۳۳ بازدید
آخرین بهروزرسانی: ۱۳ تیر ۱۴۰۳
زمان مطالعه: ۱۰ دقیقه
صرفنظر از اهمیت و نوع دیتاست، در بیشتر مواقع تنها کمتر از ۱ درصد دادهها را اطلاعات نادر و منحصربهفرد تشکیل میدهند. به عنوان مثال در زمینههایی مانند کشف تخلفات بانکی و بازاریابی آنلاین، متخلفان کمی از کارت بانکی استفاده میکنند یا بهندرت پیش میآید کاربری بر روی تبلیغات غیرمرتبط کلیک کند. با این حال، زمانی عملکرد الگوریتمهای یادگیری ماشین بهینه و قابل اتکا خواهد بود که این «داده های نامتوازن» (Imbalanced Data) مدیریت شوند. در این مطلب از مجله فرادرس یاد میگیریم منظور از داده های نامتوازن چیست و از چه تکنیکهایی برای مدیریت آنها استفاده میشود.


در این مطلب، ابتدا با مفهوم داده های نامتوازن آشنا میشویم و به شرح چالشهای مدیریت این دادهها میپردازیم. در ادامه یاد میگیریم که چرا باید به داده های نامتوازن رسیدگی شود و پس از معرفی ۷ تکنیک رایج برای مدیریت داده های نامتوازن، به برخی از پرسشهای متداول پیرامون این حوزه پاسخ میدهیم.
داده های نامتوازن چیست و چگونه مدیریت می شوند؟
وجود «داده های نامتوازن» (Imbalanced Data) به دیتاستهایی اشاره دارد که در آنها توزیع کلاس هدف از دادهها نابرابر است. به بیان سادهتر، در حالی یک کلاس نمونههای بسیار زیادی دارد که کلاس دیگر فاقد حداقل داده مورد نیاز است. برای درک بهتر نحوه مدیریت داده های نامتوازن، بانکی را در نظر بگیرید که برای مشتریهای خود کارت اعتباری صادر میکند. حالا و از آنجا که این بانک متوجه جعلی بودن برخی از تراکنشها شده است، به سراغ بررسی دادهها رفته و مشخص میشود که در میان هر ۲۰۰۰ تراکنش، تنها ۳۰ مورد مشکوک وجود دارد. یعنی بهازای هر ۱۰۰ تراکنش، کمتر از ۲ درصد یا بیشتر از ۹۸ درصد بدون مشکل هستند. در اینجا اگر دادهها را به دو گروه «عادی» و «مشکوک» تقسیم کنیم، کلاس عادی را «اکثریت» (Majority) و کلاس مشکوک را «اقلیت» (Minority) مینامند.

در سایر مسائل طبقهبندی مانند تشخیص بیماری، نرخ ریزش مشتری و بلایای طبیعی نیز مشکل داده های نامتوازن دیده میشود. با این حال گاهی شدت عدم توازن زیاد بوده و کلاس اکثریت، اختلاف چشمگیری با کلاس اقلیت دارد.
چالش های مدیریت داده های نامتوازن
داده های نامتوازن در دقت پیشبینی مدلهای یادگیری ماشین تاثیرگذار هستند. مسئله تشخیص بیماری را در نظر بگیرید. در این مسئله، پیشبینی بر اساس دیتاستی انجام میشود که در آن بهازای هر ۱۰۰ مراجعهکننده، تنها ۵ شخص بیمار وجود دارند. پس کلاس اکثریت ۹۵ و ۵ درصد از دیتاست را کلاس اقلیت (بیمار) تشکیل میدهد. حالا فرض کنید مدل یادگیری ما هر ۱۰۰ مورد را بیمار تشخیص دهد. گاهی اوقات اگر تعداد نمونههای یک کلاس از سایر کلاسها بیشتر باشد، پیشبینیهای مدل یا «دستهبند» (Classifier) به سمت کلاس غالب سوگیری پیدا میکند. برای یادگیری بیشتر درباره خطای دستهبند، میتوانید فیلم آموزش تخمین خطای طبقهبندی فرادرس که لینک آن در ادامه آورده شده است را مشاهده کنید:

اگر بخواهیم برای ارزیابی عملکرد مدل از معیاری مانند «ماترسی درهم ریختگی» (Confusion Matrix) کمک بگیریم، باید تعداد پیشبینیهای درست را بر کل پیشبینیها تقسیم کنیم. در مورد مثال ما، ۹۵ نمونه در کلاس «منفی درست» (True Negative | TN) قرار گرفته و تعداد کل پیشبینیها نیز برابر با ۱۰۰ است. یعنی با وجود اینکه مدل نمیتواند نمونههای کلاس اقلیت را شناسایی کند، همچنان دقتی برابر با ۹۵ درصد خواهد داشت. پس میتوان نتیجه گرفت که با وجود داده های نامتوازن، استفاده از روشهای قدیمی مانند ماتریس درهم ریختگی برای ارزیابی دقت مدل، توجیهی نداشته و ممکن است در مسائل حساس به پیشبینیهایی با عوارض غیرقابل جبران منجر شود.
آموزش روش های نمونه گیری با فرادرس

یکی از چالشهای رایج در پروژههای یادگیری ماشین، مواجهه با داده های نامتوازن است. دادههایی که در آنها توزیع نمونهها در کلاسهای مختلف یکسان نیست و تعداد نمونهها در یک یا چند کلاس بهمراتب کمتر از سایر کلاسها است. این مسئله میتواند موجب کاهش دقت مدلهای یادگیری ماشین در پیشبینی کلاسهای کمجمعیت شود. یکی از راهکارهای مقابله با این مشکل، استفاده از تکنیکهای «نمونهگیری» (Sampling) است. از طریق تکنیکهای نمونهگیری میتوان دادهها را به نمونههای متوازنتری برای آموزش مدل با دقت بیشتر تبدیل کرد.
در این زمینه از زبانهای برنامه نویسی آماری مانند R و ابزارهای تحلیلی همچون نرمافزار Statgraphics استفاده میشود. بهدلیل اهمیت مدیریت داده های نامتوازن و یادگیری روشهای نمونهگیری، وبسایت فرادرس فیلمهای آموزشی جامع و مرتبطی را با این حوزه تهیه و تولید کرده است که لینک آنها در ادامه قرار گرفته است:
همچنین اگر مایلید بیشتر در مورد دیگر روشها و رویکردهای آماری علم داده اطلاعات کسب کنید، مشاهده مجموعه فیلمهای آموزش آمار و احتمالات فرادرس که لینک آن در بخش زیر آورده شده است را به شما پیشنهاد میکنیم:
چرا باید به داده های نامتوازن رسیدگی شود؟
لازم است تا به داده های نامتوازن رسیدگی شود چرا که باعث ایجاد سوگیری در مدلها شده و دقت پیشبینیها را تحت تاثیر قرار میدهند. در فهرست زیر به چند نمونه از مشکلات و چالشهایی که در نتیجه داده های نامتوازن بهوجود میآیند اشاره شده است:

- «توزیع کلاسی نامتقارن» (Skewed Class Distribution): همانطور که پیشتر نیز اشاره شد، زمانی میگوییم یک دیتاست نامتوازن است که اختلاف چشمگیری میان تعداد نمونههای هر کلاس وجود داشته باشد. در نتیجه، فرایند یادگیری مدل به اصطلاح نامتقارن شده و با اولویت قرار دادن کلاس اکثریت، قادر به شناسایی و پیشبینی درست نمونههای اقلیت نخواهد بود.
- آموزش سوگیرانه مدل: هدف مدلهای یادگیری ماشین به حداقل رساندن انواع خطاهای اندازهگیری شده با معیارهایی مانند «صحت» (Accuracy) است. در مواجهه با دادههای نامتقارن، مدل میتواند کلاس اقلیت را نادیده گرفته و تنها با پیشبینی کردن کلاس اکثریت برای همه دادهها به دقت بالایی برسد. بنابراین مدل نسبت به کلاس اکثریت سوگیری داشته و نمیتواند الگوهای موجود در سایر دادهها را شناسایی کند.
- قابلیت تعمیم ضعیف: از دیگر نتایج داده های نامتوازن میتوان به عملکرد ضعیف مدلها نسبت به دادههای جدید اشاره کرد. با توجه به اینکه مدل در طول فرایند آموزش با دادههای کمی از کلاس اقلیت روبهرو میشود، ممکن است نتواند دادههای مشابه را در کاربردهای حقیقی به درستی پیشبینی و طبقهبندی کند.
- خطاهای پرهزینه: در بسیاری از مسائل، هزینه خطا در نمونههای کلاس اقلیت بهمراتب بیشتر از عواقبی است که در نتیجه طبقهبندی نادرست نمونههای کلاس اکثریت متحمل میشویم. به همین خاطر و از آنجا که وجود داده های نامتوازن در پیشبینی درست دادههای کمتعداد اختلال ایجاد میکند، تاثیر خطاها قابل ملاحظه خواهد بود.
- گمراهکننده بودن معیارهای ارزیابی: در برخی مسائل مانند زمانی که عملکرد مدل تحت تاثیر کلاس اکثریت قرار میگیرد، استفاده از معیارهای قدیمی مانند ماتریس درهم ریختگی ممکن است نتایج گمراهکنندهای را نتیجه دهد. از همین جهت و برای ارزیابی دقیقتر، بهرهگیری از معیارهای دیگری مانند «دقت» (Precision)، «بازیابی» (Recall)، F1-score و «سطح زیر نمودار منحنی مشخصه عملکرد» (Area Under the ROC Curve | AUC) پیشنهاد میشود.
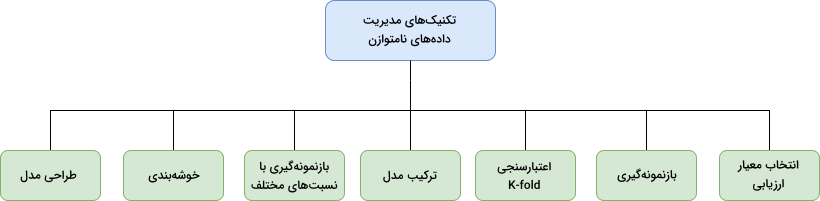
پس از آشنایی با مفهوم داده های نامتوازن و چالشهای آن، در ادامه این مطلب از مجله فرادرس به معرفی شماری از کاربردیترین تکنیکهای مدیریت داده های نامتوازن میپردازیم.
تکنیک های مدیریت داده های نامتوازن
در مواردی انگشتشمار و نادر مانند تشخیص تقلب یا بیماری، شناسایی درست کلاسهای اقلیت نه تنها لازم، که ضروری است. بنابراین مدل نباید آنقدر سوگیری داشته باشد که تنها کلاس اکثریت را به عنوان خروجی پیشبینی کند و نیاز است تا به کلاسهای کمجمعیتتر نیز وزن و اهمیت یکسانی اختصاص دهد. در این بخش، چند نمونه از تکنیکهای مناسب را برای مدیریت داده های نامتوازن معرفی و بررسی میکنیم. البته باید توجه داشت که هر تکنیک کارکرد خاص خود را داشته و نمیتوان یکی را برتر از دیگری دانست.
۱. انتخاب معیار ارزیابی متناسب
تفاوتی ندارد مسئله چیست و چه راهکاری را برای حل آن برگزیدهایم. انتخاب معیار ارزیابی مناسب همیشه در جمله اولین قدمهایی است باید برای مدیریت دادهها نامتوازن برداریم. دقت یک دستهبند از نسبت تعداد پیشبینیهای درست به کل پیشبینیها بهدست میآید. معیاری که تنها وقتی خبری از داده های نامتوازن نباشد ایدهآل است. دو معیار سنجش دیگر به نامهای «دقت» و «بازیابی» به ترتیب دقت پیشبینی یک مدل از کلاسی خاص و توانایی مدل در شناسایی یک کلاس را مورد ارزیابی قرار میدهند. با این حال اگر دیتاست ما نامتوازن باشد، استفاده از معیار F1-score بهترین انتخاب است. در واقع امتیاز F1 «میانگین همساز» (Harmonic Mean) دو معیار دقت و بازیابی بوده و مانند زیر محاسبه میشود:
در نتیجه اگر پیشبینی دستهبند برابر با کلاس اقلیت باشد اما بهخاطر اشتباه بودن، تعداد نمونههای «مثبت نادرست» (False Positive | FP) افزایش یابد، معیار دقت و F1-score کاهش مییابند. بهطور مشابه اگر دادههای کلاس اقلیب به عنوان اکثریت پیشبینی شوند، تعداد نمونههای «منفی نادرست» (False Negative | FN) افزایش یافته و از دو معیار بازیابی و F1-score کاسته میشود. امتیاز F1 تنها در صورتی افزایشی میشود که تعداد و کیفیت پیشبینیهای درست همزمان باهم رشد کنند. در نتیجه، میان معیارهای دقت و بازیابی تعادل برقرار شده و شناسایی هرچه بیشتر نمونهها از کلاس درست اهمیت پیدا میکند. در مطلب زیر از مجله فرادرس، بهطور مفصلتر درباره معیارهای ارزیابی در یادگیری ماشین توضیح دادهایم:
۲. بازنمونه گیری از مجموعه آموزشی
در کنار انتخاب شاخصهای ارزیابی متفاوت، میتوان تغییر را از دیتاست شروع کرد. برای متوازنسازی یک دیتاست نامتوازن از دو رویکرد «بیش نمونهگیری» (Oversampling) و «کم نمونهگیری» (Undersampling) استفاده میشود که در ادامه بیشتر در مورد هر کدام توضیح میدهیم.

۱. کم نمونه گیری
این روش برای به تعادل رساندن دیتاست، از تعداد نمونههای کلاس اکثریت کم میکند. زمانی از رویکرد کم نمونهگیری استفاده میشود که با مشکل کمبود داده مواجه نباشیم. در کم نمونهگیری، همه نمونههای کلاس اقلیت حفظ شده و با انتخاب تصادفی از میان دادههای پرتعداد، دیتاستی جدید و متوازن ایجاد میشود.
۲. بیش نمونه گیری
در مقابل، عمده کاربرد بیش نمونهگیری برای دیتاستهای کوچک است. به این صورت که عمل متوازنسازی با افزایش حجم دادههای نادر اجرا میشود. بهجای حذف نمونههای پرتعداد، از روشهایی مانند Bootstrapping یا «بیش نمونهگیری اقلیت مصنوعی» (Synthetic Minority Oversampling | SMOTE) برای اضافه کردن به تعداد نمونههای کلاس اقلیت استفاده میشود.
هیچکدام از این دو روش نمونهگیری نسبت به دیگری برتری ندارد و کاربرد هر کدام بسته به نوع مسئله و دیتاست متفاوت است. گاهی ترکیب کم نمونهگیری و بیش نمونهگیری نیز موثر خواهد بود.
۳. اعتبارسنجی متقابل K-fold
باید اشاره داشت که اغلب همزمان با بیش نمونهگیری از تکنیک «اعتبارسنجی متقابل» (Cross Validation) نیز برای حل مشکل داده های نامتوازن بهره میبرند. به خاطر داشته باشید که در بیش نمونهگیری، دادههای جدید و تصادفی بر اساس نمونههای کلاس اقلیت تولید میشوند. در نتیجه انجام اعتبارسنجی متقابل بعد از بیش نمونهگیری، نتیجهای جز بیشبرازش شدن مدل نسبت به دادههای جدید نخواهد داشت. به همین خاطر است که اعتبارسنجی متقابل باید قبل از بیش نمونهگیری و همراه با مراحلی همچون انتخاب ویژگی انجام شود. تنها با تکرار فرایند بازنمونهگیری است که میتوان از تصادفی بودن دیتاست مطمئن شد و از مشکل بیشبرازش جلوگیری کرد. اگر قصد دارید بیشتر با مباحثی همچون انتخاب ویژگی آشنا شوید، مشاهده فیلم آموزش مبانی انتخاب ویژگی فرادرس را که لینک آن در زیر قرار دارد به شما توصیه میکنیم:

۴. ترکیب مدل های مختلف
سادهترین راه برای تعمیم دادن مدلهای یادگیری ماشین، استفاده از نمونههای بیشتر است. اما مشکل اینجاست که هنگام تعمیم مدلهای آمادهای مانند رگرسیون لجستیک یا جنگل تصادفی، کلاس اقلیت حذف میشود. راهکار جایگزین، ساختن مدل یادگیری است که برای آموزش از همه نمونههای کلاس اقلیت همراه با نمونه مختلف از دادههای پرتعداد استفاده میکنند. به عنوان مثال فرض کنید ۱۰ مدل مختلف را همراه با ۱۰۰۰ نمونه از کلاس اقلیت و ۱۰ هزار نمونه از کلاس اکثریت در اختیار دارید. اینگونه میتوان ۱۰ هزار نمونه را به ۱۰ قسمت تقسیم کرد و با هر کدام یکی از ۱۰ مدل را آموزش داد.
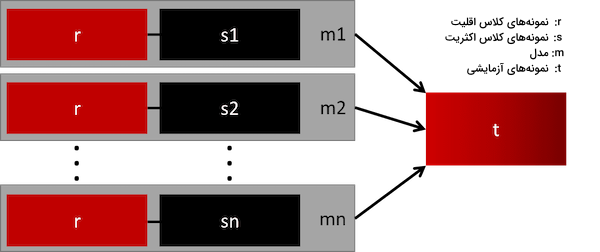
روشی ساده و کارآمد برای دیتاستهای بزرگ که از طریق آن میتوان مدل را با زیرمجموعههای متفاوتی آموزش داد و از قابلیت تعمیمپذیری آن اطمینان حاصل کرد.
۵. بازنمونه گیری با نسبت های متفاوت
تکنیک قبلی را میتوان با تغییر نسبت دادههای دو کلاس اقلیت و اکثریت بهبود بخشید. بهترین نسبت برای هر نوع دیتاست و مدلی تفاوت دارد. اما اگر همان ۱۰ مدل تکنیک قبلی را در نظر بگیریم، شاید بهتر باشد هر مدل با نسبت متفاوتی از دادهها آموزش ببیند. به عنوان مثال ممکن است برای یک مدل نسبت ۱:۱ (اقلیت:اکثریت)، ۱:۳ یا حتی ۲:۱ مناسبتر باشد. بسته به نوع مدل، نسبتهای تعیین شده میتوانند بر اهمیت یا وزن هر کلاس نیز تاثیر بگذارند.

۶. خوشه بندی کلاس اکثریت
این روش پیشنهاد میکند که بهجای نمونهگیری از دادهها برای نمایش تنوع مجموعه آموزشی، نمونههای کلاس اکثریت به گروه یا خوشه تقسیم شوند. سپس مدل، تنها با مراکز هر خوشه و همچنین دادههای کلاس اقلیت آموزش میبیند. برای آشنایی بیشتر در مورد تکنیک خوشهبندی، میتوانید فیلم آموزش خوشهبندی سلسله مراتبی فرادرس را از طریق لینک زیر مشاهده کنید:
۷. طراحی مدل
تا اینجا تمرکز تکنیکهای عنوان شده بر دیتاست بوده و مدلها به عنوان اجزایی ثابت در نظر گرفته شدهاند. اما در حقیقت اگر مدلی متناسب با داده های نامتوازن طراحی شود، دیگر نیازی به اجرای روشهایی مانند بازنمونهگیری نیست. همچنین در صورت متقارن بودن کلاسها، بهکارگیری الگوریتم مشهور XGBoost نقطه شروع خوبی برای متوازنسازی دادهها است. اما این الگوریتم نیز از روش بازنمونهگیری استفاده میکند. پیش از فرایند آموزش، اگر تابع هزینه بهگونهای طراحی شود که جریمه بیشتری برای پیشبینی نادرست نمونههای کمتعداد در نظر بگیرد، قابلیت تعمیمپذیری مدل در مقابل نمونههای جدید افزایش مییابد. برای مثال میتوان الگوریتم SVM را به نحوی تغییر داد که هر پیشبینی نادرست، به نسبتی برابر با تعداد کمِ نمونهها جریمه شود.

سوالات متداول
حالا و پس از آشنایی با مفهوم داده های نامتوازن و انواع تکنیکهای مدیریت این قبیل از دادهها، زمان خوبی است تا در این بخش به چند مورد از سوالات متداول درباره داده های نامتوازن پاسخ دهیم.

روش های مدیریت داده های نامتوازن چیست؟
بهطور کلی، روشهای مدیریت داده های نامتوازن به سه دسته زیر تقسیم میشوند:
- بازنمونهگیری: بیش نمونهگیری کلاس اقلیت، کم نمونهگیری کلاس اکثریت یا تولید نمونههای مصنوعی.
- استفاده از معیارهای ارزیابی مختلف: معیارهایی مانند دقت، بازیابی، F1-score و AUC.
- بهکارگیری الگوریتمهای مرتبط: الگوریتمهایی متناسب با دیتاستهای نامتوازن همچون SMOTE یا روشهای تجمعی و ترکیبی.
چه الگوریتم هایی بیشترین کاربرد را در مدیریت داده های نامتوازن دارند؟
الگوریتمهای بسیاری توانایی مدیریت داده های نامتوازن را دارند. مانند الگوریتم جنگل تصادفی که از روشهایی همچون «کیسهگذاری» (Bagging) و انتخاب ویژگی برای مدیریت داده های نامتوازن استفاده میکند. یا الگوریتم SVM که با تعیین وزن هر کلاس قابل تغییر است و میزان جریمه پیشبینیهای نادرست را مشخص میکند. همچنین تکنیک SMOTE با تولید نمونههای مصنوعی، جمعیت کلاس اقلیت را افزایش داده و باعث عملکرد بهتر مدل میشود.
دیتاست نامتوازن چه مشکلاتی ایجاد می کند؟
دیتاستهای نامتوازن مشکلات زیادی بهوجود میآورند. شاید مدل سوگیری داشته باشد و نتواند نمونههای جدید را بهدرستی طبقهبندی کند. همچنین در صورت استفاده از معیارهای قدیمی مانند ماتریس درهم ریختگی، نتایج حاصل از ارزیابیها قابل اتکا نخواهند بود.
جمعبندی
بحث مدیریت داده های نامتوازن با چالشهای بسیاری همراه بوده و بهطور کلی وجود چنین دادههایی فرایند تصمیمگیری را تحت تاثیر قرار میدهد. بهویژه در زمینههایی حساس مانند پزشکی که دقت پیشبینی نهایی بسیار حائز اهمیت است. همانطور که در این مطلب از مجله فرادرس خواندیم، تکنیکهای متنوعی برای غلبهبر این چالشها وجود دارند که هر کدام از ویژگیها و مزایای منحصربهفردی برخوردار بوده و برای مسائل مختلفی بهکار گرفته میشوند. با درک پیچیدگیها و اجرای استراتژیهای مناسب برای مدیریت داده های نامتوازن، علاقهمندان به یادگیری ماشین میتوانند عملکرد مدلها را بهبود بخشیده و نتایج قابل اعتمادتری ارائه دهند.
source