مشتری را انجام داد.

جمع آوری آمار
آپاچی کافکا میتواند توسط یک ارائه دهنده خدمات ابری به منظور جمعآوری آمار از برنامههای کاربردی توزیع شده برای تولید جریانهای متمرکز داده در لحظه مورد استفاده قرار گیرد. اطلاعاتی همچون آمار مربوط به سرورها مانند مصرف پردازنده و حافظه، تعداد درخواستها، نرخ خطا و سایر موارد به Kafka گزارش میشود. در نهایت، برنامههای مانیتورینگ میتوانند از این معیارها به منظور شناسایی ناهنجاریها، هشدار و شبیهسازی در لحظه استفاده کنند. برای یادگیری بیشتر در خصوص کلان داده و اهمیت استفاده از آن میتوانید فیلم آموزش کلان داده فرادرس را مشاهده کنید که لینک آن در ادامه آورده شده است.
مفاهیم کلیدی Kafka چیست؟
Apache Kafka به عنوان یک پلتفرم پخش رویداد توزیع شده برای کاربردهایی طراحی شده است که سرعت و دسترسی بالا در آنها اهمیت بالایی دارد. آپاچی کافکا کاربران را قادر میسازد تا دادهها را در لحظه تجزیه و تحلیل کنند، رکوردها را به ترتیب ایجادشان ذخیره کرده و آنها را منتشر کنند.
معماری این فریمورک از چندین مولفه اصلی تشکیل شده است که با یکدیگر کار میکنند تا پردازش و پیامرسانی بلادرنگ داده را امکانپذیر سازند. مهمترین بخشهای آپاچی کافکا عبارتنداز:
- «کارگزاران» (Brokers)
- «تاپیکها» (Topics)
- «پارتیشنها» (Partitions)
- «تولید کنندهها» (Producers)
- «مصرف کنندهها» (Consumers)
در ادامه این بخش از نوشته یاد خواهید گرفت که کاربرد و نقش هر کدام از مولفههای ارائه شده در بالا در پلتفرم Kafka چیست.
کاربرد broker در Kafka چیست؟
آیا تا به حال به این موضوع فکر کردهاید که چگونه حجم بسیار زیادی از دادهها به صورت کارآمد در لحظه پردازش و توزیع میشوند. این مورد به لطف وجود broker در Kafka امکانپذیر شده است. brokerها بخشی از پلتفرم آپاچی کافکا هستند که مسئولیت ذخیره، مدیریت و توزیع کارآمد پیامها را در سیستم پیامرسان کافکا برعهده دارند. یک خوشه در پلتفرم کافکا از چندین broker تشکیل میشود. به زبان سادهتر brokerها سرورهایی در خوشه هستند که دادهها را ذخیره میکنند و به مشتریان خدمات ارائه میدهند. brokerها در کافکا امکان تبادل اطلاعات بین تولیدکنندگان و مصرفکنندگان داده را فراهم میکنند. همچنین، این brokerها مسئولیت مدیریت تمام درخواستهای مشتری برای نوشتن و خواندن رویدادها را برعهده دارند. به منظور شناسایی brokerها در خوشه به هر کدام از آنها یک شناسه عددی منحصربهفرد اختصاص داده میشود.
topics در کافکا چه کاربردی دارد؟
از تاپیکها در معماری آپاچی کافکا برای سازماندهی پیامها استفاده میشود. هر کدام از تاپیکها دارای نام منحصربهفردی در خوشه کافکا هستند. در آپاچی کافکا پیامها به تاپیکهای مورد نظر ارسال و در نقطه مقابل نیز از تاپیکها خوانده میشوند. به زبان سادهتر تولیدکنندگان دادهها را روی تاپیکها مینویسند و مصرفکنندگان نیز دادهها را از تاپیکها میخوانند. نکته مهم در خصوص تاپیکها در کافکا این است که هر کدام از آنها میتوانند یک یا چند مصرف کننده داشته باشند. همچنین، ممکن است یک تاپیک هیچ مصرفکنندهای نداشته باشد. تصویر زیر به خوبی نحوه عملکرد تایپکها در Kafka را نشان میدهد.
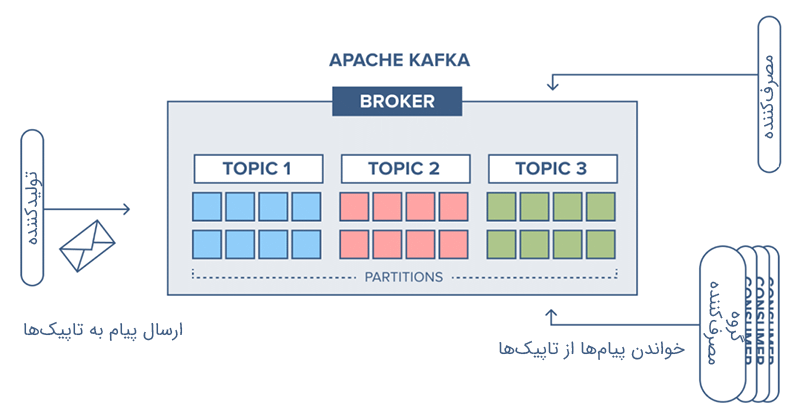
در Kafka تاپیکها در طول زمان اجرا بین brokerها تقسیم شده و تکرار میشوند. این تقسیمبندی از اهمیت بالایی برخوردار است، زیرا موازیسازی موضوعات را امکانپذیر میسازد و بازدهی ارسال پیام را نیز افزایش میدهد.
منظور از partitions در Kafka چیست؟
به منظور مدیریت آسانتر دادهها هر topic به چندین پارتیشن تقسیم میشود و توزیع دادهها توسط کافکا بین این پارتیشنها صورت میگیرد. با استفاده از پارتیشنها عملیات ذخیرهسازی پیامها، نوشتن پیامهای جدید و پردازش پیامهای موجود بین topicهای موجود در خوشه کافکا توزیع میشود.
چالش مهم در عملیات پارتیشنبندی topicها این است که کدام پیام در کدام پارتیشن باید نوشته شود. Kafka برای توزیع پیام بین پارتیشنها از کلید استفاده میکند. به طور معمول، اگر پیامی فاقد کلید باشد، آنگاه پیامهای بعدی به صورت چرخشی بین تمام پارتیشنهای موجود در topic تقسیم میشوند. در این حالت، تمام پارتیشنها سهم یکسانی از داده را خواهند داشت، ولی ترتیب پیامهای ورودی حفظ نخواهد شد. همچنین، در صورت تعیین کلید برای پیامها پارتیشن مقصد از طریق هش کلید محاسبه میشود. در نتیجه، با استفاده از این مکانیزم کافکا پیامهای با کلید یکسان را همواره درون یک پارتیشن مشخص ذخیره خواهد کرد.
producer در Kafka چیست؟
برنامههایی که دادهها را به تاپیکهای مختلف ارسال میکنند به عنوان producer یا در اصطلاح تولیدکننده شناخته میشوند. این برنامهها برای ارسال پیام به تاپیکهای مختلف از کتابخانه client در آپاچی کافکا استفاده میکنند. کتابخانه client در آپاچی کافکا برای همه زبانهای برنامهنویسی همچون پایتون، جاوا، Go و سایر موارد وجود دارد. یک producer در کافکا پیامها را به یک تاپیک ارسال میکند و پیامها نیز بر اساس مکانیزمی مشخص بین پارتیشنها توزیع میشوند.
consumer در Kafka چیست؟
منظور از consumer در کافکا برنامههایی هستند که پیامهایی را در لحظه از تاپیکهای مختلف میخوانند و آنها را پردازش میکنند. consumerها یا در اصطلاح مصرفکنندهها برای خواندن و پردازش پیامها در آپاچی کافکا از کتابخانه Client در این پلتفرم استفاده میکنند که برای زبانهای برنامهنویسی مختلف همچون پایتون، جاوا و Go در دسترس است. مصرفکنندگان میتوانند در تاپیکها یا پارتیشنهای خاص مشترک شوند و به صورت همزمان پیامها را از یک یا چند پارتیشن دریافت کنند. هنگامی که چندین مصرفکننده به صورت همزمان در یک تاپیک مشترک شوند، آنگاه کافکا به شکلی عمل میکند که هر پارتیشن دادهها را تنها برای یک مصرفکننده ارسال کند. نکته مهم در این خصوص این است که همواره تعداد مصرفکنندگان برابر یا کمتر از تعداد پارتیشنها است.
منظور از consumer group در Kafka چیست؟
consumer group در کافکا به گروهی از مصرفکنندگان اشاره دارد که دارایgroup.id یکسانی هستند و همگی نیز در یک تاپیک مشترک هستند. به لطف وجود consumer group میتوان مصرفکنندگان را موازی کرد تا چندین مصرفکننده بتوانند از چندین پارتیشن در یک تاپیک اطلاعات را بخوانند. در نتیجه این امر پردازش حجم بالایی از پیامها امکانپذیر خواهد شد. تصویر زیر نحوه خواندن اطلاعات توسط consumer group از پارتیشنهای موجود در یک تاپیک را نشان میدهد.

نکته بسیار مهمی که در خصوص گروه مصرفکننده باید به آن توجه داشت این است که هر زمان یک مصرفکننده به گروه اضافه یا حذف شود، آنگاه مصرف مجدد بین مصرفکنندگان گروه متعادل خواهد شد. در واقع، بعد از بروز تغییر در گروه مصرفکنندگان تمام مصرفکنندگان متوقف شده و پارتیشنهای تاپیک مجدداً به مصرفکنندگان موجود اختصاص داده میشوند. سپس، مصرفکنندگان مجدداً راهاندازی خواهند شد. مزیت اصلی استفاده از consumer group در کافکا این است که امکان پردازش حجم زیادی از پیام را فراهم میکند، زیرا چندین مصرفکننده میتوانند اطلاعات را از چندین پارتیشن در یک تاپیک بخوانند.
قابلیت های Kafka چیست؟
آپاچی کافکا یک پلتفرم توزیع شده برای جریانهای داده است که به منظور مدیریت دادهها در لحظه طراحی شده است. این پلتفرم قابلیتهای متعددی دارد که توجه شمار زیادی از توسعهدهندگان را به خود جلب کرده است. از جمله مهمترین قابلیتهای پلتفرم Kafka به موارد زیر میتوان اشاره کرد.
- کتابخانه Kafka Streams
- پردازش جریان
- پردازش زمان رویداد
- عملیات مبتنی بر زمان
- پردازش مبتنی بر حالت
- تضمین یک مرتبه پردازش داده
- دوام و قابلیت اطمینان
- جدا بودن تولیدکننده و مصرفکننده
- ادغام با سایر سیستمها
این قابلیتها آپاچی کافکا را به گزینهای قدرتمند جهت ساخت اپلیکیشنهای کاربردی مبتنی دادههای جریانی در حوزههای مختلف تبدیل کرده است. در ادامه این بخش هر کدام از قابلیتهای کافکا را به شکل کاملتری مورد بررسی قرار خواهیم داد.
کتابخانه Kafka Streams
با استفاده از کتابخانه Kafka Stream توسعهدهندگان میتوانند برنامههای پردازش جریان قوی را ایجاد کنند. کافکا یک API و «زبان خاص دامنه» (Domian Specific Languge | DSL) را برای مدیریت، تبدیل و ارزیابی جریانهای داده پیوسته ارائه میدهد.
پردازش جریان
آپاچی کافکا پردازش لحظهای جریانهای داده را امکانپذیر کرده است. با استفاده از کافکا میتوان دادهها را از topicها دریافت و پردازش کرد. سپس، میتوان اطلاعات پردازش شده را به topicهای موجود برگرداند. پردازش جریانهای داده امکان تجزیه و تحلیل، نظارت و غنیسازی داده را در لحظه فراهم میکند.

پردازش زمان رویداد
با استفاده از «مُهر زمانی» (Timestamp) متصل به هر کدام از رکوردها میتوان رکوردهای مختل شده را با توجه به پشتیبانی کافکا از پردازش زمان رویداد مدیریت کرد. Kafka عملیات پنجرهبندی معنایی زمان رویداد را فراهم میکند که «اتصال پنجره» (Window Joining)، نِشستها و تجمعهای مبتنی بر زمان را امکانپذیر میسازد.
عملیات مبتنی بر زمان
کتابخانه Kafka Stream چندین نوع عملیات پنجرهبندی را فراهم میکند که کاربران را قادر میسازد تا محاسبات خود را بر مبنای پنجرههای جلسه، پنجرههای در حال حرکت، پنجرههای کشویی و پنجرههای زمان ثابت انجام دهند. مواردی همچون محرکهای مبتنی بر رویداد، تجزیه و تحلیل حساس به زمان و تجمیعهای مبتنی بر زمان از طریق رویههای پنجرهای امکانپذیر است.
پردازش مبتنی بر حالت
در طی فرایند پردازش جریان Kafka Stream به کاربران این امکان را میدهد تا وضعیت را حفظ و بهروزرسانی کنند. همچنین، پشتیبانی داخلی برای ذخیرهسازی حالتها توسط کافکا ارائه شده است. باید به این نکته توجه داشت که حالتها در کافکا به شکل «کلید-مقدار» (Key-Value) ذخیره میشوند. در نتیجه، جستجو و بهروزسانی اطلاعات بر مبنای یک توپولوژی پردازشی امکانپذیر خواهد بود.
تضمین یک مرتبه پردازش داده
آپاچی کافکا معنایی سراسری را برای پردازش دقیقاً یک مرتبه اطلاعات ارائه میدهد. در واقع، Kafka تضمین میکند که هر رکورد تنها یک مرتبه توسط مصرفکننده پردازش شود. ارائه این معنای سراسری مستلزم هماهنگی بین تولیدکنندگان و مصرفکنندگان با تعریف مکانیزمهای مبادلهای است.

دوام و قابلیت اطمینان
آپاچی کافکا جریانهای داده را به روشی بدون خطا ذخیره میکند. دادهها در چندین broker تکرار میشوند و دوام و دسترسی آسان را حتی در صورت بروز خطا در broker تضمین میکنند.
جدا بودن تولیدکننده و مصرفکننده
معماری موجود در آپاچی کافکا تولیدکنندگان و مصرفکنندگان را از یکدیگر جدا میکند و به هر کدام از آنها امکان میدهد تا به صورت مستقل تکامل پیدا کنند. این مورد به برنامههای مختلف امکان میدهد تا دادهها را بدون تاثیر تغییرات در تولیدکنندگان مصرف کنند.
ادغام با سایر سیستمها
آپاچی کافکا با استفاده از فریمورک Kafka Connect به راحتی میتواند با سایر سیستمهای داده ادغام شود. در نتیجه این امر، امکان دریافت داده از سایر منابع را خواهد داشت.
چگونه کافکا را نصب کنیم؟
به منظور سازگاری بیشتر و عملکرد بهتر توصیه میشود تا آپاچی کافکا با ابزار Zookeeper نصب شود. علاوه بر این، نصب Kafka بر روی سیستمعامل ویندوز اغلب با مشکلات متعددی همراه است، زیرا این پلتفرم به طور خاص برای اجرا روی ویندوز طراحی نشده است.
به هر حال اگر قصد اجرای Apache Kafka بر روی ویندوز را دارید باید به ۲ نکته زیر توجه داشته باشید.
- در صورت استفاده از ویندوز ۱۰ یا نسخههای جدیدتر آن پیشنهاد میشود از WSL2 استفاده کنید.
- در صورت استفاده از ویندوز ۸ یا نسخههای قدیمیتر آن پیشنهاد میشود از Docker استفاده کنید.
علاوه بر رعایت نکات بالا باید به این نکته توجه داشته باشید که استفاده از «ماشین مجازی جاوا» (Java Virtual Machine | JVM) برای اجرا کافکا در ویندوز توصیه نمیشود، زیرا این ابزار بسیاری از ویژگیهای خاص سیستمعامل لینوکس را ندارد. در صورت عدم استفاده از WSL2 برای اجرای Kafka روی ویندوز با مشکلات متعددی مواجه خواهید شد. در ادامه این بخش از نوشته نحوه نصب Apache Kafka روی ویندوز با استفاده از WSL2 آموزش داده خواهد شد.
گام ۱: نصب WSL2 روی ویندوز
خوشبختانه در نسخههای ۱۰ و ۱۱ ویندوز قابلیت جذاب WSL یا همان «زیر سیستم ویندوز برای لینوکس» (Windows Subsystem for Linux | WSL) معرفی شده است که با استفاده از آن به سادگی میتوان از امکانات محیط لینوکس بدون نیاز به ماشین مجازی در ویندوز استفاده کرد. بیشتر دستورات لینوکس با WSL2 سازگار هستند و همین مورد فرایند نصب کافکا را به دستورالعملهای ارائه شده برای لینوکس نزدیکتر میکند. برای یادگیری بیشتر در خصوص تکنولوژی WSL میتوانید فیلم آموزش اجرای لینوکس روی ویندوز با WSL فرادرس را مشاهده کنید که لینک آن در ادامه آورده شده است.
سادهترین راه برای نصب WSL روی ویندوز اجرای دستور زیر در «خط فرمان» (Command Prompt) ویندوز است.
بعد از اجرای دستور بالا باید سیستم را «ریاستارت» (Restart) کنید. همچنین، در مراحل نصب WSL باید یک حساب کاربری و رمز عبور برای توزیع لینوکس تازه نصب شده خود ایجاد کنید.
گام ۲: نصب جاوا
یکی دیگر از الزامات نصب کافکا نصب و فعال بودن جاوا بر روی سیستم است. بنابراین، در صورت نصب نبودن جاوا باید آخرین نسخه آن را بر روی ویندوز نصب کنید.
- لینک دانلود آخرین نسخه جاوا: «+»
گام ۳: نصب Apache Kafka
در این مرحله باید آخرین نسخه آپاچی کافکا را از سایت رسمی این ابزار دانلود کنید.
- لینک دانلود آخرین نسخه Apache Kafka: «+»
باید به این نکته توجه داشته باشید که نسخههای مختلفی از Apache Kafka برای دانلود در سایت رسمی قرار داده شده است. برای نصب کافکا روی ویندوز باید آخرین نسخه Binary این پلتفرم را دانلود کنید. بعد از اتمام دانلود تمام فایلها را از حالت فشرده خارج کنید و درون پوشه جدیدی به نام Kafka قرار دهید.
گام ۴: راهاندازی ابزار Zookeeper
ابزار Zookeeper برای مدیریت خوشه در آپاچی کافکا ضروری است. بنابراین، این ابزار باید قبل از اجرای کافکا راهاندازی شود. Zookeeper بخشی از پلتفرم کافکا است و نیازی به نصب جداگانه آن نیست. برای راهاندازی Zookeeper خط فرمان ویندوز را باز کنید و به دایرکتوری ریشه کافکا بروید. سپس، دستور زیر را برای راهاندازی Zookeeper اجرا کنید.
1.binwindowszookeeper-server-start.bat .configzookeeper.propertiesگام ۵: راهاندازی سرور Kafka
در گام بعدی باید سرور کافکا را راهاندازی کنید. یک بار دیگر با باز کردن خط فرمان ویندوز دستور زیر را اجرا کنید.
1.binwindowskafka-server-start.bat .configserver.propertiesگام ۶: ایجاد topic در کافکا
برای ایجاد یک topic جدید در کافکا باید دستور زیر را در خط فرمان ویندوز اجرا کنید.
1.binwindowskafka-topics.bat --create --topic MyFirstTopic --bootstrap-server localhost:9092اجرای دستور بالا یک topic جدید به نامMyFirstTopic در کافکا میسازد.
گام ۷: راهاندازی Producer در کافکا
به منظور قرار دادن پیام در topic ایجاد شده باید یک Producer را راهاندازی کرد. برای این منظور دستور زیر را اجرا کنید.
1.binwindowskafka-console-producer.bat --topic MyFirstTopic --bootstrap-server localhost:9092گام ۸: راهاندازی Consumer در کافکا
برای تکمیل چرخه کار در آپاچی کافکا باید دستور زیر را در خط فرمان اجرا کرد تا پیامهای ارسال شده توسط producer به consumer برسد.
1.binwindowskafka-console-consumer.bat --topic MyFirstTopic --from-beginning --bootstrap-server localhost:9092با انجام تمام مراحل بالا همزمان با تولید پیام توسط producer از طرف مقابل consumer در لحظه پیام را دریافت میکند. مطمئناً این شروعی برای کار با پلتفرم جذاب آپاچی کافکا خواهد بود.
جمعبندی
Apache Kafka یک فریمورک قدرتمند برای پردازش دادههای جریانی است که به برنامههای کاربردی این امکان را میدهد تا حجم بسیار زیادی از دادهها را در لحظه و با سرعت بالا منتشر، مصرف و پردازش کنند. امروزه با توجه به نیاز روزافزون برای پردازش دادههای جریانی در لحظه Kafka به ابزاری بسیار حیاتی برای توسعهدهندگان این حوزه تبدیل شده است. در این مطلب از مجله فرادرس ضمن پاسخگویی به این سوال که Kafka چیست سعی شد تا مهمترین نکات در خصوص این فریمورک مورد بررسی قرار گیرد. برای یادگیری بیشتر در حوزه تحلیل داده میتوانید از مجموعه آموزشهای تحلیل داده فرادرس استفاده کنید که لینک آن در ادامه آورده شده است.
بر همین اساس در این نوشته موارد مهمی همچون دلایل استفاده از Kafka، اجزای اصلی تشکیل دهنده آن، کاربردهای آن در دنیای واقعی و مزایای استفاده از آن بیان شد. همچنین، نحوه نصب و راهاندازی این فریمورک نیز به صورت گامبهگام توضیح داده شد.
source