حتما برای شما نیز پیش آمده که هنگام انتخاب فیلم، آهنگ جدید یا محصول مناسب برای خرید دچار شک و تردید شوید. در چنین مواقعی «سیستمهای توصیهگر» (Recommendation Systems) بهکار آمده و بر اساس انتخابهای گذشته و همچنین علاقهمندیها، افراد را در انتخاب گزینه ایدهآل راهنمایی میکنند. در این مطلب از مجله فرادرس یاد میگیریم سیستم توصیه گر چیست و نحوه کارکرد آن چگونه است. نرمافزارهایی هوشمند که برای توصیه محصولات بر اساس رفتار و سلیقه کاربر طراحی شدهاند.


در این مطلب، ابتدا یاد میگیریم منظور از سیستم توصیه گر چیست و بهطور کلی چه پیشنهاد یا توصیهای مناسب و خوب در نظر گرفته میشود. سپس با انواع و همچنین کاربردهای سیستمهای توصیهگر آشنا میشویم و به بررسی مزایا و نحوه کارکرد این سیستمها میپردازیم. در انتهای این مطلب از مجله فرادرس شرح جامعی از رویکردهای مورد استفاده برای پیادهسازی یک سیستم توصیهگر ارائه میدهیم.
منظور از سیستم توصیه گر چیست؟
در حقیقت سیستم توصیهگر نوعی هوش مصنوعی یا الگوریتم هوشمند مرتبط با یادگیری ماشین است که از «کلان داده» برای پیشنهاد یا توصیه محصولات بیشتر به مصرفکننده استفاده میکند. این پیشنهادها ممکن است بر اساس شاخصهای متنوعی همچون خریدهای گذشته، تاریخچه جستجو و اطلاعات جمعیتشناختی ارائه شوند. سیستمهای توصیهگر کاربران را در یافتن محصولاتی کمک میکنند که در غیر این صورت و به تنهایی از وجود آنها مطلع نمیشدند و به همین دلیل بسیار کارآمد هستند. برای یادگیری بیشتر درباره سیستمهای توصیهگر، میتوانید فیلم آموزش عملی سیستمهای پیشنهادگر فرادرس را از طریق لینک زیر مشاهده کنید:
بهطور معمول هر سیستم یا سامانه توصیهگر بهگونهای آموزش میبیند که بتواند با استفاده از اطلاعات تعاملی جمعآوری شده از افراد و محصولات، اولویتها را شناسایی کرده و درک جامعی از تصمیمات گذشته بهدست آورد. از جمله این اطلاعات میتوان به تعداد بازدید، کلیک، لایک و پرداختها اشاره کرد. با توجه به توانایی پیشبینی علایق و خواستههای مشتری آن هم در سطح بالا و شخصیسازی شده، سیستمهای توصیهگر مورد توجه شرکتهای بسیاری قرار گرفتهاند. شرکتهایی مانند گوگل، اینستاگرام، اسپاتیفای، آمازون و نتفلیکس برای ارتقا تعامل خود با کاربران از سیستمهای توصیهگر بهره میبرند.

به عنوان مثال اسپاتیفای که پلتفرمی برای پخش آنلاین محتوای صوتی است، از سیستم توصیهگر برای شناسایی آهنگهای مشابه به آثار پرتکرار و مورد علاقه شما استفاده کرده و باعث میشود تا زمان بیشتری را در پلتفرم و برای شنیدن آهنگهای جدید سپری کنید. شرکت آمازون نیز مثال دیگری است که مطابق با اطلاعات جمعآوری شده از هر کاربر، محصولات تازهای را به او پیشنهاد میدهد.
چه پیشنهاد یا توصیه ای خوب است؟
حالا که میدانیم تعریف سیستم توصیه گر چیست، در این بخش با مفهوم و راههای شناسایی توصیه خوب آشنا میشویم. انتخاب معیار مناسب برای تشخیص و تعریف پیشنهاد یا توصیه خوب چالشی است که سازمانهای بسیاری با آن مواجه هستند. اگر مشخص کنیم منظورمان از «خوب» چیست، ارزیابی عملکرد سیستم توصیهگر به مراتب راحتتر میشود. کیفیت یک پیشنهاد را میتوان با تکنیکهای متنوعی همچون «دقت» (Accuracy) و «پوشش» (Coverage) اندازه گرفت. نسبت پیشنهادهای درست به کل پیشنهادهای ممکن را دقت و درصدی از موارد جستجو شده که برای سیستم توصیهگر قابل شناسایی هستند را پوشش مینامند. دقت داشته باشید که روش ارزیابی و سنجش پیشنهادها وابسته به دیتاست و رویکردی است که در وهله اول برای تولید هر پیشنهاد اتخاذ کردهایم.

سیستمهای توصیهگر شباهتهای مفهومی زیادی با مسائل مدلسازی «طبقهبندی» و «رگرسیون» دارند. در شرایط ایدهآل میخواهید از بازخورد کاربران نسبت به پیشنهادی که به آنها شده باخبر شوید و پیوسته عملکرد سیستم خود را توسعه دهید. فرایندی دشوار که به تجربه زیادی نیاز دارد.
آموزش سیستم های توصیه گر با فرادرس

سیستمهای توصیهگر یکی از کاربردیترین شاخههای یادگیری ماشین هستند که در بسیاری از سرویسهای آنلاین مورد استفاده قرار میگیرند. این سیستمها با تحلیل رفتار و ترجیحات کاربر، محتوا یا محصولات مورد علاقه او را پیشنهاد میدهند. سیستمهای توصیهگر انواع مختلفی داشته که در صنایع مختلفی از جمله تجارت الکترونیک، پخش رسانه، شبکههای اجتماعی و خدمات آنلاین بهکار میروند.
با توجه به اهمیت روزافزون سیستمهای توصیهگر در جهان دیجیتال و همچنین نقش کلیدی زبان برنامهنویسی پایتون در پیادهسازی این سیستمها، یادگیری عملی این مفاهیم میتواند برای متخصصان داده و توسعهدهندگان بسیار ارزشمند باشد. اگر مایل به یادگیری عمیقتر و کاربردی سیستمهای توصیهگر هستید، مجموعه فرادرس فیلمهای آموزشی جامعی را تولید کرده است که از آشنایی با مبانی نظری تا پیادهسازی عملی این سیستمها با زبان برنامهنویسی پایتون راهنمای شما خواهند بود. برای تهیه و مشاهده این دوره آموزشی به لینک زیر مراجعه کنید:
انواع سیستم توصیه گر چیست؟
در حالی که تکنیکها و الگوریتمهای متعددی در زمینه سیستمهای توصیهگر وجود دارند، اغلب در سه گروه زیر خلاصه میشوند:

- سیستمهای «پالایش گروهی» (Collaborative Filtering)
- سیستمهای «مبتنی بر محتوا» (Content Based)
- سیستمهای «ترکیبی» (Hybrid)
در ادامه این بخش، علاوهبر معرفی دقیقتر این سه روش، از مزایا و معایب آنها میگوییم و مثالی همراه با پیادهسازی به زبان برنامهنویسی پایتون برای هر کدام ارائه میدهیم.
سیستم های پالایش گروهی
پالایش گروهی فرایندی است که از طریق شناسایی اولویتها و اطلاعات جمعآوری شده، علایق احتمالی کاربران را شناسایی میکند. در واقع پالایش گروهی فرض میگیرد که اگر دو کاربر A و B سلیقه مشابهی نسبت به یک محصول خاص دارند، احتمالا نسبت به کالاهای دیگر نیز احساس مشترکی داشته باشند. در فهرست زیر به انواع رویکردهای مورد استفاده در پالایش گروهی اشاره شده است:

- رویکردهای مبتنی بر حافظه: این رویکردها با عنوان «پالایش گروهی مجاورت» (Neighbourhood Collaborative Filtering) نیز شناخته میشوند. در حقیقت امتیاز ترکیبات به اصطلاح «کاربر-محصول» (user-item) بر اساس نمونههای مجاور بهدست میآید. همین رویکرد را هم میتوان به دو گروه کوچکتر با نامهای پالایش گروهی «مبتنی بر کاربر» و پالایش گروهی «مبتنی بر محصول» تقسیم کرد. پالایش گروهی مبتنی بر کاربر به این معنی است که کاربران همسلیقه، پیشنهادات مشابهی دریافت میکنند. اما در پالایش مبتنی بر محصول، ابتدا با بهرهگیری از امتیاز کاربران، شباهت میان کالاها محاسبه شده و سپس محصولات پیشنهاد میشوند.
- رویکردهای مبتنی بر مدل: یا همان مدلهای پیشبینی کنندهای که از یادگیری ماشین استفاده میکنند. در این رویکرد ویژگیهای دیتاست به عنوان ورودی مدل و برای حل مسائل بهینهسازی بهکار گرفته میشوند. روشهای مبتنی بر مدل از الگوریتمهایی مانند درخت تصمیم و رویکردهای قاعده محور استفاده میکنند.
مزایا
پیادهسازی سیستمهای پالایش گروهی راحت است و در زمینههای مختلفی کاربرد دارند. از طرف دیگر، بدون نیاز به درک محتوای کالا، جزئیترین ویژگیها را نیز استخراج میکنند.
معایب
از جمله مهمترین معایب این سیستمها میتوان به ضعف در پیشنهاد کالاهای جدید اشاره کرد. زیرا هیچ تعاملی میان نمونه دادههای دیتاست با محصول جدیدی که قرار است پیشنهاد شود وجود ندارد. الگوریتمهای مبتنی بر حافظه در مقابل دیتاستهای کوچک عملکرد قابل قبولی از خود به نمایش نمیگذارند.
مثال
برخی از مثالهای رویکرد پالایش گروهی عبارتاند از:
- پیشنهاد محتوای ویدئویی در پلتفرم یوتوب به کاربران: هنگام استفاده از پلتفرم یوتوب، ویدئوهایی به شما توصیه میشود که به افراد همسلیقه شما نمایش داده شده و مورد استقبال قرار گرفتهاند.
- پیشنهاد دورههای آموزشی در پلتفرم کورسرا: پیشنهاد دورههای آموزشی در پلتفرم کورسرا، بر اساس میزان علاقهمندی کاربرانی که دورههای مشابه با شما را به اتمام رساندهاند انجام میشود.
پیاده سازی
ابتدا و از طریق قطعه کد زیر، دیتاستی با موضوع کتاب و متشکل از دادههای مصنوعی تولید میکنیم:
1import pandas as pd
2from random import randint
3
4
5def generate_data(n_books = 3000, n_genres = 10, n_authors = 450, n_publishers = 50, n_readers = 30000, dataset_size = 100000):
6 d = pd.DataFrame(
7 {
8 'book_id' : [randint(1, n_books) for _ in range(dataset_size)],
9 'author_id' : [randint(1, n_authors) for _ in range(dataset_size)],
10 'book_genre' : [randint(1, n_genres) for _ in range(dataset_size)],
11 'reader_id' : [randint(1, n_readers) for _ in range(dataset_size)],
12 'num_pages' : [randint(75, 700) for _ in range(dataset_size)],
13 'book_rating' : [randint(1, 10) for _ in range(dataset_size)],
14 'publisher_id' : [randint(1, n_publishers) for _ in range(dataset_size)],
15 'publish_year' : [randint(2000, 2021) for _ in range(dataset_size)],
16 'book_price' : [randint(1, 200) for _ in range(dataset_size)],
17 'text_lang' : [randint(1,7) for _ in range(dataset_size)]
18 }
19 ).drop_duplicates()
20 return d
21
22d = generate_data(dataset_size = 100000)
23d.to_csv('data.csv', index = False)این دیتاست شامل ۱۰۰ هزار سطر با ۱۰ ستون است که هر سطر اطلاعات مربوط به یک کاربر و کتابی که مطالعه کرده و به آن امتیاز داده است را نشان میدهد. سپس برای پیادهسازی الگوریتم پالایش گروهی از متد svdsکتابخانه SciPy استفاده میکنیم و با محاسبه شباهت میان کاربران و کتابها، ۳ کتاب پیشنهادی به کاربر شماره پنجم را در خروجی نمایش میدهیم:
1import numpy as np
2
3from scipy.sparse import csr_matrix
4from scipy.sparse.linalg import svds
5
6
7def normalize(pred_ratings):
8 '''
9 This function will normalize the input pred_ratings
10
11 params:
12 pred_ratings (List -> List) : The prediction ratings
13 '''
14 return (pred_ratings - pred_ratings.min()) / (pred_ratings.max() - pred_ratings.min())
15
16def generate_prediction_df(mat, pt_df, n_factors):
17 '''
18 This function will calculate the single value decomposition of the input matrix
19 given n_factors. It will then generate and normalize the user rating predictions.
20
21 params:
22 mat (CSR Matrix) : scipy csr matrix corresponding to the pivot table (pt_df)
23 pt_df (DataFrame) : pandas dataframe which is a pivot table
24 n_factors (Integer) : Number of singular values and vectors to compute.
25 Must be 1 <= n_factors < min(mat.shape).
26 '''
27
28 if not 1 <= n_factors < min(mat.shape):
29 raise ValueError("Must be 1 <= n_factors < min(mat.shape)")
30
31 # matrix factorization
32 u, s, v = svds(mat, k = n_factors)
33 s = np.diag(s)
34
35 # calculate pred ratings
36 pred_ratings = np.dot(np.dot(u, s), v)
37 pred_ratings = normalize(pred_ratings)
38
39 # convert to df
40 pred_df = pd.DataFrame(
41 pred_ratings,
42 columns = pt_df.columns,
43 index = list(pt_df.index)
44 ).transpose()
45 return pred_df
46
47def recommend_items(pred_df, usr_id, n_recs):
48 '''
49 Given a usr_id and pred_df this function will recommend
50 items to the user.
51
52 params:
53 pred_df (DataFrame) : generated from `generate_prediction_df` function
54 usr_id (Integer) : The user you wish to get item recommendations for
55 n_recs (Integer) : The number of recommendations you want for this user
56 '''
57
58 usr_pred = pred_df[usr_id].sort_values(ascending = False).reset_index().rename(columns = {usr_id : 'sim'})
59 rec_df = usr_pred.sort_values(by = 'sim', ascending = False).head(n_recs)
60 return rec_df
61
62if __name__ == '__main__':
63 # constants
64 PATH = 'data.csv'
65
66 # import data
67 df = pd.read_csv(PATH)
68 print(df.shape)
69
70 # generate a pivot table with readers on the index and books on the column and values being the ratings
71 pt_df = df.pivot_table(
72 columns = 'book_id',
73 index = 'reader_id',
74 values = 'book_rating'
75 ).fillna(0)
76
77 # convert to a csr matrix
78 mat = pt_df.values
79 mat = csr_matrix(mat)
80
81 pred_df = generate_prediction_df(mat, pt_df, 10)
82
83 # generate recommendations
84 print(recommend_items(pred_df, 5, 3))خروجی مانند زیر است:

همانطور که ملاحظه میکنید، بهترتیب کتابهایی با شناسه ۱۴۸۸، ۶۸۳ و ۱۲۴۴ به کاربر پنجم توصیه شدهاند.
سیستم های مبتنی بر محتوا
در سیستمهای مبتنی بر محتوا هر پیشنهاد مطابق با اولویت کاربران تولید میشود و هدف، پیشنهاد محصولاتی است که مورد پسند کاربران باشند. به بیان دیگر، این کاربران هستند که سطح شباهت میان محصولات را مشخص میکنند. برخلاف مدلهای پالایش گروهی که از امتیازات ثبت شده بین کاربر هدف (کاربری که قرار است محصولی به او پیشنهاد شود) و دیگر کاربران بهره میبرند، در سیستمهای مبتنی بر محتوا تنها امتیازات کاربر هدف اهمیت دارد. سیستمهای مبتنی بر محتوا از منابع مختلفی برای توصیه یک محصول استفاده میکنند که در فهرست زیر به دو مورد از سادهترین آنها اشاره شده است:

- منابع داده در سطح محصول: دسترسی به منابع داده با ویژگیهای کامل در مورد محصولات ضروری است. به عنوان مثال در دیتاست ما، هر سطر از ویژگیهایی مانند قیمت کتاب، تعداد صفحات و سال انتشار تشکیل شده است. هر چه اطلاعات بیشتری از محصولات در اختیار داشته باشید، عملکرد نهایی سیستم قابل اعتمادتر خواهد بود.
- منابع داده در سطح کاربر: برای محصولی که قرار است توصیه شود، به نوعی بازخورد از طرف کاربران نیاز داریم. بازخوردی که میتواند بهشکل صریح یا ضمنی ثبت شده باشد. در دیتاستی که پیشتر ایجاد کردیم، بازخورد کاربران در قالب امتیاز به کتابها ذخیره شده است. هرچه بازخورد بیشتری از کاربران جمعآوری شود، سیستم مبتنی بر محتوا نتایج دقیقتری نشان میدهد.
مزایا
زمانی استفاده از مدلهای مبتنی بر محتوا پیشنهاد میشود که حجم دادههایی که از جنس امتیاز و بازخورد هستند کم باشد. چرا که ممکن است محصولات مشابه دیگر، امتیازدهی شده باشند. در نتیجه حتی اگر تعداد دادهها کم باشد، مدل این توانایی را دارد تا با بهرهگیری از امتیاز محصولات به فعالیت خود ادامه دهد.
معایب
از جمله اصلیترین معایب سیستمهای مبتنی بر محتوا میتوان به موارد زیر اشاره داشت:
- پیشبینی موارد پیشنهادی راحت است. از این موضوع به عنوان یکی از معایب سیستمهای مبتنی بر محتوا یاد میشود، زیرا تنها محتوا یا محصولاتی به کاربر توصیه میشود که از قبل با آنها تعامل داشته است. به عنوان مثال اگر هیچ کتابی از ژانر معمایی نخوانده باشید، سیستم هرگز این گروه از کتابها را به شما پیشنهاد نمیدهد. عملکرد چنین مدلهایی برای هر کاربر متفاوت بوده و از اطلاعات افراد مشابه استفاده نمیشود. از همین جهت تنوع گزینههای پیشنهادی پایین خواهد بود که نکتهای منفی برای بسیاری از کسبوکارها بهشمار میرود.
- برای پیشنهاد به کاربران جدید مناسب نیستند. هنگام طراحی و ساخت مدل، به تاریخچهای از دادهها در سطح کاربر و برای محصولات نیاز دارید. بسیار مهم است که دیتاستی بزرگ از بازخوردها و امتیازات در اختیار داشته باشید. اینگونه احتمال «بیشبرازش» کاهش یافته و خروجی موثرتری حاصل میشود.
مثال
برخی از مثالهای موفق سیستمهای مبتنی بر محتوا عبارتاند از:
- سرویس پیشنهاد کالا وبسایت آمازون
- سرویس پیشنهاد موسیقی پلتفرم اسپاتیفای
پیاده سازی
برای پیادهسازی این روش، ابتدا دادهها را از فایل دیتاست با عنوان data.csv بارگذاری میکنیم. در ادامه و پس از نرمالسازی سه ویژگی book_price، book_rating و num_pages که به ترتیب بیانگر امتیاز، قیمت و تعداد صفحات کتاب هستند، سه ویژگی دیگر را با عنوانهای publish_year، book_genre و text_lang به روش «وان هات» کدبندی میکنیم و با محاسبه معیار «شباهت کسینوسی»، پنج کتابی که بیشترین شباهت را با کتاب اول دارند در خروجی نمایش میدهیم:
1from numpy import dot
2from numpy.linalg import norm
3
4
5def normalize(data):
6 '''
7 This function will normalize the input data to be between 0 and 1
8
9 params:
10 data (List) : The list of values you want to normalize
11
12 returns:
13 The input data normalized between 0 and 1
14 '''
15 min_val = min(data)
16 if min_val < 0:
17 data = [x + abs(min_val) for x in data]
18 max_val = max(data)
19 return [x/max_val for x in data]
20
21def ohe(df, enc_col):
22 '''
23 This function will one hot encode the specified column and add it back
24 onto the input dataframe
25
26 params:
27 df (DataFrame) : The dataframe you wish for the results to be appended to
28 enc_col (String) : The column you want to OHE
29
30 returns:
31 The OHE columns added onto the input dataframe
32 '''
33
34 ohe_df = pd.get_dummies(df[enc_col])
35 ohe_df.reset_index(drop = True, inplace = True)
36 return pd.concat([df, ohe_df], axis = 1)
37
38class CBRecommend():
39 def __init__(self, df):
40 self.df = df
41
42 def cosine_sim(self, v1,v2):
43 '''
44 This function will calculate the cosine similarity between two vectors
45 '''
46 return sum(dot(v1,v2)/(norm(v1)*norm(v2)))
47
48 def recommend(self, book_id, n_rec):
49 """
50 df (dataframe): The dataframe
51 song_id (string): Representing the song name
52 n_rec (int): amount of rec user wants
53 """
54
55 # calculate similarity of input book_id vector w.r.t all other vectors
56 inputVec = self.df.loc[book_id].values
57 self.df['sim']= self.df.apply(lambda x: self.cosine_sim(inputVec, x.values), axis=1)
58
59 # returns top n user specified books
60 return self.df.nlargest(columns='sim',n=n_rec)
61
62if __name__ == '__main__':
63 # constants
64 PATH = 'data.csv'
65
66 # import data
67 df = pd.read_csv(PATH)
68
69 # normalize the num_pages, ratings, price columns
70 df['num_pages_norm'] = normalize(df['num_pages'].values)
71 df['book_rating_norm'] = normalize(df['book_rating'].values)
72 df['book_price_norm'] = normalize(df['book_price'].values)
73
74 # OHE on publish_year and genre
75 df = ohe(df = df, enc_col = 'publish_year')
76 df = ohe(df = df, enc_col = 'book_genre')
77 df = ohe(df = df, enc_col = 'text_lang')
78
79 # drop redundant columns
80 cols = ['publish_year', 'book_genre', 'num_pages', 'book_rating', 'book_price', 'text_lang']
81 df.drop(columns = cols, inplace = True)
82 df.set_index('book_id', inplace = True)
83
84 # ran on a sample as an example
85 t = df.copy()
86 cbr = CBRecommend(df = t)
87 print(cbr.recommend(book_id = t.index[0], n_rec = 5))خروجی مانند جدول زیر است:
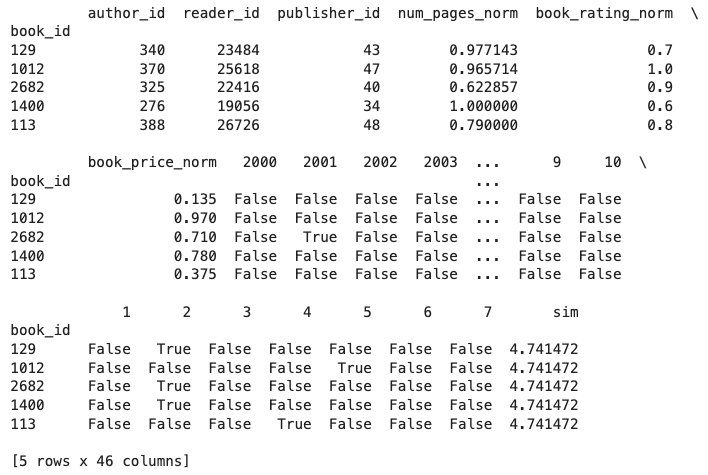
مطابق با آنچه در خروجی مشاهده میشود، پنج کتاب با شناسههای ۱۲۹، ۱۰۱۲، ۲۶۸۲، ۱۴۰۰ و ۱۱۳ بیشترین شباهت را با اولین کتاب دیتاست دارند.
سیستم های ترکیبی
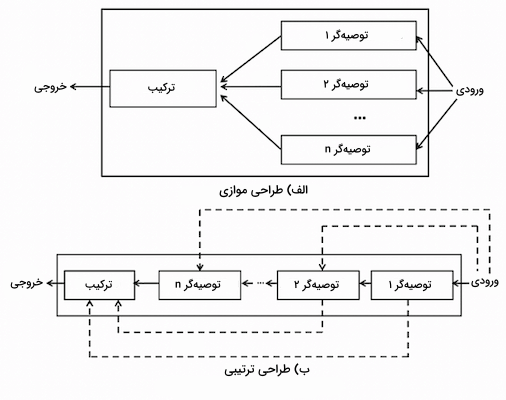
تا اینجا یاد گرفتیم منظور از سیستم توصیه گر چیست و با دو نوع پالایش گروهی و مبتنی بر محتوا نیز آشنا شدیم. هر کدام از این رویکردها مزایا و معایب منحصر به خود را دارند. محدودیت این روشها زمانی بیشتر به چشم میخورد که منابع اطلاعاتی زیادی برای مسئله موجود باشد. طراحی سیستمهای ترکیبی به نحوی است که از دیتاستهای مختلف برای نتیجهگیری کارآمد استفاده میشود. بهطور عمده طراحی سیستمهای ترکیبی به دو روش «موازی» و «ترتیبی» صورت میگیرد. در طراحی موازی، نمونههای ورودی به چند سیستم توصیهگر متفاوت ارسال شده و با ترکیب نتایج این سیستمها، یک خروجی واحد بهدست میآید. در طراحی ترتیبی اما، سیستمهای توصیهگر در امتداد یکدیگر قرار داشته و خروجی هر سیستم، نقش ورودی سیستم دیگر را دارد. در تصویر زیر نمایش دقیقتری از این دو طراحی مشاهده میکنید:
مزایا
با ترکیب چند مدل متفاوت در رویکرد ترکیبی، تلاش میشود تا معایب هر تک مدل جبران شود. در نتیجه عملکرد نهایی بهبود یافته و به پیشنهادهای مفیدتری برای کاربران منجر میشود.
معایب
پیچیدگی محاسباتی این قبیل از مدلها زیاد بوده و برای بهروز ماندن به حجم بالایی از دادهها نیاز دارند. در صورت نادیده گرفتن معیارهای بهروزرسانی مانند امتیاز و میزان تعامل کاربر، ارائه پیشنهادهای جدید و موثر دشوار خواهد بود.
مثال
پلتفرم نتفلیکس از سیستمهای ترکیبی برای پیشنهاد فیلم به کاربران خود استفاده میکند. پیشنهاد فیلم در این سیستم مطابق با سلیقه کاربران مشابه (پالایش گروهی) و فیلمهایی که مشخصات کموبیش یکسانی دارند انجام میشود.
پیاده سازی
مانند قبل، دیتاست را بارگذاری میکنیم و از یک مدل مبتنی بر محتوا یا همان شباهت کسینوسی برای بهدست آوردن ۵۰ مورد از شبیهترین کتابها کمک میگیریم. سپس و با استفاده از مدل پالایش گروهی، امتیازهای احتمالی کاربران را به ۵۰ کتاب انتخابی محاسبه میکنیم. در انتها ۵ مورد از کتابهایی که بالاترین امتیاز پیشبینی شده را دارند در خروجی برمیگردانیم:
1from sklearn.metrics.pairwise import cosine_similarity
2from surprise import SVD, Reader, Dataset, accuracy
3from surprise.model_selection import train_test_split
4
5
6def hybrid(reader_id, book_id, n_recs, df, cosine_sim, svd_model):
7 '''
8 This function represents a hybrid recommendation system, it will have the following flow:
9 1. Use a content-based model (cosine_similarity) to compute the 50 most similar books
10 2. Compute the predicted ratings that the user might give these 50 books using a collaborative
11 filtering model (SVD)
12 3. Return the top n books with the highest predicted rating
13
14 params:
15 reader_id (Integer) : The reader_id
16 book_id (Integer) : The book_id
17 n_recs (Integer) : The number of recommendations you want
18 df (DataFrame) : Original dataframe with all book information
19 cosine_sim (DataFrame) : The cosine similarity dataframe
20 svd_model (Model) : SVD model
21 '''
22 # sort similarity values in decreasing order and take top 50 results
23 sim = list(enumerate(cosine_sim[int(book_id)]))
24 sim = sorted(sim, key=lambda x: x[1], reverse=True)
25 sim = sim[1:50]
26
27 # get book metadata
28 book_idx = [i[0] for i in sim]
29 books = df.iloc[book_idx][['book_id', 'book_rating', 'num_pages', 'publish_year', 'book_price', 'reader_id']]
30
31 # predict using the svd_model
32 books['est'] = books.apply(lambda x: svd_model.predict(reader_id, x['book_id'], x['book_rating']).est, axis = 1)
33
34 # sort predictions in decreasing order and return top n_recs
35 books = books.sort_values('est', ascending=False)
36 return books.head(n_recs)
37
38if __name__ == '__main__':
39 # constants
40 PATH = 'data.csv'
41
42 # import data
43 df = pd.read_csv(PATH)
44
45 # content based
46 rmat = df.pivot_table(
47 columns = 'book_id',
48 index = 'reader_id',
49 values = 'book_rating'
50 ).fillna(0)
51
52 #Compute the cosine similarity matrix
53 cosine_sim = cosine_similarity(rmat, rmat)
54 cosine_sim = pd.DataFrame(cosine_sim, index=rmat.index, columns=rmat.index)
55
56 # collaborative filtering
57 reader = Reader()
58 data = Dataset.load_from_df(df[['reader_id', 'book_id', 'book_rating']], reader)
59
60 # split data into train test
61 trainset, testset = train_test_split(data, test_size=0.3,random_state=10)
62
63 # train
64 svd = SVD()
65 svd.fit(trainset)
66
67 # run the trained model against the testset
68 test_pred = svd.test(testset)
69
70 # get RMSE
71 accuracy.rmse(test_pred, verbose=True)
72
73 # generate recommendations
74 r_id = df['reader_id'].values[0]
75 b_id = df['book_id'].values[0]
76 n_recs = 5
77 print(hybrid(r_id, b_id, n_recs, df, cosine_sim, svd))خروجی اجرای قطعه کد فوق مانند زیر است:
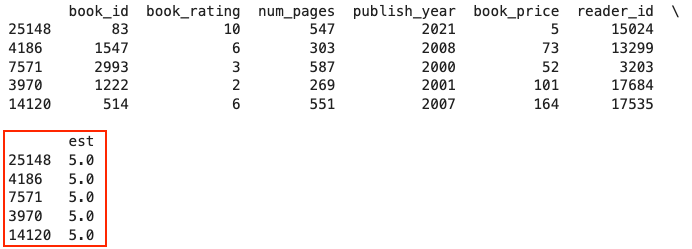
همانطور که در تصویر نیز با رنگ قرمز مشخص شده است، انتظار میرود پنج کتاب با شناسههای ۲۵۱۴۸، ۴۱۸۶، ۷۵۷۱، ۳۹۷۰ و ۱۴۱۲۰ بیشترین امتیاز را از کاربران کسب کنند.
کاربرد های سیستم توصیه گر
پس از پاسخ دادن به پرسش سیستم توصیه گر چیست و پیادهسازی سه رویکرد پالایش گروهی، مبتنی بر محتوا و ترکیبی، در این بخش از مطلب مجله فرادرس و فهرست زیر به شرح برخی از کاربردهای سیستم توصیهگر میپردازیم:
- تجارت الکترونیک: کاربری را تصور کنید که یک شال خریده است. هنگام خرید از وبسایتهای فروشگاهی، بخشی با عنوان «شاید به این محصولات نیز علاقهمند باشید» وجود دارد که مثالی از سیستمهای توصیهگر است و در چنین موقعیتی، یعنی همراه با خرید شال، کلاهی نیز به خریدار پیشنهاد میشود.
- رسانه و سرگرمی: سامانههای توصیهگر این توانایی را دارند تا خریدهای انجام شده را ارزیابی کرده و با شناسایی الگوهای رفتاری، محتوای مناسبی به کاربران پیشنهاد دهند. شرکتهای گوگل، فیسبوک و نتفلیکس از همین روش برای نمایش تبلیغات و همچنین فیلمها و سریالها استفاده میکنند.
- امور مالی: توجه به امور مالی در توصیه محصولاتی که میلیونها مصرفکننده دارند بسیار حائز اهمیت است. آشنایی با شرایط مالی مشتری و اولویتهای او در ترکیب با دادههای هزاران کاربر مشابه، نتیجهای جز یک سیستم توصیهگر کارآمد ندارد.
مزایا سیستم یا سامانه توصیه گر چیست؟
سیستمهای توصیهگر بخش اساسی از هر نوع تجربه کاربری، تعامل عمیقتر با مشتری و ابزارهای تصمیمگیری موثر در حوزههایی همچون خدمات درمانی، سرگرمی و امور مالی هستند. گاهی سیستمهای توصیهگر تا ۳۰ درصد از درآمد سالانه شرکتهای بزرگ تبلیغاتی را پوشش میدهند. بنابراین حتی بهبود ۱ درصدی در کیفیت سیستمهای توصیهگر نیز با سود چند میلیاردی برابری میکند. شرکتها به دلایل مختلفی دست به پیادهسازی سیستمهای توصیهگر میزنند از جمله:
- حفظ کاربر: با پاسخگویی مداوم به خواستهها و نیاز کاربران، رفته رفته به داراییهای وفادار و ماندگار برای سازمان تبدیل میشوند. کاربران و مشتریهایی که میدانند برای شرکت ارزشمند هستند.
- افزایش فروش: تحقیقات مختلفی نشان میدهند که توصیه محصولات مشابه با علاقهمندیهای کاربر به رشد ۱۰ تا ۵۰ درصدی در سود شرکت منجر میشود. نمایش محصولات مشابه هنگام تسویه حساب و اشتراکگذاری بازخوردها و خرید دیگران، از جمله راهکارهایی است که میزان فروش را افزایش میدهد.
- جهتدهی به گرایش بازار: تداوم در ارائه پیشنهادات مرتبط و دقیق باعث شکل گرفتن عادتهای رفتاری شده و الگوی خرید کاربران را تحت تاثیر قرار میدهد.
- تجزیه و تحلیل سریعتر: با ارائه کالاهای از پیش پردازش شده به کاربران، سرعت تجزیه و تحلیل دادهها تا ۸۰ درصد افزایش مییابد.
- افزایش ارزش سبد خرید: روزانه حجم بالایی از محصولات وارد انبار شرکتهای بزرگ فروشگاهی میشود. این شرکتها با بهرهگیری از سیستمهای توصیهگر میتوانند در زمان مناسب و از طریق وبسایت یا راههای ارتباطی دیگر مانند ایمیل، محصولات جدید خود را در معرض دید کاربر قرار دهند.
سیستم توصیه گر چگونه کار می کند؟
حالا که بهخوبی میدانید سیستم توصیه گر چیست، باید توجه داشته باشید که نحوه کارکرد این سیستمها به نوع داده ورودی بستگی دارد. اگر اطلاعات جدیدی در اختیار نداشته و تنها تعاملات گذشته کاربران را ثبت کردهاید، بهتر است از رویکرد پالایش گروهی استفاده کنید. از طرف دیگر، ممکن است دادههای شما بیانگر ارتباط میان کاربر و محصول باشند که در این صورت میتوانید از رویکرد مبتنی بر محتوا برای مدلسازی تعاملات جدید بهرهمند شوید.
رویکرد های مورد استفاده در سیستم توصیه گر
تا اینجا میدانیم سیستم یا سامانه توصیه گر چیست، چگونه کار میکند و چه کاربرد و مزایایی دارد. در این بخش اما، کمی بیشتر با جزییات و رویکردهایی که برای پیادهسازی انواع سیستمهای توصیهگر مورد استفاده قرار میگیرند آشنا میشویم.

تجزیه ماتریس
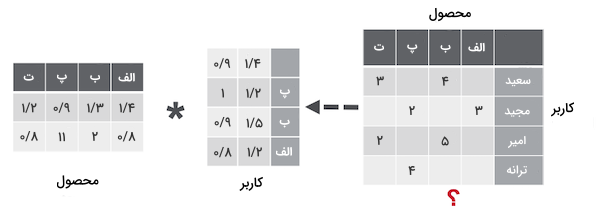
تکنیکهای «تجزیه ماتریس» (Matrix Factorization) پایه و اساس الگوریتمهای محبوب بسیاری از جمله «تعبیهسازی واژگان» (Word Embedding) و «مدلسازی موضوعی» (Topic Modeling) هستند و به عنوان رویکردی موثر در سیستمهای توصیهگر پالایش گروهی از آنها یاد میشود. بهطور معمول از تجزیه ماتریس برای محاسبه شباهت در تعاملات میان کاربران و در نهایت پیشنهاد محصول کمک میگیرند. در ماتریس کاربر-محصول ساده زیر، سعید و مجید هر دو فیلمهای «ب» و «پ» را دوست دارند. همچنین امیر به فیلم «ب» علاقهمند است. با بهکارگیری روش تجزیه ماتریس به این نتیجه میرسیم که اگر فردی فیلم «ب» را دوست داشته است، به احتمال زیاد به فیلم «پ» نیز علاقهمند بوده و در نتیجه فیلم «پ» به کاربر امیر پیشنهاد میشود.

در روش تجزیه ماتریس از الگوریتم «کمترین مربعات متناوب» (Alternating Least Squares | ALS) برای تخمین ماتریس خلوت کاربر-محصول با ابعاد در استفاده میشود. این ماتریس از حاصل ضرب دو ماتریس متراکم «کاربر» و «محصول» با ابعاد در و در بهدست میآید و دو نماد و به ترتیب برابر با تعداد کاربران و تعداد محصولات هستند. دو ماتریس کاربر و محصول، ویژگیهایی را از کاربران و محصولات به نمایش میگذارند که الگوریتم در تلاش برای کشف آنها است. الگوریتم ALS برای هر کاربر و محصول، بهطور مداوم «عاملهای» (Factors) عددی را یاد میگیرد که با حرف مشخص شده است. در هر دور از اجرای الگوریتم و تا زمانی که ماتریسها همگرا شوند، یکی از ماتریسها (کاربر یا محصول) بهینهسازی میشود.
مدل های شبکه عصبی عمیق
شبکههای عصبی عمیق از انواع مختلفی تشکیل شدهاند که در فهرست زیر برخی از آنها را معرفی کردهایم:
- جریان اطلاعات و بهطور کلی فرایند آموزش در برخی از شبکههای عصبی از یک لایه به لایه دیگر جریان داشته با عنوان «شبکههای عصبی پیشخور» (Feedforward Neural Networks) شناخته میشوند. از جمله این شبکهها میتوان به شبکههای چندلایه پرسپترون اشاره کرد که از حداقل سه لایه «ورودی»، «مخفی» و «خروجی» تشکیل شدهاند. از شبکههای پرسپترون برای حل مسائل متنوعی استفاده میشود.
- «شبکههای عصبی پیچشی» (CNN) در شناسایی و تشخیص محتوای تصویری کاربرد دارند.
- «شبکههای عصبی بازگشتی» (RNN) در حقیقت موتورهای ریاضیاتی هستند که دادههای دنبالهدار و الگوهای زبانی را تجزیه میکنند.
مدلهای توصیهگر یادگیری عمیق از تکنیکهای موجود مانند تجزیه ماتریس برای مدلسازی ارتباط میان متغیرها و بردارهای «تعبیه شده» (Embeddings) بهره میبرند. یک بردار تعبیه شده، مجموعهای از اعداد است که در آن فاصله کمی میان موجودیتهای مشابه مانند کاربران یا محصولات وجود دارد. اگر میخواهید اطلاعات بیشتری در رابطه با یادگیری عمیق کسب کنید، میتوانید مطلب مجله فرادرس در رابطه با این موضوع را مطالعه کنید.
پالایش گروهی عصبی
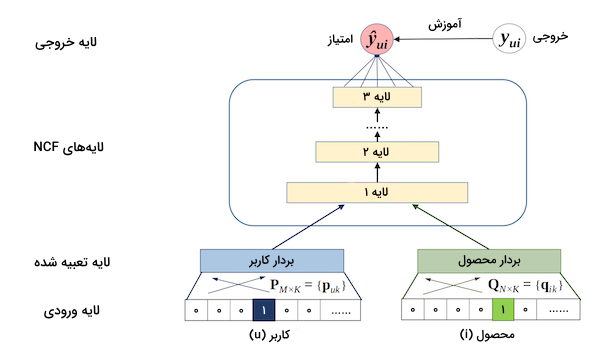
مدل «پالایش گروهی عصبی» (Neural Collaborative Filtering | NCF) یک شبکه عصبی است که بر اساس تعاملات میان کاربر و محصول، امکان پالایش گروهی را فراهم میکند. در مدل NCF، عمل تجزیه ماتریس بر روی دنبالهای از جفت ورودیهای متشکل از اطلاعات کاربر و محصول اعمال شده و همزمان به یک شبکه پرسپترون نیز منتقل میشوند. پس از ترکیب نتیجه شبکه پرسپترون و تجزیه ماتریس و انتقال به یک لایه متراکم، خروجی یا همان احتمال تعامل کاربر با محصول بهدست میآید.
خود رمزگذار متغیر
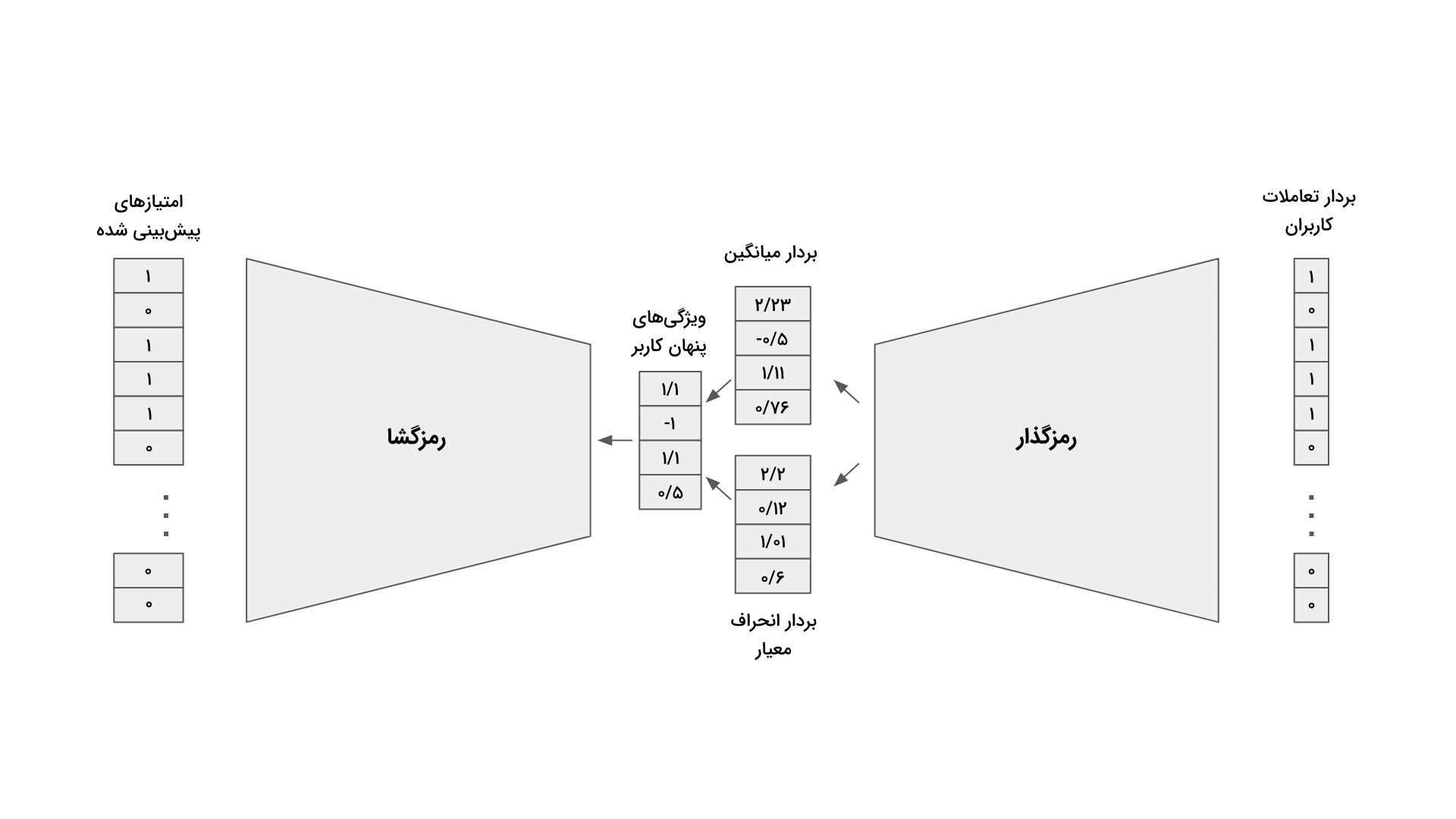
شبکه عصبی «خود رمزگذار» (Autoencoder) با کمک درک حاصل از لایه مخفی، به نوعی لایه ورودی را در لایه خروجی بازسازی میکند. همچنین در پالایش گروهی و با یادگیری سیستم خود رمزگذار از ماتریس کاربر-محصول است که مقادیر گمشده جایگذاری میشوند. «خود رمزگذار متغیر» پیادهسازی بهینهای برای رویکرد پالایش گروهی است که در آن از جفت دادههای کاربر-محصول برای آموزش مدل استفاده میشود. هر مدل از دو بخش «رمزگذار» (Encoder) و «رمزگشا» (Decoder) تشکیل شده است. بخش رمزگذار، یک شبکه «کامل متصل» (Fully Connected) است که بردار ورودی را به یک توزیع متغیر بعدی تبدیل میکند. از این توزیع برای بهدست آوردن ویژگیهای پنهان کاربر استفاده میشود و سپس به بخش دوم یعنی رمزگشا که مانند بخش اول، نوعی شبکه پیشخور یا Feedforward است انتقال مییابند. خروجی به شکل بردار احتمالاتی از تعاملات کاربر با محصول نمایش داده میشود.
یادگیری توالی متنی
شبکه عصبی بازگشتی یا RNN زیرمجموعهای از شبکههای عصبی با حافظه یا «حلقههای بازخورد» (Feedback Loops) است که امکان بازشناسی الگوهای موجود در دادهها را تسهیل میکند. از جمله کاربردهای RNN میتوان به «پردازش زبان طبیعی» (NLP) و همچنین سیستمهای پیشنهاد «توالی متنی» (Contextual Sequence) اشاره کرد. وجه تمایز یادگیری توالی با سایر رویکردها، در نیاز به استفاده از مدلهایی با حافظه فعال مانند «حافظه طولانی کوتاه مدت» (Long Short Term Memory | LSTM) یا «واحدهای بازگشتی گِیتی» (Gated Recurrent Units | GRU) برای یادگیری وابستگیهای زمانی است. چنین اطلاعاتی برای موفقیت سیستمی که بر پایه یادگیری توالی طراحی شده است بسیار اهمیت دارند. مدلهای «ترنسفورمر» (Transformer) مانند BERT، جایگزینی برای شبکههای عصبی بازگشتی هستند که از مکانیزم «توجه» یا Attention برای تجزیه و توجه به واژگان قبل و بعد از هر جمله استفاده میکنند. مدلهای یادگیری عمیقِ مبتنی بر ترنسفورمر نیازی به داده ترتیبی ندارند و از همین جهت، زمان لازم برای آموزش بسیار کاهش مییابد.

در پردازش زبان طبیعی با استفاده از تکنیکهایی مانند تعبیهسازی واژگان، متن ورودی به چند بردار واژه تبدیل میشود. به بیان ساده، پیش از ارسال ورودی به شبکه RNN، هر واژه به مجموعهای از اعداد قابل فهم برای ترنسفورمر تبدیل میشود. سپس طی فرایند آموزش شبکه عصبی و رمزگذاری اطلاعات متنی، واژگان مشابه به یکدیگر نزدیکتر شده و در مقابل، واژگان متفاوت از هم فاصله بگیرند. عمده کاربرد این مدلها در پیشبینی واژگان و خلاصهسازی متن است. در مثال پیشنهاد فیلم، پس از بهکارگیری رویکرد مبتنی بر محتوا، مجموعه اعداد بهدست آمده برای درک محتوا به یکی از انواع RNN مانند LSTM، GRU یا ترنسفورمرها میشود.

شبکههای عصبی عمیق و یادگیری عمیق نقش مهمی در پیشرفت سیستمهای توصیهگر ایفا میکنند. تکنیکهایی که توانایی سیستمهای توصیهگر را در فهم و درک الگوهای پیچیده و همچنین ارائه پیشنهادات دقیقتر بهطور چشمگیری افزایش دادهاند. شبکههای عصبی عمیق قادر هستند روابط غیرخطی پیچیده میان دادهها را یاد بگیرند و از این طریق، عملکرد سیستمهای توصیهگر را بهبود بخشند.
یادگیری عمیق، به عنوان زیرمجموعهای از هوش مصنوعی، با الهام از مغز انسان، امکان پردازش حجم عظیمی از دادهها و استخراج ویژگیهای مهم را فراهم میکند. قابلیتی که در سیستمهای توصیهگر منجر به ارائه پیشنهادات شخصیسازی شده و دقت بالا میرود. اگر قصد دارید به شکل جامع و کاربردی به پیادهسازی انواع شبکههای عصبی با پایتون بپردازید و بهطور عملی با یادگیری عمیق آشنا شوید، پیشنهاد میکنیم به فیلمهای آموزشی تهیه شده توسط پلتفرم فرادرس که در ادامه قرار گرفته است مراجعه کنید:
جمعبندی
با وجود تمام پیشرفتهای صورت گرفته، روزانه کسبوکارهای بسیاری برای بهبود عملکرد سامانههای توصیهگر در تلاش هستند. این سامانهها با گذشت زمان در حوزههای بیشتری بهکار گرفته میشوند. در این مطلب از مجله فرادرس یاد گرفتیم منظور از سیستم توصیه گر چیست و با انواع و نحوه پیادهسازی هر کدام نیز آشنا شدیم. سیستمهایی که هم برای کاربر و هم سازمان مزایای فراوانی دارند.
source