در یادگیری ماشین، موفقیت مدلها به کیفیت دادههایی که با آن آموزش دیدهاند بستگی دارد. در حالی که به الگوریتمها و مدلهای پیچیده بیشتر توجه میشود، اغلب این «پیشپردازش داده» (Data Preprocessing) است که مهمترین نقش را در رسیدن به نتیجه مطلوب دارد. قدم مهمی که باعث تبدیل دادههای خام به ویژگیهایی موثر و قابل استفاده در یادگیری ماشین میشود. الگوریتمهای یادگیری ماشین اغلب با این فرض اشتباه که تمامی ویژگیها میزان مشارکت برابری در پیشبینی نهایی دارند آموزش میبینند. با اجرای فرایند «نرمالسازی داده» (Data Normalization) که بخشی از پیشپردازش داده است، یکپارچگی میان ویژگیها تضمین میشود. به این صورت، دیگر تنها به این خاطر که برخی ویژگیها مقدار بیشتری دارند، نسبت به سایر ویژگیها و متغیرها ارزش و اهمیت بالاتری پیدا نمیکنند. در این مطلب از مجله فرادرس، یاد میگیریم نرمال سازی داده چیست و با انواع تکنیکهای آن آشنا میشویم.
در این مطلب، ابتدا به پرسش نرمال سازی داده چیست پاسخ میدهیم و از ضرورت اجرای این فرایند میگوییم. سپس به معرفی چند مورد از رایجترین تکنیکهای نرمالسازی داده میپردازیم و در انتهای این مطلب، علاوه بر آشنایی با چالشهای نرمالسازی، یاد میگیریم که چگونه میتوان از طریق زبان برنامهنویسی پایتون دادهها را به فرم نرمال تبدیل کرد.
مفهوم نرمال سازی داده چیست؟
در حقیقت «نرمالسازی داده» (Data Normalization) نوع خاصی از «مقیاسبندی ویژگی» (Feature Scaling) است که دامنه ویژگیها را به مقیاسی استاندارد تبدیل میکند. تنها زمانی به نرمالسازی و هر نوع روش مقایسبندی داده دیگری نیاز است که دیتاست یا «مجموعهداده» (Dataset) شامل ویژگیهایی با دامنه متغیر باشد. همچنین فرایند نرمالسازی دربرگیرنده تکنیکهای متنوعی برای توزیعهای مختلف داده است.

دلیل نرمال سازی داده چیست؟
نرمالسازی دادهها باعث ارتقا دقت و عملکرد مدلهای یادگیری ماشین میشود. فرایند نرمالسازی داده با جلوگیری از غلبه ویژگیهایی با مقادیر بالا بر فرایند یادگیری، در الگوریتمهای مبتنیبر معیار فاصله مانند «K-نزدیکترین همسایه» (KNN) یا «ماشین بردار پشتیبان» (SVM) موثر واقع میشود.
اجرای نرمالسازی دادهها، باعث افزایش پایداری و همگرایی سریعتر در طول آموزشهای «گرادیان-محور» (Gradient-based) میشود. همچنین نرمالسازی تا حد قابل قبولی از رخداد مشکلاتی مانند «محوشدگی گرادیان» (Vanishing Gradient) یا «انفجار گرادیان» (Exploding Gradient) جلوگیری کرده و مدلهای یادگیری را در پیدا کردن راهحلهای بهینه توانمند میسازد. در میان همه فرایندهای مرتبط با پیشپردازش داده، تفسیر و درک نرمالسازی راحتتر است. علاوه بر آن، اگر مقیاس همه ویژگیهای یک مجموعهداده یکسان باشد، شناسایی، مقایسه و مصورسازی ارتباط میان ویژگیهای مختلف سادهتر خواهد بود.

فرض کنید میخواهیم قیمت خانهها را بر اساس ویژگیهای مختلفی همچون مساحت، تعداد اتاق خواب و فاصله تا فروشگاه مواد غذایی پیشبینی کنیم. مجموعهداده ما متشکل از ویژگیهای گوناگونی با مقیاس متفاوت مانند زیر است:
- مساحت: از ۴۶ تا ۴۶۰ متر مربع.
- تعداد اتاق خواب: از ۱ تا ۵ اتاق.
- فاصله تا فروشگاه مواد غذایی: از ۱ تا ۱۶ کیلومتر.
اگر چنین دادههایی را بدون پیشپردازش به مدل یادگیری ماشین ارائه دهید، ممکن است الگوریتم یادگیری وزن بیشتری به ویژگیهایی با مقیاس بزرگتر مانند مساحت اختصاص دهد. در طی فرایند آموزش، الگوریتم اینطور فرض میکند که کوچکترین تغییر در ویژگی مساحت، تاثیر چشمگیری بر قیمت خانه میگذارد. در نتیجه این امکان وجود دارد که ظرافت و اهمیت ویژگیهایی با مقایس کمتر مانند تعداد اتاق خواب و فاصله تا فروشگاه مواد غذایی نادیده گرفته شود. امری که ممکن است به عملکردی نامطلوب و پیشبینیهای جهتدار ختم شود.
با نرمالسازی ویژگیها، مطمئن میشویم که نسبت مشارکت هر ویژگی در فرایند یادگیری حفظ و رعایت شود. در نتیجه، مدل یادگیری ماشین میتواند الگوهای پراکنده در همه ویژگیها را یاد گرفته و توصیف دقیقتری از روابط نهفته میان دادهها ارائه دهد.
چگونه نرمال سازی داده را با فرادرس یاد بگیریم؟

نرمالسازی داده یکی از گامهای حیاتی در آمادهسازی دادها برای یادگیری ماشین است. این فرایند به دنبال تغییر مقیاس و شکل دادهها به گونهایست که برای الگوریتمهای یادگیری ماشین قابل درک و کارآمد باشند. قدم اول در یادگیری نرمالسازی داده، آشنایی با انواع روشهای نرمالسازی مانند Min-Max و Z-score است. پس از آنشایی با تکنیکهای کاربردی که در این مطلب به بررسی چند مورد از آنها میپردازیم، باید مهارت شناسایی نیاز به نرمالسازی و انتخاب روش مناسب برای هر دیتاست را کسب کنید.
در مرحله بعد باید نرمالسازی داده را در پروژههای عملی یادگیری ماشین بهکار ببرید. استفاده از کتابخانههای زبان برنامهنویسی پایتون مانند Scikit-learn، انجام پیشپردازش، آمادهسازی دادهها و بررسی تاثیر آن بر مدلهای آموزشی، تجربه ارزشمندی در این زمینه خواهد بود. اگر شما نیز به تازگی در این مسیر قدم گذاشته و قصد شروع فعالیت حرفهای در حوزه یادگیری ماشین را دارید، میتوانید از فیلمهای آموزشی فرادرس، به ترتیبی که در ادامه آورده شده است بهره ببرید:
تکنیک های نرمال سازی داده چیست؟
حالا که یاد گرفتیم نرمال سازی داده چیست، در این بخش به توضیح دو مورد از اصلیترین تکنیکهای نرمالسازی یعنی «مقیاسبندی کمینه-بیشینه» (Min-Max Scaling) و «استانداردسازی» (Standardization) یا «نرمالسازی امتیاز استاندارد» (Z-score Normalization) میپردازیم. علاوه بر این دو روش، نگاهی نیز به تکنیکهای مقیاسبندی «اعشاری» (Decimal Scaling)، «لگاریتمی» (Log Scaling) و «منسجم» (Robust Scaling) خواهیم داشت که هر کدام برای پاسخ دادن به چالشهای مختلفی طراحی شدهاند. برای یادگیری بیشتر در مورد تکنیکهای پیشپردازش مانند نرمالسازی، میتوانید فیلم آموزشی رایگان مقدمهای بر داده کاوی فرادرس که لینک آن در ادامه آورده شده است را مشاهده کنید:

مقیاس بندی کمینه-بیشینه
بهطور پیشفرض، «مقیاسبندی کمینه-بیشینه» (Min-Max Scaling) را همان نرمالسازی مینامند. در این تکنیک، مقدار ویژگیها در بازهای که بهطور معمول از ۰ تا ۱ متغیر است قرار میگیرد. فرمول مقیاسبندی کمینه-بیشینه به شرح زیر است:
$$ X_{normalized} = frac{X – X_{min}}{X_{max} – X_{min}} $$
در عبارت فوق نماد $$ X $$ مقدار یک ویژگی تصادفی است که میخواهیم آن را نرمال کنیم. همچنین نماد $$ X_{min} $$ و $$ X_{max} $$ بهترتیب برابر با کمترین و بیشترین مقدار ویژگی مورد نظر است. نحوه کارکرد فرمول مقیاسبندی کمینه-بیشینه در شرایط زیر خلاصه میشود:
- وقتی مقدار $$ X $$ کمینه باشد، صورت کسر برابر میشود با $$ X_{min} – X_{min} $$ و در نتیجه مقدار نرمال شده مساوی ۰ خواهد بود.
- وقتی مقدار $$ X $$ بیشینه باشد، صورت کسر برابر میشود با مخرج یا همان $$ X_{max} – X_{min} $$ و خروجی مساوی ۱ خواهد بود.
- وقتی مقدار $$ X $$ نه کمینه و نه بیشینه باشد، مقدار نرمال شده عددی بین ۰ و ۱ خواهد بود. به همین خاطر است که این روش را مقیاسبندی کمینه-بیشینه مینامند.
پیشنهاد میشود زمانی از مقیاسبندی کمینه-بیشینه استفاده کنید که یکی از شرایط زیر صادق باشد:
- حد کران بالا و پایین مشخص بوده و دیتاست فاقد یا شامل تعداد کمی «نمونه پرت» (Outlier) باشد.
- وقتی توزیع دادهها مشخص نیست یا میدانیم توزیعی بهجز «گاوسی» (Gaussian) یا بهطور تقریبی «یکنواخت» (Uniform Distribution) است.
- وقتی حفظ توزیع اصلی دیتاست ضرورت دارد.
استانداردسازی یا نرمال سازی Z-score
در روش «استانداردسازی» (Standardization) یا نرمالسازی Z-score، توزیع دادهها گاوسی فرض شده و از همین جهت، ویژگیها بهگونهای تغییر میکنند که «میانگین» (Mean) برابر با ۰ و «انحراف معیار» (Standard Deviation) برابر با ۱ باشد. در فرمول زیر نماد $$ mu $$ و $$ sigma $$ به ترتیب بیانگر میانگین و انحراف معیار است:
$$ X_{standardized} = frac{X – mu}{sigma} $$
بهکارگیری این تکنیک بهویژه زمانی مفید است که الگوریتم یادگیری مانند مدلهای خطی، توزیع دادهها را نرمال در نظر بگیرد. برخلاف مقیاسبندی کمینه-بیشینه، در استاندارسازی، مقدار ویژگیها محدود به دامنه خاصی نیست. در جدول زیر و پیش از بررسی سایر تکنیکهای نرمالسازی، مقایسهای میان دو رویکرد کمینه-بیشینه و استانداردسازی انجام دادهایم:
| کمینه-بیشینه | استانداردسازی |
| هدف در تغییر دامنه ویژگی در بازهای مشخص و بهطور معمول بین ۰ و ۱ خلاصه میشود. | هدف، تغییر مقادیر یک ویژگی بهگونهایست که میانگین برابر با ۰ و انحراف معیار برابر با ۱ باشد. |
| حساس به نمونههای پرت و مقادیر خارج از دامنه. | حساسیت کمتر نسبت به نمونههای پرت با توجه به استفاده از میانگین و انحراف معیار. |
| کارآمد به هنگام حفظ دامنه اولیه. | کارآمد به هنگام فرض توزیع نرمال برای دادهها. |
| فاقد پیشفرض در مورد توزیع دادهها. | در نظر گرفتن توزیع نرمال برای دادهها. |
| مناسب الگوریتمهایی مانند KNN و شکبههای عصبی. | مناسب الگوریتمهایی مانند «رگرسیون خطی» (Linear Regression) و SVM. |
| حفظ تفسیرپذیری مقادیر اولیه در دامنهای مشخص. | تغییر مقادیر اولیه و دشوار شدن تفسیرپذیری. |
| همگرایی سریعتر در الگوریتمهای مبتنیبر «گرادیان کاهشی» (Gradient Descent). | همگرایی سریعتر در الگوریتمهای حساس به مقیاس ویژگیهای ورودی. |
| قابل استفاده در پردازش تصویر، شبکههای عصبی و الگوریتمهای حساس به مقیاس. | قابل استفاده در رگرسیون خطی، SVM و الگوریتمهایی با پیشفرض توزیع نرمال. |
مقیاس بندی اعشاری
هدف از «مقیاسبندی اعشاری» (Decimal Scaling)، تغییر مقادیر ویژگی به نحوی است که توانی از ۱۰ بوده و بزرگترین قدر مطلق هر ویژگی کوچکتر از ۱ باشد. عمده کاربرد این نرمالسازی زمانی است که دامنه مقادیر دیتاست مشخص اما هر ویژگی نیز دامنه متفاوتی داشته باشد. فرمول مقیاسبندی اعشاری به شرح زیر است:
$$ X_{decimal} = frac{X}{10^d} $$
در عبارت فوق نماد $$ X $$ همان مقدار ویژگی اولیه و $$ d $$ کوچکترین مقدار صحیح بهگونهایست که بزرگترین قدر مطلق، کوچکتر از ۱ باشد. به عنوان مثال، اگر بزرگترین قدر مطلقِ یک ویژگی برابر با ۳۵۰۰ باشد، آنگاه مقدار $$ d $$ مساوی ۳ خواهد بود و مقیاس ویژگی به ۱۰۳ تغییر پیدا میکند. بیشترین مزیت این روش نرمالسازی برای دیتاستهایی است که در آنها قدر مطلق مقادیر مهمتر از مقیاس ویژگی است.
مقیاس بندی لگاریتمی
در روش «مقیاسبندی لگاریتمی» (Log Scaling) از طریق محاسبه لگاریتم هر نمونه داده، مقدار ویژگیها به مقیاسی لگاریتمی تغییر مییابد. فرمول این نرمالسازی به شرح زیر است:
$$ X_{log} = log(X) $$
اهمیت مقیاسبندی لگاریتمی زمانی مشخص میشود که رشد یا افول دادهها الگویی نمایی داشته باشد. در این روش با فشردهسازی مقیاس دیتاست، کار مدلهای یادگیری برای تشخیص الگوها و روابط میان دادهها آسانتر میشود. افزایش یا کاهش جمعیت به نسبت سال، مثالی مناسب از دیتاستی است که ویژگیهایی با رشد نمایی دارد.
مقیاس بندی منسجم
روش «مقیاسبندی منسجم» (Robust Scaling) زمانی بیشترین کاربرد را دارد که دیتاست شامل نمونههای پرت باشد. در این نرمالسازی بهجای میانگین و انحراف معیار از دو معیار «میانه» (Median) و «دامنه میان چارکی» (Interquartile Range | IQR) برای مدیریت دادههای پرت استفاده میشود. فرمول مقیاسبندی منسجم عبارت است از:
$$ X_{robust} = frac{X – Median}{IQR} $$
این روش از نرمالسازی با توجه به مقاوم بودن نسبت به تاثیر نمونههای پرت، گزینه مناسبی برای دیتاستهایی با مقادیر نامتعارف است.
چالش های نرمال سازی داده چیست؟
تا اینجا میدانیم منظور از نرمال سازی داده چیست و چرا در یادگیری ماشین اهمیت دارد. اگرچه نرمالسازی داده فرایندی موثر و ارزشمند بوده اما با چالشهایی نیز مواجه است. از مدیریت نمونههای پرت گرفته تا انتخاب مناسبترین روش برای دیتاست خود، رسیدگی به این قبیل از مشکلات برای دستیابی به حداکثر توانایی مدل یادگیری ماشین ضرورت دارد. در ادامه این بخش از مطلب مجله فرادرس، چند مورد از رایجترین چالشهای نرمالسازی دادهها را شرح داده و برای هر کدام راهحل ارائه میدهم.

مدیریت نمونه های پرت
در حقیقت، نمونههای پرت یا Outliers به برخی از نقاط داده موجود در دیتاست گفته میشود که تفاوت قابل توجهی با سایر نمونهها داشته و روند نرمالسازی را با اختلال مواجه میکنند. در صورتی که به مشکل نمونههای پرت رسیدگی نشود، تغییرات اعمال شده موثر نخواهد بود. همانطور که در بخش قبلی نیز به آن اشاره شد، تکنیک مقیاسبندی منسجم میتواند راهحل خوبی برای رفع مشکل نمونههای پرت باشد. همچنین به عنوان نوعی استراتژی دیگر، میتوان به حذف یا جایگذاری مقادیر کمتر یا بیشتر از یک حد آستانه، با مقداری ثابت اشاره کرد.
انتخاب تکنیک نرمال سازی
در حالی که برخی از مهمترین تکنیکهای نرمالسازی را بررسی کردیم، همچنان روشهای بسیاری برای انتخاب وجود دارند. گزینش تکنیک مناسب نیازمند داشتن درک کاملی از دیتاست است. هنگام پیشپردازش دادهها، باید چندین تکنیک نرمالسازی مختلف را آزموده و تاثیر هر کدام را بر عملکرد نهایی مدل ارزیابی کنیم. در انتها نیاز است درک عمیقی از ویژگیهای دیتاست داشته باشید و روشی همراستا با توزیع و الگوی دادهها انتخاب کنید.
نرمال سازی داده های پراکنده
از جمله مواقعی که امکان دارد نرمالسازی به چالش تبدیل شود، هنگامی است که با دادههای «پراکنده» (Sparse) سروکار داشته باشیم. مانند دیتاستی که مقدار اکثر ویژگیهای آن برابر با صفر است. برای نرمالسازی دادههای پراکنده از نوع خاصی از مقیاسبندی کمینه-بیشینه با عنوان «کمینه-بیشینه پراکنده» (Sparse Min-Max) استفاده میشود. توجه داشته باشید که بهتر است پیش از نرمالسازی، ابتدا به «جایگذاری» (Imputation) و مدیریت «مقادیر گمشده» (Missing Values) بپردازید. جایگذاری مقادیر گمشده از جمله قدمهای اولیه و لازم هنگام بررسی و پاکسازی دیتاست به حساب میآید.
نرمال سازی و خطر بیش برازش
در یادگیری ماشین زمانی مشکل «بیشبرازش» (Overfitting) رخ میدهد که مدل نه تنها الگوهای پایه و اساسی بلکه نویز و معایب دادههای آموزشی را نیز یاد بگیرد. در حالی که مدلهای بیشبرازش شده نسبت به دادههای آموزشی عملکرد بسیار خوبی از خود به نمایش میگذارند، هنگام روبهرو شدن با دادههای جدید ضعیف عمل میکنند. شاید نرمالسازی به تنهایی عامل بیشبرازش نباشد اما در ترکیب با معیارهایی همچون پیچیدگی مدل یا «منظمسازی» (Regularization) ناکارآمد، میتواند مشکلساز باشد. اگر در محاسبه پارامترهای نرمالسازی از تمام دادههای دیتاست استفاده شود، ممکن است اطلاعات سایر مجموعهها مانند مجموعه «آزمایشی» (Test Set) و «اعتبارسنجی» (Validation Set) نیز یاد گرفته شده و در نهایت، ارزیابی دقیقی از عملکرد مدل حاصل نشود.

از همین جهت و بهمنظور کاهش خطر بیشبرازش، بهتر است ابتدا نرمالسازی را بر مجموعه آموزشی اعمال و سپس از پارامترهای بهدست آمده برای نرمالسازی دو مجموعه آزمایشی و اعتبارسنجی استفاده کنیم. به این ترتیب، مدل یاد میگیرد چگونه بدون آنکه تحت تاثیر اطلاعات موجود در مجموعه آزمایشی و اعتبارسنجی قرار بگیرد، آموختههای حاصل از مجموعه آموزشی را به نمونه دادههای جدید تعمیم دهد. برای آشنایی بیشتر با مفهوم بیشبرازش، مطالعه مطلب زیر را از مجله فرادرس پیشنهاد میکنیم:
گاهی مدل یادگیری ماشین بیش از حد پیچیده است و برای جریمه یا همان کاستن از مقدار پارامترهای تاثیرگذار، باید به پیادهسازی تکنیکهای منظمسازی بپردازیم. منظمسازی از برازش نویز و نمونههای نامطلوب در مجموعه آموزشی جلوگیری میکند. در آخر برای ارزیابی عملکرد مدل نسبت به دادههای جدید باید از تکنیکهای اعتبارسنجی مناسب مانند «اعتبارسنجی متقابل» (Cross Validation) کمک بگیرید. اگر بیشبرازش در طول فرایند اعتبارسنجی شناسایی شود، میتوان با اعمال تغییراتی مانند کاهش پیچیدگی مدل یا افزایش منظمسازی از آن جلوگیری کرد.
پیاده سازی فرایند نرمال سازی داده در پایتون
حالا که میدانیم منظور از نرمال سازی داده چیست و با چه چالشهایی همراه است، در این بخش به شرح نحوه پیادهسازی این فرایند با زبان برنامهنویسی پایتون و بهطور خاص کتابخانه Scikit-learn میپردازیم. کتابخانه Scikit-learn مجموعهای از ابزارهای جامع را برای انجام فرایندهایی همچون پیشپردازش داده، «انتخاب ویژگی» (Feature Selection)، «کاهش ابعاد» (Dimensionality Reduction)، ساخت و آموزش مدلها، ارزیابی مدل، «میزانسازی ابَرپارامترها» (Hyperparameter Tuning) و «دنبالهسازی مدل» (Model Serialization) در اختیار کاربر قرار میدهد.
در این بخش و برای نرمالسازی از دیتاست معروف Iris که انواع مختلف گیاه زنبق را طبقهبندی کرده است استفاده میکنیم. دیتاست Iris دارای چهار ویژگی «طول کاسبرگ» (Sepal Length)، «عرض کاسبرگ» (Sepal Width)، «طول گلبرگ» (Petal Length) و «عرض گلبرگ» (Petal Width) برای سه گونه متفاوت از گیاه زنبق است. توجه داشته باشید که واحد این چهار ویژگی به سانتیمتر بوده و دیتاست ۱۵۰ سطر دارد. یعنی هر گونه از گیاه زنبق شامل ۵۰ نمونه است. بهطور معمول از این دیتاست در مسائل «طبقهبندی» (Classification) و پیشبینی گونه درست از میان سه کلاس مختلف استفاده میشود. با این حال هدف ما از بهکارگیری دیتاست Iris، به نمایش گذاشتن نسخه تغییر یافته دادهها پس از اعمال دو روش نرمالسازی کمینه-بیشینه و استانداردسازی است.
ابتدا کتابخانههای مورد نیاز را فراخوانی و سپس دیتاست Iris را مانند زیر در متغیری به نام iris
بارگذاری میکنیم:
1import numpy as np
2import pandas as pd
3# To import the dataset
4from sklearn.datasets import load_iris
5# To be used for splitting the dataset into training and test sets
6from sklearn.model_selection import train_test_split
7# To be used for min-max normalization
8from sklearn.preprocessing import MinMaxScaler
9# To be used for Z-normalization (standardization)
10from sklearn.preprocessing import StandardScaler
11
12# Load the iris dataset from Scikit-learn package
13iris = load_iris()برای مشاهده خلاصه آماری دادهها، ویژگی DESCR
را بر روی متغیر iris
صدا میزنیم:
1# This prints a summary of the characteristics, statistics of the dataset
2print(iris.DESCR)همانطور که در تصویر زیر یا همان خروجی اجرای قطعه کد فوق مشخص است، دامنه ویژگی Sepal Length از ۴/۳ تا ۷/۹، ویژگی Sepal Width از ۲ تا ۴/۴ و دامنه دو ویژگی Petal Length و Petal Width نیز به ترتیب از ۱ تا ۶/۹ و ۰/۱ تا ۲/۵ سانتیمتر متغیر است:
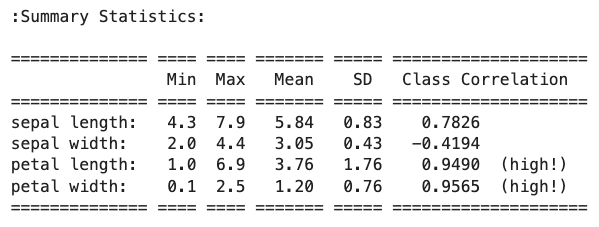
پیشنهاد میشود قبل از نرمالسازی، دیتاست را به دو مجموعه آموزشی و آزمایشی تقسیم کنیم. برای این کار از تابع train_test_split
موجود در کتابخانه Scikit-learn کمک میگیریم. از آنجا که هدف ما تنها پیشپردازش است، نیازی به تعریف مجموعه اعتبارسنجی نداریم و نسبت تقسیم دیتاست را ۸۰ به ۲۰ در نظر میگیریم. به این صورت، مجموعه آموزشی ۱۲۰ و مجموعه آزمایشی ۳۰ سطر خواهد داشت:
1# To divide the dataset into training and test sets
2X_train, X_test, y_train, y_test = train_test_split(X, Y ,test_size=0.2)از جمله مراحل رایج پس از بارگذاری و تقسیم دادهها، اجرای فرایندهای پاکسازی داده، جایگذاری مقادیر گمشده و مدیریت نمونههای پرت است. اما در این مطلب تمرکز ما بر روی نرمالسازی دادهها است و در نتیجه از اجرای این مراحل خودداری میکنیم. در مرحله بعد و با استفاده از تکنیک نرمالسازی کمینه-بیشینه یا Min-Max، دامنه مقادیر داده را به بازه ۰ تا ۱ تغییر میدهیم. برای پیادهسازی نرمالسازی Min-Max از کلاس MinMaxScaler
کتابخانه Scikit-learn کمک میگیریم:
1# Good practice to keep original dataframes untouched for reusability
2X_train_n = X_train.copy()
3X_test_n = X_test.copy()
4
5# Fit min-max scaler on training data
6norm = MinMaxScaler().fit(X_train_n)
7
8# Transform the training data
9X_train_norm = norm.transform(X_train_n)
10
11# Use the same scaler to transform the testing set
12X_test_norm = norm.transform(X_test_n)در قدم بعد میتوانیم دادههای نرمال شده را از طریق تابع print
در خروجی نمایش دهیم. اما بهتر است ابتدا مجموعه آموزشی را به فرمت «دیتافریم» (Dataframe) از کتابخانه Pandas تبدیل کنیم و سپس با فراخوانی متد describe
، توصیف آماری دقیقی از دادهها بهدست آوریم:
1X_train_norm_df = pd.DataFrame(X_train_norm)
2
3# Assigning original feature names for ease of read
4X_train_norm_df.columns = iris.feature_names
5
6X_train_norm_df.describe()خروجی مانند تصویر زیر است:

با توجه به نتایج بهدست آمده از تکنیک Min-Max، دامنه تمام ویژگیها به ۰ تا ۱ سانتیمتر تغییر یافته است. حالا بهطور مشابه و مانند قطعه کد زیر، تکنیک استانداردسازی یا همان نرمالسازی Z-score را پیادهسازی میکنیم:
1X_train_s = X_train.copy()
2X_test_s = X_test.copy()
3
4# Fit the standardization scaler onto the training data
5stan = StandardScaler().fit(X_train_s)
6
7# Transform the training data
8X_train_stan = stan.transform(X_train_s)
9
10# Use the same scaler to transform the testing set
11X_test_stan = stan.transform(X_test_s)
12
13# Convert the transformed data into pandas dataframe
14X_train_stan_df = pd.DataFrame(X_train_stan)
15
16# Assigning original feature names for ease of read
17X_train_stan_df.columns = iris.feature_names
18
19# Check out the statistical description
20X_train_stan_df.describe()در تصویر زیر شاهد نتایج آماری بهدست آمده از تکنیک استانداردسازی هستید:

هدف از نرمالسازی Z-score، تبدیل مقادیر یک ویژگی به نحوی است که میانگین برابر با ۰ و انحراف معیار برابر با ۱ باشد. همانطور که از توصیف بهدست آمده نیز مشخص است، مقدار میانگین یا mean برای هر چهار ویژگی چیزی نزدیک به ۰ است و انحراف معیار که با عبارت std در جدول دیده میشود، مقدار مساوی ۱ دارد. حالا میتوانیم از دادههای تبدیل شده برای آموزش دادن الگوریتمهای یادگیری ماشین استفاده کنیم.
مسیر یادگیری داده کاوی و یادگیری ماشین

اگر تا اینجا همراه مطلب بوده باشید، بهخوبی میدانید که نرمالسازی و بهطور کلی پیشپردازش داده تنها قسمتی کوچک از حوزه بزرگتری به نام داده کاوی است. امروزه داده کاوی و یادگیری ماشین از مهمترین مباحث علوم داده به شمار میروند. این دو حوزه در کنار یکدگیر، توانایی کشف الگوها و استخراج دانش را از حجم عظیم دادههای موجود در سازمانها و صنایع مختلف فراهم میکنند. با این حال، مسیر یادگیری داده کاوی و یادگیری ماشین سرشار از چالشها و تجربیات لذتبخش است و شما میتوانید از مجموعه فیلمهای آموزشی فرادرس که لینک آن در ادامه آورده شده است به عنوان راهنمایی جامع در طی این مسیر بهرهمند شوید:
جمعبندی
در عصر دیجیتال امروز که داده نقش محرک اصلی نوآوری و تصمیمگیری را بازی میکند، آشنایی و بهدست آوردن درک مناسب از پیچیدگیهای علم داده بسیار اهمیت دارد. از اصول اولیه فرایندهایی مانند نرمالسازی گرفته تا گستره وسیعتری از تکینکهای پاکسازی، بهطور پیوسته باید یکپارچگی و کیفیت دادهها حفظ شود. در این مطلب از مجله فرادرس یاد گرفتیم نرمال سازی داده ها چیست و با تعدادی از کاربردیترین تکنیکهای نرمالسازی مانند Z-score و مقیاسبندی Min-Max نیز آشنا شدیم. در نهایت، هر نوع از نرمالسازی مزایا و معیاب منحصربهفردی داشته و انتخاب روش مناسب، وابسته به مسئله و دیتاستی است که در اختیار دارید.
source