«یادگیری ماشین» (Machine Learning) به عنوان یکی از شاخه های هوش مصنوعی محسوب میشود که بسیاری از سازمانها و شرکتها از آن به منظور بهرهگیری از اطلاعات مهم دادهها استفاده میکنند. این حوزه از هوش مصنوعی بر روی روشها و الگوریتمهای مختلفی تمرکز دارد که کامپیوتر با استفاده از آنها میتواند یاد بگیرد چطور مسئلهای خاص را حل کند. رویکردهای مختلفی برای یادگیری کامپیوتر وجود دارد که یکی از مهمترین و پرکاربردترین آنها، رویکرد «یادگیری نظارت نشده» (Unsupervised Learning) است. در این مطلب از مجله فرادرس، قصد داریم به این پرسش پاسخ دهیم که یادگیری نظارت نشده چیست و چه روشهایی را شامل میشود.
در ابتدای مطلب حاضر، پس از توضیح مختصری پیرامون مفهوم یادگیری ماشین، به تعریف جامعی از مفهوم یادگیری نظارت نشده میپردازیم و توضیح میدهیم الگوریتمهای مبتنی بر این رویکرد چطور مسائل را یاد میگیرند. سپس، به انواع روشهای این رویکرد از یادگیری ماشین اشاره میکنیم و کاربردها و ویژگیهای آنها را شرح میدهیم. در انتهای مطلب، به معرفی پرکاربردترین الگوریتمهای یادگیری نظارت نشده خواهیم پرداخت و از مثالهای برنامه نویسی برای پیادهسازی هر یک از آنها استفاده خواهیم کرد.
مقدمه ای بر یادگیری ماشین
پیش از پرداختن به این پرسش که یادگیری نظارت نشده چیست ، مروری بر مفهوم یادگیری ماشین خواهیم داشت. یادگیری ماشین یا ماشین لرنینگ به عنوان یکی از شاخههای اصلی هوش مصنوعی تلقی میشود که به کامپیوتر این امکان را میدهد بدون نیاز به برنامهریزی صریح توسط برنامه نویس، از دادهها و تجربیات خود یاد بگیرد و عملکرد یادگیری و حل مسئله خود را به مرور بهبود بخشد.
این حوزه از هوش مصنوعی شامل روشها و الگوریتمهای مختلفی میشود که با استفاده از دادهها آموزش میبینند و سپس میتوانند برای مسائلی نظیر پیشبینی مقادیر، طبقهبندی دادهها یا شناسایی الگوها استفاده شوند. مهندس یادگیری ماشین باید دادهها یا منابع مورد نیاز الگوریتم های یادگیری ماشین را فراهم کند و در قالبی مناسب آنها را در اختیار الگوریتمها قرار دهد تا مدلها بتوانند از این دادههای آموزشی در راستای یادگیری مسائل استفاده کنند. الگوریتمهای یادگیری ماشین را میتوان بر اساس کاربرد و نوع داده آموزشی مورد نیازشان، به سه نوع اصلی تقسیمبندی کرد:
- الگوریتمهای ماشین لرنینگ با رویکرد «یادگیری نظارت شده» (Supervised Learning)
- الگوریتمهای ماشین لرنینگ با رویکرد «یادگیری نظارت نشده» (Unsupervised Learning)
- الگوریتمهای ماشین لرنینگ با رویکرد «یادگیری تقویتی» (Reinforcement Learning)
در این مطلب، قصد داریم به طور مفصل به این پرسش پاسخ دهیم که یادگیری نظارت شده چیست و الگوریتم های هوش مصنوعی مبتنی بر این رویکرد چه ویژگیهایی دارند. در انتهای این مطلب نیز به نحوه پیادهسازی برخی از پرکاربردترین الگوریتمهای این رویکرد خواهیم پرداخت و مثالهای کاربردی برای درک این روشها ارائه خواهیم کرد.
یادگیری نظارت نشده چیست؟
در پاسخ به پرسش یادگیری نظارت نشده چیست ، میتوان گفت این روش از یادگیری به عنوان یکی از رویکردهای یادگیری ماشین محسوب میشود که هدف آن کشف کردن ساختار پنهان در یک مجموعه داده بدون برچسب و سازماندهی دادههای خام در قالب ویژگیهای جدید یا «خوشه بندی» (Clustering) دادههای مشابه است. برخلاف رویکرد یادگیری نظارت شده، الگوریتمهای یادگیری نظارت نشده نیازی به نگاشت دادههای ورودی به مقادیر خروجی (یا برچسبهای داده) ندارند.

به عبارت دیگر، هیچ ناظر یا معلمی برای آموزش به الگوریتمهای یادگیری نظارت نشده وجود ندارد و الگوریتمهای این رویکرد صرفاً بر اساس شباهتها و تفاوتهای موجود در دادهها، به خوشهبندی آنها میپردازند. از آن جایی که هیچ برچسبی برای دادها تعریف نمیشود، از رویکرد یادگیری نظارت نشده نمیتوان برای مسائلی نظیر طبقه بندی دادهها و رگرسیون و پیشبینی مقادیر استفاده کرد زیرا در این گونه مسائل به برچسب (یا همان مقدار Y) نیاز داریم تا مقادیر ورودی (دادهها) به برچسب (مقدار Y) نگاشته شوند. در عوض، در این رویکرد از یادگیری هدف این است که اطلاعات جالب و پنهانی را از دادهها کشف کنیم. در ادامه، به نحوه یادگیری این نوع از الگوریتمهای یادگیری ماشین میپردازیم.
الگوریتم یادگیری های نظارت نشده چطور کار می کنند؟
در ادامه پاسخ به پرسش یادگیری نظارت نشده چیست ، بهتر است به این موضوع نیز بپردازیم که روشهای این رویکرد از یادگیری ماشین چطور کار میکنند. همانطور که در بخش قبلی به آن اشاره کردیم، یادگیری نظارت نشده با تجزیه و تحلیل دادههای بدون برچسب و یافتن ساختارهای پنهان در آنها کار خوشهبندی را انجام میدهد.
به منظور درک بهتر شیوه عملکرد روشهای یادگیری نظارت نشده میتوان از یک مثال ملموس کمک گرفت. فرض کنید قصد داریم مجموعهای از تصاویر مربوط به انواع مختلفی از اتومبیلها را گروهبندی کنیم. برای این کار دانشمند داده تصاویر را در اختیار الگوریتم های یادگیری ماشین قرار میدهد تا دادهها را تجزیه و تحلیل کنند و بر اساس ویژگیهای مشابه تصاویر بتوانند تصاویر مرتبط با یکدیگر را در خوشههای مجزا قرار دهند. برای این که مدلهای یادگیری نظارت نشده به دقت بالایی برسند، باید حجم زیادی از دادههای آموزشی را برای آنها فراهم کنیم.
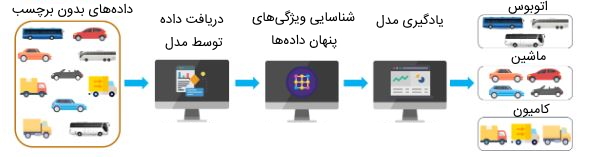
یادگیری نظارت نشده همان روشی است که ما برای شناسایی و طبقهبندی موارد مختلف در دنیای واقعی استفاده میکنیم. فرض کنید تا به حال طعم کچاپ یا سس تند را نخوردهاید. اگر به شما دو بطری کچاپ و سس تند داده شود که برچسبی بر روی آنها نباشد و از شما خواسته شود آنها را بچشید، میتوانید طعم تفاوت آنها را تشخیص دهید. همچنین میتوانید ویژگیهای هر دو سس (طعم ترش و طعم تند هر یک از آنها) را شناسایی کنید حتی اگر نام هیچ کدام از سسها را ندانید.
اگر چندین بار دیگر طعم آنها را بچشید، با مزههای آن بیشتر آشنا میشوید و میتوانید غذاهایی را که با این سسها طعمدار شدهاند، به سادگی تشخیص دهید و غذاهای طعمدار شده با هر یک از سسها را گروهبندی کنید. به عبارتی، شما نیازی به دانستن نام سسها یا نام غذاها برای گروهبندی آنها ندارید و حتی ممکن است به هر یک از سسها نامهای دلبخواه مانند «سس شیرین» و «سس تند» اختصاص دهید. این روال از یادگیری انسان مشابه روش یادگیری نظارت نشده است که در آن انسان و ماشین به دنبال شناسایی الگوها و ویژگیهای مختلف دادهها به منظور گروهبندی آنها هستند.
مراحل استفاده الگوریتم های یادگیری نظارت نشده چیست؟
مراحل یادگیری الگوریتمهای یادگیری نظارت نشده را میتوان در چندین مرحله خلاصه کرد که در ادامه به این مراحل میپردازیم:
- بیان مسئله اولین مرحله در حل مسائل هوش مصنوعی و یادگیری ماشین است که در این گام به توضیح مسئله، اهداف، دادهها و منابع مورد نیاز و تعیین بازه زمانی لازم برای توسعه پروژه پرداخته میشود.
- در این گام باید دادههای آموزشی مورد نیاز مسئله جمعآوری شوند و روشهای پیش پردازش داده نظیر نرمالسازی، «پاکسازی داده» (Data Cleaning) و پر کردن مقادیر از دست رفته بر روی دادهها اعمال میگردند.
- پس از تمیز کردن داده، باید آنها را در قالبی مناسب دربیاوریم که الگوریتمهای یادگیری نظارت نشده بتوانند آنها را به عنوان ورودی دریافت کنند. مواردی نظیر «انتخاب ویژگی» (Feature Selection)، تغییر دادهها به فضای دیگر و کاهش ابعاد دادهها در این مرحله انجام میشوند.
- الگوریتم یادگیری نظارت نشده مورد نظر خود را با استفاده از دادههای فراهم شده آموزش دهید.
- عملکرد مدل هوش مصنوعی را میتوانید با معیارهای ارزیابی در یادگیری ماشین بسنجید.
انواع مسائل یادگیری نظارت نشده
در پاسخ به پرسش یادگیری نظارت نشده چیست ، اشاره کردیم که این نوع یادگیری روشی است که برای خوشهبندی دادههایی استفاده میشود که دارای برچسب نیستند. اما در کل میتوان مسائلی را که به دادههای آموزشی بدون برچسب نیاز دارند، به سه دسته کلی تقسیمبندی کرد:
- مسائل «خوشهبندی» (Clustering)
- مسائل «قوانین وابستگی» (Association Rules)
- مسائل «کاهش بعد» (Dimensionality Reduction)
در ادامه، به توضیح هر یک از انواع مسائل یادگیری نظارت نشده میپردازیم.
هدف از خوشه بندی در مسائل یادگیری نظارت نشده چیست؟
خوشهبندی روشی برای داده کاوی با رویکرد یادگیری نظارت نشده است. در این نوع مسائل به دنبال گروهبندی دادههای بدون برچسب بر اساس شباهتها و تفاوتهای آنها هستیم.
بهعبارتی، خوشهبندی فرآیندی برای یافتن ساختارهای مشابه در مجموعه دادههای بدون برچسب است تا درک دادهها قابل فهمتر شود. با استفاده از این روش، زیرگروههایی (خوشههایی) از مجموعه دادهها ایجاد میشوند به نحوی که هر خوشه شامل دادههایی است که بیشترین شباهت را به یکدیگر دارند و از دادههای سایر خوشهها متفاوت هستند. روشهای مختلفی برای خوشهبندی دادهها وجود دارند که در فهرست زیر عنواین آنها را ملاحظه میکنید:
- «خوشهبندی سلسله مراتبی» (Hierarchical Clustering) یا «خوشهبندی اتصالی» (Connectivity Based Clustering)
- «خوشهبندی مبتنی بر مرکز» (Centroids Based Clustering)
- «خوشهبندی مبتنی بر توزیع احتمالاتی» (Distribution Based Clustering)
- «خوشهبندی مبتنی بر تراکم» (Density Based Clustering)
- «خوشهبندی فازی» (Fuzzy Clustering)
- «خوشهبندی نظارت شده مبتنی بر محدودیت» (Constraint Based Supervised Clustering)
در ادامه، به توضیحی پیرامون هر یک از انواع روشهای خوشهبندی میپردازیم.
خوشه بندی سلسله مراتبی در یادگیری نظارت نشده چیست؟
خوشهبندی سلسلهمراتبی که با عنوان خوشهبندی مبتنی بر اتصال نیز شناخته میشود، بر این اصل استوار است که هر داده بسته به میزان فاصله نزدیکی (میزان ارتباط) به سایر دادهها متصل میشود. خوشهها به شکل «درختنما» (Dendrograms) نمایش داده میشوند و محور X دادههایی را نشان میدهد که با هم شباهتی ندارند و نمیتوان آنها را در یک خوشه قرار داد و محور Y جایی است که در آن خوشهها ادغام میشوند.
با دو روش میتوان ساختار سلسلهمراتبی خوشهها را تشکیل داد:
- «رویکرد انشقاقی» (Divisive Approach): این نوع خوشهبندی سلسلهمراتبی از بالا به پایین با در نظر گرفتن تمام دادهها به عنوان یک خوشه واحد شروع میشود. سپس، به طور مکرر خوشهها به خوشههای کوچکتر تقسیم میشوند و این روال تا زمانی ادامه خواهد داشت تا الگورریتم به یک شرط توقف مشخص برسد. این شرط توقف میتواند تعداد خوشههای مورد نظر، معیار کیفیت خوشهها یا محدودیتهای محاسباتی باشد.
- «رویکرد تجمیعی» (Agglomerative Approach): این روش از خوشهبندی، برعکس روش انشقاقی است و ساختار سلسلهمراتبی دادهها از پایین به بالا شکل میگیرد. به بیان جزئیتر، خوشهبندی با شروع از هر نقطه داده به عنوان یک خوشه منفرد شروع میشود. سپس، به طور مکرر خوشهها با یکدیگر ادغام میشوند تا خوشههایی با تعداد مشخص (k خوشه) شکل بگیرد. در این رویکرد، از معیارهای مختلفی نظیر تعداد خوشهها، فاصله خوشهها و واریانس خوشهها برای تعیین ترکیب خوشهها استفاده میشوند.
{kind=link}
خوشه بندی مبتنی بر مرکز در یادگیری ماشین چیست؟
خوشهبندی مبتنی بر مرکز سادهترین نوع خوشهبندی در دادهکاوی است. در این روش، براساس نزدیکی نقاط داده به یک نقطه مرکزی خوشههای مختلفی تشکیل میشوند. تعداد خوشههای نهایی را باید از قبل برای الگوریتم مشخص کنید که تعیین تعداد آنها چالشبرانگیز است. از این روش خوشهبندی در بسیاری از مسائل یادگیری ماشین به منظور تجزیه و تحلیل و بهینهسازی مجموعه دادههای بزرگ استفاده میشود.
خوشه بندی توزیعی در یادگیری ماشین چیست؟
خوشهبندی مبتنی بر توزیع روشی است که از آن برای گروهبندی دادهها براساس توزیع احتمالاتی مشترکشان مانند توزیع گاوسی، توزیع دوجملهای و سایر توزیعهای احتمالاتی استفاده میشود. به بیان دیگر، الگوریتمهای خوشهبندی توزیعی، دادهها را براساس ویژگیهای آماری تحلیل میکنند و نقاطی را که احتمالاً دارای یک توزیع مشترک هستند، در یک خوشه قرار میدهند. این نقاط ممکن است بر اساس ویژگیهایی مانند میانگین، انحراف معیار و شکل توزیع به هم نزدیک باشند.
خوشه بندی مبتنی بر تراکم در یادگیری نظارت نشده چیست؟
خوشهبندی مبتنی بر تراکم از دیگر روشهای خوشهبندی در یادگیری نظارت نشده است که بر اساس این روش، نقاط داده براساس تراکم آنها در فضای داده در خوشههای مجزا قرار میگیرند. به عبارتی، در این روش، نقاط دادهای که در نزدیکی یک فضای فشرده قرار دارند، در یک خوشه قرار میگیرند. در سایر روشهای خوشهبندی دو فرض اصلی در نظر گرفته میشوند:
- دادهها عاری از هرگونه نویز هستند.
- شکل خوشههای تشکیل شده کاملاً هندسی (دایرهای یا بیضی) هستند.

اما واقعیت این است که دادهها همیشه تا حدی دارای دادههای نویزی و «دادههای پرت» (Outliers) هستند که نمیتوان آنها را نادیده گرفت. علاوه بر آن، شکل خوشهها را نباید صرفاً دایرهای یا بیضی فرض کرد و خوشهها با اشکال دلخواه میتوانند تمامی دادهها را در خود جای دهند. روش خوشهبندی مبتنی بر تراکم با این محدودیتها مقابله میکند و میتواند با نویز، اشکال دلخواه و دادههای چندبعدی سروکار داشته باشد.
روش خوشه بندی فازی در یادگیری ماشین
خوشهبندی فازی یک روش گروهبندی نقاط داده است که در آن هر نقطه از داده میتواند به چندین خوشه با احتمالات مختلف عضویت تعلق داشته باشد. این روش با سایر تکنیکهای خوشهبندی سنتی متفاوت است که در آنها هر نقطه داده به طور انحصاری به یک خوشه مجزا اختصاص دارند. فرض کنید گروهی از دوستان خود را میخواهید بر اساس علاقهمندیهایشان به چندین گروه تقسیم کنید. بدین منظور، میتوانید از روشهای خوشهبندی سنتی و خوشهبندی فازی به صورت زیر استفاده کنید:
- با استفاده از روش خوشهبندی سنتی هر یک از دوستان خود را بر اساس علاقه زیادش به یک فعالیت خاص، در یک گروه مجزا قرار میدهید. به عنوان مثال، علی و رضا بر اساس علاقهمندیشان به ورزش و موسیقی، در دو گروه ورزشی و هنری قرار میگیرند. با این حال، ممکن است علی به موسیقی هم علاقه داشته باشد اما علاقهمندی اصلی او ورزش است و به همین دلیل در گروه ورزشی قرار میگیرد.
- در روش خوشهبندی فازی افراد را میتوان با درجات یا احتمالات مختلف در گروههای مجزا قرار داد. به عنوان مثال، علی ممکن است ۷۰ درصد در گروه ورزشی و ۳۰ درصد در گروه هنری قرار گیرد. رضا نیز میتواند بر اساس میزان علاقهمندی زیادش به موسیقی، ۸۰ درصد در گروه هنر و ۲۰ درصد در گروه ورزشی جای گیرد.
در روش خوشهبندی فازی هر نقطه داده برای هر خوشه یک امتیاز عضویت (معمولاً یک عدد بین ۰ و ۱) دریافت میکند. امتیاز ۱ به معنای عضویت کامل داده در خوشه است و امتیاز ۰ این موضوع را نشان میدهد که داده به خوشه مورد نظر تعلق ندارد. مقادیر بین اعداد صفر و یک نیز نشاندهنده عضویت جزئی داده به خوشهها هستند. میتوان گفت خوشهبندی فازی برای مسائل دنیای واقعی مناسب است زیرا با قطعیت نمیتوان دادهها را بر اساس ویژگیهایشان در گروههای مجزا گروهبندی کرد.
خوشه بندی نظارت شده مبتنی بر محدودیت در یادگیری نظارت نشده
فرآیند خوشهبندی معمولاً بر این اساس است که دادهها را بتوان به تعداد بهینهای از گروههای ناشناخته تقسیم کرد. مراحل اساسی همه الگوریتمهای خوشهبندی، یافتن الگوهای پنهان و شباهتهای دادهها بدون دخالت انسان و شرایط از پیش تعریف شده است. با این حال، در برخی سناریوهای تجاری، ممکن است ملزم به گروهبندی دادهها بر اساس محدودیتهای خاصی باشیم. اینجا جایی است که روش خوشهبندی نظارت شده بر اساس محدودیتهای خاص وارد عمل میشود.
محدودیتها بر اساس انتظارات و نیازهای کاربران تعیین میشوند و در هنگام شکلگیری خوشهها، الگوریتم باید این محدودیتها را در نظر بگیرد و مطابق با آنها به گروهبندی دادهها بپردازد. محدودیتها میتوانند مواردی نظیر تعداد ثابت خوشهها، اندازه خوشه، یا ابعاد دادههایی (متغیرهایی) باشند که برای فرآیند خوشهبندی ضروری هستند.
به منظور درک بهتر این روش خوشهبندی میتوانیم از یک مثال ساده کمک بگیریم. فرض کنید چندین اسباببازی دارید که باید آنها را مرتب کنید اما به جای این که آنها را فقط بر اساس نوع اسباببازی (ماشینها، عروسکها، بلوکها) در جعبهها قرار دهید، چند قانون اضافی را هم باید در هنگام مرتب کردن اسباببازیها در نظر بگیرید. به عنوان مثال، «دو کامیون را با هم در یک جعبه قرار دهید» یا «خرس عروسکی را در جعبه بلوکها نگذارید». این مثال، روش کار خوشهبندی نظارت شده مبتنی بر محدودیت است.
به عبارتی، این روش خوشهبندی، همانند روش خوشهبندی معمولی است که بر اساس آن دادههای مشابه در یک گروه قرار میگیرند اما یک ناظر یا انسان یک سری قوانین اضافی یا محدودیتها را برای نحوه خوشهبندی دادهها تعریف میکند. با لحاظ کردن قوانین و محدودیتهای اضافی، الگوریتم میتواند تصمیمات بهتر و دقیقتری درباره خوشهبندی دادهها بگیرد به خصوص زمانی که با دادههای پیچیده سر و کار دارد.
قوانین همبستگی در یادگیری نظارت نشده
استخراج قوانین همبستگی، یکی از روشهای رویکرد یادگیری نظارت نشده در ماشین لرنینگ است که با رویکردی مبتنی بر قاعده، به دنبال کشف روابط جالب بین ویژگیهای موجود در یک مجموعه داده و قوانین همبستگی بین دادهها میگردد.
رایجترین مثال کاربرد استخراج قوانین همبستگی، تحلیل سبد خرید مشتریان است. این روش دادهکاوی، به خردهفروشان کمک میکند تا با بررسی روابط بین محصولات مختلف، الگوهای خرید مشتریان را بهتر درک کنند. مجموعه قوانین همبستگی الگویی نظیر «اگر X، آنگاه Y» هستند. به عنوان مثال، اگر لیست خرید مشتریان را بررسی کنیم، میتوانیم چنین قوانینی را استخراج کنیم:
- اگر کره خریداری شود، آنگاه مربا هم خریداری میشود.
- اگر پاستا خریداری شود، آنگاه سس کچاپ نیز خریداری میشود.

رایجترین الگوریتم برای استخراج قوانین همبستگی، الگوریتم «اپریوری» (Apriori) است. با این حال، الگوریتمهای دیگری مانند الگوریتمهای Eclat و FP-growth نیز برای این نوع یادگیری نظارت نشده وجود دارند.
هدف از کاهش ابعاد در یادگیری نظارت نشده چیست ؟
کاهش بعد، یکی دیگر از روشهای یادگیری نظارت نشده است که از آن برای کاهش تعداد ویژگیهای یک مجموعه داده به نحوی استفاده میشود که اطلاعات مهم دادهها حفظ شوند. به عبارت دیگر، این روش فرآیندی برای تبدیل دادههای با ابعاد بالا به یک فضای با ابعاد پایینتر است که همچنان ماهیت اصلی دادههای اصلی را حفظ میکند.
در یادگیری ماشین، دادههای با ابعاد بالا به دادههایی گفته میشوند که تعداد زیادی ویژگی دارند. عملکرد مدلهای یادگیری ماشین با افزایش تعداد ویژگیها کاهش مییابد زیرا پیچیدگی مدل با تعداد ویژگیها افزایش مییابد و یافتن یک راه حل خوب برای مدل دشوارتر میشود. علاوهبراین، دادههای با ابعاد بالا نیز میتوانند منجر به رخداد بیش برازش شوند و مدل نمیتواند به خوبی برای دادههای جدید تعمیم یابد. کاهش بعد میتواند به کاهش پیچیدگی مدل و بهبود عملکرد تعمیم آن کمک کند. دو رویکرد اصلی برای کاهش بعد وجود دارد:
- «انتخاب ویژگی» (Feature Selection): انتخاب ویژگی شامل انتخاب زیرمجموعهای از ویژگیهای اصلی است که بیشترین ارتباط را با مسئله مورد نظر دارند. هدف از این روش، کاهش ابعاد مجموعه داده با حفظ مهمترین ویژگیها است. روشهای مختلفی برای انتخاب ویژگی وجود دارد که عبارتاند از:
- «روشهای فیلتر» (Filter Methods): در این روش، ویژگیها بر اساس ارتباط آنها با متغیر هدف رتبهبندی میشوند.
- «روشهای پوششی» (Wrapper Methods): در این روش عملکرد مدل به عنوان معیار انتخاب ویژگیها استفاده میشود.
- «روشهای تعبیه شده» (Embedded Methods): در این روش، انتخاب ویژگی با فرآیند آموزش مدل ترکیب میشود.
- «استخراج ویژگی» (Feature Extraction): استخراج ویژگی شامل ایجاد ویژگیهای جدید با ترکیب یا تغییر ویژگیهای اصلی است. هدف این روش ساخت ویژگیهای جدیدی است که ماهیت اصلی دادههای اصلی را در یک فضای با ابعاد پایینتر ثبت کند. روشهای مختلفی برای استخراج ویژگی وجود دارد که مهمترین آنها عبارتاند از:
- «تحلیل مولفه اصلی» (Principle Component Analysis | PCA)
- «تحلیل تبعیض خطی» (Linear Discriminant Analysis | LDA)
- جاسازی همسایگی احتمالی t-توزیع (t-SNE)
کاربرد روش های یادگیری نظارت نشده
در راستای پاسخ به این پرسش که یادگیری نظارت نشده چیست ، میتوان به کاربردهای این روش از ماشین لرنینگ نیز اشاره کرد. از آنجایی که روش خوشهبندی یک تکنیک قدرتمند در یادگیری ماشین محسوب میشود، از آن میتوان برای آمادهسازی دادهها برای فرآیندهای مختلف استفاده کرد. در ادامه، به برخی از کاربردهای جذاب خوشهبندی اشاره میکنیم:
- تقسیمبندی بازار: کسبوکارها برای درک بهتر مخاطبان هدف خود، نیاز به بخشبندی بازار به گروههای کوچکتر دارند. با استفاده از روشهای خوشهبندی، افراد همفکر بر اساس ویژگیهایی مانند محل سکونت گروهبندی میشوند تا توصیههای مشابهی به آنها ارائه داده شوند و به الگوسازی و کسب بینش کمک کنند.
- بازاریابی: افراد بازاریاب برای درک رفتار خرید مشتریان و تنظیم زنجیره تأمین و توصیهها از روشهای خوشهبندی استفاده میکنند. با کمک الگوریتمهای خوشهبندی، افرادی با ویژگیهای مشابه و احتمال خرید یکسان گروهبندی میشوند تا بتوان به بخشهای مناسب مشتریان دست پیدا کرده و تبلیغات مؤثری ارائه داده شوند.
- تحلیل شبکههای اجتماعی: از روشهای خوشهبندی برای مشاهده تعامل بین افراد فعال در شبکهای اجتماعی و کسب بینش در مورد نقشها و گروههای مختلف استفاده میشود.
- تحلیل شبکههای بیسیم یا طبقهبندی ترافیک شبکه: روشهای خوشهبندی ویژگیهای منابع ترافیک شبکه را دستهبندی میکند و میتوان بر اساس خوشههای حاصل شده، انواع ترافیک را مشخص کرد. داشتن اطلاعات دقیق درباره منابع ترافیک به رشد ترافیک سایت و برنامهریزی مؤثر ظرفیت کمک میکند.
- فشردهسازی تصویر: روشهای خوشهبندی به کاهش اندازه تصویر بدون افت کیفیت و به ذخیره تصاویر در قالب فشرده کمک میکند.
- پردازش داده و وزندهی ویژگی: دادهها میتوانند به عنوان شناسههای خوشه نشان داده شوند. این کار منجر به صرفهجویی در ذخیرهسازی و سادهسازی دادههای ویژگی میشود. دسترسی به دادهها با استفاده از تاریخ، زمان و مشخصات جمعیتی امکانپذیر است.
- تنظیم خدمات ویدیویی: پلتفرمهایی مانند نتفلیکس و سایر سرویسهای پخش زنده با استفاده از روشهای خوشهبندی میتوانند بینندگانی با رفتار و علایق مشابه را بر اساس پارامترهایی مانند ژانر، دقیقه تماشا در روز و تعداد کل فیلمهای مشاهده شده را در گروههایی دستهبندی میکنند. این کار به نشان دادن تبلیغات و ارائه توصیههای مرتبط به کاربران کمک میکند.
- علوم زیستی و مراقبتهای بهداشتی: روشهای خوشهبندی برای ایجاد طبقهبندی گیاهی و جانوری برای سازماندهی ژنهایی با عملکردهای مشابه به کار میرود. همچنین، از این روشهای میتوان در تشخیص سلولهای سرطانی با استفاده از بخشبندی تصویر پزشکی استفاده کرد.
- شناسایی محتوای خوب یا بد: خوشهبندی با استفاده از ویژگیهایی مانند منبع خبری، کلمات کلیدی و محتوا، به فیلتر کردن مؤثر اخبار جعلی و تشخیص کلاهبرداری، اسپم یا محتوای نامناسب کمک میکند.
مزایای یادگیری نظارت نشده
تا به این جای مطلب حاضر از مجله فرادرس، به این پرسش پاسخ دادیم که یادگیری نظارت نشده چیست و چه روشهایی را شامل میشود. همچنین، به کاربردهای گسترده آن اشاره کردیم و به این نکته پرداختیم که روشهای یادگیری نظارت نشده به دلیل مزایای مهمی که دارند، در حل بسیاری از مسائل هوش مصنوعی استفاده میشوند. در ادامه این بخش، به برخی از مزیتهای روشهای یادگیری نظارت نشده اشاره میکنیم:
- بر خلاف مدلهای یادگیری نظارت شده که به دادههای برچسبگذاری شده نیاز دارند، روشهای یادگیری نظارت نشده به دادههای آموزشی بدون برچسب نیاز دارند که این امر در زمان و منابع و هزینه صرفهجویی میکند.
- از الگوریتمهای یادگیری نظارت نشده برای یافتن ساختارها و روابط پنهان در دادههایی استفاده میشود که به راحتی نمیتوان آنها را تجزیه و تحلیل کرد. این رویکرد از یادگیری ماشین میتواند اطلاعات جالب و ارتباطات غیرمنتظرهای از دادهها را آشکار کند که منجر به کشفیات و کاربردهای جدید میشوند.
- کار با دادههایی با ابعاد بالا دشوار است. روشهای یادگیری نظارت نشده میتوانند به کاهش تعداد ویژگیها کمک کنند. الگوریتمهای کاهش ابعاد حجم دادهها را به نحوی کم میکنند که اطلاعات ضروری آنها حفظ شوند و دادهها برای تجزیه و تحلیل و تفسیر آسانتر شوند.
- این الگوریتمها میتوانند به طور موثر دادههای نقطهای مشابه را گروهبندی یا در مجموعه دادههای بزرگ موارد غیرعادی و ناهنجاریها را شناسایی کنند. این قابلیت به تقسیمبندی بازار، پروفایلسازی مشتری، تشخیص تقلب و سایر کاربردها کمک میکند.
- الگوریتمهای یادگیری نظارت نشده میتوانند برای آمادهسازی دادهها برای الگوریتمهای یادگیری نظارت شده استفاده شوند. به عنوان مثال، میتوان از روشهای یادگیری نظارت نشده همانند فیلتر کردن ویژگیهای نامربوط، شناسایی عوامل نهفته یا کاهش بعد برای تغییر شکل دادن دادههای خام بهره گرفت تا عملکرد و کارایی مدلهای نظارت شده را بهبود بخشند.
معایب یادگیری نظارت نشده
روشهای یادگیری نظارت نشده، علیرغم مزیتهای مهمی که دارند، دارای معایبی نیز هستند که در ادامه به مهمترین آنها اشاره میکنیم:
- بر خلاف مدلهای یادگیری نظارت شده که هدف آنها واضح است (به عنوان مثال، پیشبینی یک نتیجه خاص)، تفسیر نتایج الگوریتمهای یادگیری نظارت نشده میتواند چالشبرانگیز باشد. گاهی نحوه خوشهبندی دادهها، ویژگیها و سایر خروجیها نیاز به تجزیه و تحلیل دقیق و دانش تخصصی دارند.
- بدون دادههای برچسبگذاری شده به راحتی نمیتوان صحت و درستی الگوهای پنهان دادهها را ارزیابی کرد. این امر میتواند منجر به تفسیرهای ذهنی و سوگیری در نتایج شود.
- برخی از الگوریتمهای نظارت نشده، به خصوص روشهایی که با مجموعه دادههای بزرگ کار میکنند، میتوانند از نظر محاسباتی پرهزینه باشند و نیاز به منابع قابل توجهی داشته باشند.
- با این که یادگیری نظارت نشده میتواند الگوها و روابط پنهان را آشکار کند، به طور مستقیم پیشبینیهایی در مورد نتایج خاص انجام نمیدهد. ممکن است روشهای این رویکرد برای پیشبینیها به تجزیه و تحلیل بیشتر یا ادغام با روشهای یادگیری نظارت شده نیاز داشته باشند.
الگوریتم های یادگیری نظارت نشده
حال که به این پرسش پاسخ دادیم که یادگیری نظارت شده چیست و روشهای این رویکرد از یادگیری ماشین چه کاربرد و ویژگیهایی دارند، در این بخش، به معرفی برخی از پرکاربردترین الگوریتمهای یادگیری نظارت نشده میپردازیم که در ادامه، فهرست عناوین آنها را ملاحظه میکنید:
- الگوریتم خوشهبندی «K میانگین» (K-means)
- الگوریتم خوشهبندی DBSCAN
- الگوریتم خوشهبندی «مخلوط گاوسی» (Gaussian Mixture)
- الگوریتم خوشه بندی BIRCH
الگوریتم خوشه بندی «انتشار وابستگی» (Affinity Propagation) - الگوریتم خوشه بندی «تغییر میانگین» (Mean-Shift)
- الگوریتم خوشه بندی «سلسله مراتبی تجمعی» (Agglomerative Hierarchical)
- الگوریتم کاهش بعد «تحلیل مولفههای اصلی» (Principle Component Analysis | PCA)
- الگوریتم کاهش بعد «تجزیه مقادیر منفرد» (Singular Value Decomposition | SVD)
- الگوریتم کاهش بعد «آنالیز تشخیصی خطی» (Latent Dirichlet Allocation | LDA)
- الگوریتم کاهش بعد Isomap Embedding
- الگوریتم قوانین همبستگی «اپریوری» (Aperiori)
همچنین، قطعه کدهایی از زبان برنامه نویسی پایتون، به عنوان بهترین زبان برنامه نویسی برای یادگیری ماشین، برای پیادهسازی این الگوریتمها ارائه خواهیم کرد و از کتابخانه های پایتون برای هوش مصنوعی استفاده میکنیم که شامل انواع مختلفی از مدلهای ماشین لرنینگ هستند.
الگوریتم خوشه بندی K-means
الگوریتم خوشهبندی K-Means یکی از مدلهای یادگیری ماشین با رویکرد نظارت نشده است که مجموعه دادههای بدون برچسب را به خوشههای مختلف گروهبندی میکند. در این الگوریتم، K تعداد خوشهها را مشخص میکند. به عبارتی، برنامه نویس باید K را پیش از آموزش مدل، مقداردهی کند. به عنوان مثال، اگر K برابر با دو باشد، الگوریتم خوشهبندی K-Means دادهها را به دو خوشه (گروه) تقسیم میکند.
الگوریتم خوشه بندی K-means یک الگوریتم مبتنی بر مرکز است و کار خود را با تعیین مراکزی برای خوشهها آغاز میکند و با اختصاص دادن سایر نقاط داده به نزدیکترین مرکز گروهبندی دادهها را ادامه میدهد. هدف اصلی این الگوریتم به حداقل رساندن مجموع فواصل بین نقاط داده و خوشههای متناظر آنها است.
در ادامه، قطعه کدی از زبان برنامه نویسی پایتون را ملاحظه میکنید که برای پیادهسازی مسئله خوشهبندی با استفاده از الگوریتم K-Means ارائه شده است. در این قطعه کد، با استفاده از make_classification
از کتابخانه Sklearn هزار داده آموزشی دو بعدی تولید کردیم.
1from numpy import unique
2from numpy import where
3from matplotlib import pyplot
4from sklearn.datasets import make_classification
5from sklearn.cluster import KMeans
6
7# initialize the data set we'll work with
8training_data, _ = make_classification(
9 n_samples=1000,
10 n_features=2,
11 n_informative=2,
12 n_redundant=0,
13 n_clusters_per_class=1,
14 random_state=4
15)
16
17pyplot.scatter(training_data[:, 0], training_data[:, 1])
18pyplot.show()خروجی قطعه کد بالا نمایی از نحوه قرارگیری دادهها در فضای مختصات را نشان میدهد:

سپس، با استفاده از قطعه کد زیر، دادههای آموزشی را با الگوریتم خوشهبندی K-Means خوشهبندی کردیم:
1# define the model
2kmeans_model = KMeans(n_clusters=2)
3
4# assign each data point to a cluster
5dbscan_result = kmeans_model.fit_predict(training_data)
6
7# get all of the unique clusters
8dbscan_clusters = unique(dbscan_result)
9
10#plotting the results:
11
12for dbscan_cluster in dbscan_clusters:
13 pyplot.scatter(training_data[dbscan_result == dbscan_cluster , 0] , training_data[dbscan_result == dbscan_cluster , 1])
14
15pyplot.show()نحوه خوشهبندی دادههای آموزشی توسط الگوریتم K-Means را در تصویر زیر ملاحظه میکنید:

الگوریتم خوشه بندی DBSCAN در یادگیری نظارت نشده چیست ؟
نام الگوریتم DBSCAN مخفف عبارت (Density Based Spatial Clustering of Applications with Noise) به معنای خوشهبندی فضایی مبتنی بر چگالی برای کاربردهایی با دادههای نویزی است. از این الگوریتم میتوان برای یافتن نقاط پرت در یک مجموعه داده استفاده کرد. این الگوریتم خوشههایی با شکل دلخواه را بر اساس چگالی نقاط داده در مناطق مختلف پیدا میکند. به عبارتی، الگوریتم DBSCAN نقاط داده را بر اساس مناطقی با چگالی کم جدا میکند تا بتواند نقاط پرت بین خوشههای با چگالی بالا را تشخیص دهد. عملکرد این الگوریتم در هنگام کار با دادههایی با شکل پراکندگی عجیب و غریب بهتر از مدل خوشهبندی K-means است.
الگوریتم DBSCAN دارای دو پارامتر است که باید در هنگام پیادهسازی آن توسط برنامه نویس مقداردهی شوند. دو پارامتر که نحوه تعریف خوشهها را مشخص میکنند، در فهرست زیر ملاحظه میشوند:
- پارامتر minPts
: حداقل تعداد نقاط دادهای که باید برای یک منطقه با چگالی بالا در کنار هم خوشهبندی شوند.
- پارامتر eps
: میزان فاصله دادهها برای تعیین خوشهبندی آنها
در ادامه، قطعه کدی را به زبان برنامه نویسی پایتون ملاحظه میکنید که با استفاده از الگوریتم DBSCAN دادههای آموزشی خوشهبندی شدهاند:
1from numpy import unique
2from numpy import where
3from matplotlib import pyplot
4from sklearn.datasets import make_classification
5from sklearn.cluster import DBSCAN
6
7
8# initialize the data set we'll work with
9training_data, _ = make_classification(
10 n_samples=1000,
11 n_features=2,
12 n_informative=2,
13 n_redundant=0,
14 n_clusters_per_class=1,
15 random_state=4
16)
17
18# define the model
19dbscan_model = DBSCAN(eps=0.25, min_samples=9)
20
21# train the model and assign each data point to a cluster
22dbscan_result = dbscan_model.fit_predict(training_data)
23
24# get all of the unique clusters
25dbscan_clusters = unique(dbscan_result)
26
27# plot the DBSCAN clusters
28for dbscan_cluster in dbscan_clusters:
29 pyplot.scatter(training_data[dbscan_result == dbscan_cluster , 0] , training_data[dbscan_result == dbscan_cluster , 1], label= 'Cluster ' + str(dbscan_cluster))
30
31# show the DBSCAN plot
32pyplot.show()در تصویر زیر، خروجی قطعه کد بالا را ملاحظه میکنید که نحوه خوشهبندی دادهها را با الگوریتم DBSCAN نشان میدهد:

الگوریتم مخلوط Gaussian برای خوشه بندی
یکی از مشکلات K-Means این است که خوشهبندی دادهها باید از یک فرمت دایرهای پیروی کنند. روشی که K-Means فاصله بین نقاط داده را محاسبه میکند با یک مسیر دایرهای مرتبط است. مدل k-means به صورت فرضی برای هر خوشه یک دایره (یا در ابعاد بالاتر، یک ابر کُره) در مرکز قرار میدهد به طوری که شعاع آن با دورترین نقطه خوشه تعیین میشود. تصویر زیر، مثالی از دادههایی را نشان میدهد که نحوه توزیع آنها به شکل دایره است و الگوریتم K-Means آنها را با یک فضای دایرهای شکل خوشهبندی کرده است:

به عبارتی دیگر، تصور کنید هر خوشه مانند یک حباب با یک مرکز و یک مرز دایرهای شکل باشد. k-means با قرار دادن حبابی روی نقاط داده تلاش میکند تا آنها را به چندین حباب جداگانه با کمترین تداخل بین آنها دستهبندی کند. شعاع هر حباب با دورترین نقطهای مشخص میشود که درون آن قرار میگیرد.
این ویژگی k-means باعث میشود عملکرد خوبی در خوشهبندی دادههای دایرهای شکل یا خوشههایی با مرزهای تقریباً دایرهای داشته باشد. اما برای دادههای با اشکال پیچیدهتر مانند خوشههای خطی یا ستارهای، ممکن است به خوبی عمل نکند و خوشههای نادرستی ایجاد کند. به عنوان مثال در تصویر زیر، دادهها را بهتر است به صورت بیضی شکل خوشهبندی کنیم که الگوریتم k-means برای چنین نوعی از خوشهبندی به کار نمیرود.

مدلهای مخلوط گاوسی چنین مشکلی را برطرف میکنند و از آنها میتوان برای خوشهبندی دادهها با شکلهای دلخواه استفاده کرد. به عبارتی سادهتر، در مدل مخلوط گاوسی، هر خوشه با یک توزیع گاوسی نشان داده میشود. الگوریتم سعی میکند توزیعهای گاوسی مناسب را برای دادهها پیدا کند و هر نقطه داده را به محتملترین توزیع گاوسی (خوشه) اختصاص دهد. این ویژگی باعث میشود که این الگوریتم بتواند شکلهای پیچیدهتر خوشهها را نسبت به K-Means تشخیص دهد.
به علاوه، در الگوریتم k-means، هر نقطه داده به صورت قطعی در یک خوشه قرار میگیرند. اما در واقعیت، ممکن است همپوشانیهایی بین خوشهها وجود داشته باشد. مدلهای مخلوط گاوسی (GMM) این امکان را به ما میدهند که برای هر نقطه داده، احتمالاتی را محاسبه کنیم که میزان احتمال تخصیص دادهها را به هر یک از خوشهها نشان میدهند.
مدل مخلوط گاوسی (GMM) با ترکیب چندین توزیع نرمال کار میکند. به بیان دیگر، این الگوریتم به جای تشخیص خوشهها با نزدیکترین مرکز، مجموعهای از K توزیع نرمال را برای دادهها مشخص میکند. سپس پارامترهای توزیعهای نرمال مانند میانگین و واریانس و همچنین وزن هر خوشه را تخمین میزند. بعد از یادگیری پارامترها برای هر نقطه داده، میتواند احتمال تعلق آن به هر یک از خوشهها را محاسبه کند.

در قطعه کد زیر مثالی از نحوه کاربرد الگوریتم مخلوط گاوسی را برای خوشهبندی دادهها ملاحظه میکنید. بر اساس این الگوریتم، دادهها در ۴ خوشه مجزا دسته بندی میشوند:
1from numpy import unique
2from numpy import where
3from matplotlib import pyplot
4from sklearn.datasets import make_classification
5from sklearn.mixture import GaussianMixture
6
7# initialize the data set we'll work with
8training_data, _ = make_classification(
9 n_samples=1000,
10 n_features=2,
11 n_informative=2,
12 n_redundant=0,
13 n_clusters_per_class=1,
14 random_state=4
15)
16
17gaussian_model = GaussianMixture(n_components=4)
18
19# train the model
20gaussian_model.fit(training_data)
21
22# assign each data point to a cluster
23gaussian_result = gaussian_model.predict(training_data)
24
25# get all of the unique clusters
26gaussian_clusters = unique(gaussian_result)
27
28# plot the Gaussian clusters
29for dbscan_cluster in gaussian_clusters:
30 pyplot.scatter(training_data[gaussian_result == dbscan_cluster , 0] , training_data[gaussian_result == dbscan_cluster , 1] , label= 'Cluster ' + str(dbscan_cluster))
31pyplot.legend()
32
33# show the Gaussian plot
34pyplot.show()در تصویر زیر، خروجی قطعه کد بالا را ملاحظه میکنید که خوشهبندی دادهها با استفاده از الگوریتم مخلوط گاوسی نشان میدهد:

کاربرد الگوریتم خوشه بندی BIRCH در یادگیری ماشین چیست؟
الگوریتمهای یادگیری نظارت نشده مانند K-Means برای خوشهبندی مجموعه دادههای بزرگ با منابع محدود (مانند حافظه یا CPU کندتر) خیلی کارآمد نیستند. دلیل این نقطه ضعف این است که با افزایش میزان حجم دادهها، الگوریتمهای معمولی یادگیری نظارت نشده نمیتوانند با کیفیت بالا و سرعت زیاد خوشهبندی دادهها را انجام دهند. به منظور رفع این مشکل، الگوریتم خوشهبندی BIRCH ارائه شده است.
کلمه BIRCH مخفف عبارت Balanced Iterative Reducing and Clustering using Hierarchies به معنای کاهش و خوشهبندی ترازمند و بازکردی با بهرهگیری از ردهبندی است و به عنوان یکی از روشهای خوشهبندی سلسلهمراتبی محسوب میشود. این الگوریتم میتواند از مجموعه دادههای بزرگ یک خلاصه کوتاه و فشرده به نحوی تهیه کند که تا حد امکان اطلاعات مهم دادهها حفظ شوند و سپس به خوشهبندی دادههای خلاصه شده میپردازد.
الگوریتم یادگیری نظارت نشده BIRCH معمولاً برای تکمیل سایر الگوریتمهای خوشهبندی استفاده میشود، زیرا این الگوریتم خلاصهای از مجموعه دادههای آموزشی ایجاد میکند که سایر الگوریتمهای خوشهبندی میتوانند از آنها استفاده کنند. نکته مهم دیگر درباره مدل BIRCH این است که این مدل صرفاً میتواند دادههای عددی را خوشهبندی کند. بنابراین، اگر دادههای شما غیرعددی هستند، در ابتدا باید آنها را استفاده از یک سری روشها به دادههای عددی تبدیل کنید. همچنین، این الگوریتم دارای ۳ پارامتر مهم است که باید آنها را برای خوشهبندی دادهها مقداردهی کنید. این پارامترها عبارتاند از:
- پارامتر Threshold: الگوریتم BIRCH از یک ساختار درخت به منظور دستهبندی دادهها استفاده میکند. وقتی تعداد نقاط داده در یک گره برگ به حد آستانه یا Threshold برسد، دادههای آن گره در زیرگرههای جدیدی تقسیم میشود تا از بارگذاری بیش از حد دادهها در یک گره جلوگیری شود.
- پارامتر Branching_Factor: این پارامتر حداکثر تعداد زیرخوشههای هر گره درخت در الگوریتم BIRCH را مشخص میکند. این پارامتر بر پهنا و عمق درخت تاثیر میگذارد. اگر مقدار عددی بالایی را به این پارامتر تخصیص دهید، درختی گستردهتر و کم عمقتر ایجاد و با تخصیص مقدار کمتر به این پارامتر، درختی باریکتر و عمیقتر ساخته میشود.
- پارامتر N_Clusters: این پارامتر تعداد خوشههایی را مشخص میکند که پس از تکمیل کل الگوریتم BIRCH باید بازگردانده شوند. اگر این پارامتر روی None تنظیم شود، مرحله خوشهبندی نهایی انجام نمیشود و خوشههای میانی بازگردانده میشوند.
در ادامه، قطعه کدی از زبان برنامه نویسی پایتون را ملاحظه میکنید که نحوه خوشهبندی دادهها را با استفاده از الگوریتم BIRCH نشان میدهد:
1from numpy import unique
2from numpy import where
3from matplotlib import pyplot
4from sklearn.datasets import make_classification
5from sklearn.cluster import Birch
6
7# initialize the data set we'll work with
8training_data, _ = make_classification(
9 n_samples=1000,
10 n_features=2,
11 n_informative=2,
12 n_redundant=0,
13 n_clusters_per_class=1,
14 random_state=4
15)
16
17# define the model
18birch_model = Birch(threshold=0.03, n_clusters=8)
19
20# train the model
21birch_model.fit(training_data)
22
23# assign each data point to a cluster
24birch_result = birch_model.predict(training_data)
25
26# get all of the unique clusters
27birch_clusters = unique(birch_result)
28
29# plot the BIRCH clusters
30for birch_cluster in birch_clusters:
31 pyplot.scatter(training_data[birch_result == birch_cluster , 0] , training_data[birch_result == birch_cluster , 1] , label= 'Cluster ' + str(birch_cluster))
32pyplot.legend()
33
34# show the BIRCH plot
35pyplot.show()در تصویر زیر، خروجی قطعه کد بالا را ملاحظه میکنید. الگوریتم BIRCH دادهها را در ۸ خوشه مجزا تفکیک کرده است:

الگوریتم خوشه بندی انتشار وابستگی
نحوه عملکرد الگوریتم خوشهبندی انتشار وابستگی (Affinity Propagation) در مقایسه با سایر الگوریتمهای خوشهبندی متفاوت است. در این روش، هر نقطه داده با تمام نقاط داده دیگر ارتباط برقرار میکند تا به یکدیگر اطلاع دهند که چقدر شبیه هم هستند و به این طریق خوشههایی برای دادههای مشابه ساخته میشود.
با ارسال پیام بین نقاط داده، مجموعههایی از دادهها به نام «نمونههای برجسته» (exemplars) پیدا میشوند که نشاندهنده خوشهها هستند. یک نمونه برجسته زمانی پیدا میشود که نقاط داده پیامهایی را بین یکدیگر تبادل کنند و بر سر این موضوع به توافق رسیده باشند که کدام داده بهترین نماینده یک خوشه است.
لازم نیست به این الگوریتم خوشهبندی انتشار وابستگی تعداد خوشههای مورد انتظار را در پارامترهای اولیه اعلام کنید. به عبارتی، در مسائلی نظیر «بینایی کامپیوتر» (Computer Vision) که مطمئن نیستید چند خوشه را برای دادهها در ظر بگیرید، میتوانید از این الگوریتم استفاده کنید تا دادهها را بر اساس نمونههای برجسته به طور خودکار در گروههای مختلف قرار دهد. در مثال زیر، قطعه کدی از زبان پایتون را ملاحظه میکنید که به منظور خوشهبندی دادهها با استفاده از الگوریتم خوشهبندی انتشار وابستگی ارائه شده است:
1from numpy import unique
2from numpy import where
3from matplotlib import pyplot
4from sklearn.datasets import make_classification
5from sklearn.cluster import AffinityPropagation
6
7# initialize the data set we'll work with
8training_data, _ = make_classification(
9 n_samples=1000,
10 n_features=2,
11 n_informative=2,
12 n_redundant=0,
13 n_clusters_per_class=1,
14 random_state=4
15)
16
17# define the model
18model = AffinityPropagation(damping=0.7)
19
20# train the model
21model.fit(training_data)
22
23# assign each data point to a cluster
24result = model.predict(training_data)
25
26# get all of the unique clusters
27clusters = unique(result)
28
29# plot the clusters
30for cluster in clusters:
31 pyplot.scatter(training_data[result == cluster , 0] , training_data[result == cluster , 1] , label= 'Cluster ' + str(cluster))
32pyplot.legend(fontsize="5")
33
34# show the plot
35pyplot.show()خروجی قطعه کد بالا را در تصویر زیر ملاحظه میکنید. الگوریتم خوشهبندی انتشار وابستگی، دادهها را بهطور خودکار در ۲۴ گروه دستهبندی کرده است:

الگوریتم خوشه بندی تغییر میانگین Mean-Shift در ماشین لرنینگ
الگوریتم خوشهبندی تغییر میانگین (Mean Shift) یکی از روشهای یادگیری نظارت نشده است که به صورت مداوم نقاط داده را به خوشهها اختصاص میدهد. این کار با سوق دادن نقاط به سمت «مد» (Mode) (بیشترین تراکم نقاط داده در یک ناحیه) انجام میشود. به همین دلیل، به آن «الگوریتم جستجوی مد» (Mode-Seeking Algorithm) نیز گفته میشود. الگوریتم تغییر میانگین در زمینههای پردازش تصویر و بینایی کامپیوتر کاربرد دارد.
با داشتن مجموعهای از نقاط داده، الگوریتم به صورت مداوم هر نقطه داده را به نزدیکترین مرکز خوشه اختصاص میدهد. جهت حرکت به سمت مرکز خوشه نیز با توجه به تراکم نقاط اطراف داده تعیین میشود. بنابراین، در هر تکرار، هر نقطه داده به سمت جایی حرکت میکند که بیشترین تراکم نقاط وجود دارد که این مکان، همان مرکز خوشه محسوب میشود. هنگامی که الگوریتم متوقف میشود، هر نقطه به یک خوشه اختصاص داده شده است.
برخلاف الگوریتم خوشهبندی پرکابرد K-Means، الگوریتم تغییر میانگین نیازی به مشخص کردن تعداد خوشهها از قبل ندارد و تعداد خوشهها با توجه به دادهها توسط خود الگوریتم تعیین میشود. در قطعه کد زیر مثالی از نحوه استفاده از الگوریتم تغییر میانگین برای خوشهبندی دادهها ارائه شده است:
1from numpy import unique
2from numpy import where
3from matplotlib import pyplot
4from sklearn.datasets import make_classification
5from sklearn.cluster import MeanShift
6
7# initialize the data set we'll work with
8training_data, _ = make_classification(
9 n_samples=1000,
10 n_features=2,
11 n_informative=2,
12 n_redundant=0,
13 n_clusters_per_class=1,
14 random_state=4
15)
16
17# define the model
18mean_model = MeanShift()
19
20# assign each data point to a cluster
21mean_result = mean_model.fit_predict(training_data)
22
23# get all of the unique clusters
24mean_clusters = unique(mean_result)
25
26# plot the clusters
27for cluster in mean_clusters:
28 pyplot.scatter(training_data[mean_result == cluster , 0] , training_data[mean_result == cluster , 1] , label= 'Cluster ' + str(cluster))
29pyplot.legend(fontsize="5")
30
31# show the plot
32pyplot.show()در تصویر زیر خروجی قطعه کد بالا را ملاحظه میکنید. الگوریتم تغییر میانگین دادهها را به طور خودکار در ۳ خوشه مجزا قرار داده است:

الگوریتم خوشه بندی سلسله مراتبی تجمعی
الگوریتم خوشهبندی سلسلهمراتبی تجمعی به عنوان یکی از پرکاربردترین الگوریتمهای سلسلهمراتبی خوشهبندی محسوب میشود که از آن میتوان برای گروهبندی اشیاء در خوشهها بر اساس میزان شباهت آنها به یکدیگر استفاده کرد. روال کار خوشهبندی این الگوریتم، از پایین به بالا (bottom-up) است. در این روش، ابتدا هر نقطه داده به یک خوشه جداگانه اختصاص داده میشود و سپس این خوشهها بر اساس میزان شباهت به هم متصل میشوند. به عبارتی، در هر بار تکرار این الگوریتم، خوشههای مشابه با هم ادغام میشوند تا زمانی که همه نقاط داده بخشی از یک خوشه ریشه بزرگ شوند.
الگوریتم خوشهبندی سلسلهمراتبی تجمعی در یافتن خوشههای کوچک بسیار خوب عمل میکند. نتیجه نهایی این الگوریتم شبیه یک دندروگرام یا درختوارهنما است که به شما امکان میدهد خوشهها را پس از اتمام کار الگوریتم به راحتی تجسم کنید. در ادامه، قطعه کدی از زبان برنامه نویسی پایتون ارائه شده است که نحوه استفاده از الگوریتم خوشهبندی سلسلهمراتبی تجمعی را نشان میدهد:
1from numpy import unique
2from numpy import where
3from matplotlib import pyplot
4from sklearn.datasets import make_classification
5from sklearn.cluster import AgglomerativeClustering
6
7# initialize the data set we'll work with
8training_data, _ = make_classification(
9 n_samples=1000,
10 n_features=2,
11 n_informative=2,
12 n_redundant=0,
13 n_clusters_per_class=1,
14 random_state=4
15)
16
17# define the model
18agglomerative_model = AgglomerativeClustering(n_clusters=5)
19
20# assign each data point to a cluster
21agglomerative_result = agglomerative_model.fit_predict(training_data)
22
23# get all of the unique clusters
24agglomerative_clusters = unique(agglomerative_result)
25
26# plot the clusters
27for cluster in agglomerative_clusters:
28 pyplot.scatter(training_data[agglomerative_result == cluster , 0] , training_data[agglomerative_result == cluster , 1] , label= 'Cluster ' + str(cluster))
29pyplot.legend(fontsize="8")
30
31# show the plot
32pyplot.show()تصویر زیر، خروجی قطعه کد بالا را نشان میدهد.

الگوریتم کاهش بعد PCA در یادگیری ماشین
در پاسخ به پرسش یادگیری نظارت نشده چیست و چه کاربردی دارد، گفته شد که میتوان از این رویکرد یادگیری برای کاهش بعد دادهها نیز استفاده کرد. یکی از الگوریتمهای رایج کاهش ابعاد، الگوریتم تحلیل مولفههای اصلی یا همان PCA است که از آن میتوان برای آمادهسازی دادهها برای سایر مسائل نظیر خوشهبندی، دستهبندی و رگرسیون استفاده کرد.
به منظور درک بهتر از نحوه پیادهسازی و کاربرد الگوریتم PCA میتوان از یک مثال ساده کمک گرفت. فرض کنید میخواهید یک دستهبند ساده با استفاده از الگوریتم «لجستیک رگرسیون» (Logistic Regression) پیادهسازی کنید. میتوانید بدین منظور از قطعه کد زیر استفاده کنید. دادههای آموزشی یا همان X و مقادیر هدف یا همان y با استفاده از کتابخانه Sklearn و دستو make_classification
تولید شدهاند. هر یک از دادههای آموزشی ۲۰ بعدی هستند و بنا است که با الگوریتم لجستیک رگرسیون دستهبندی را آموزش دهیم تا بتواند دادهها را در ۲ کلاس گروهبندی کند:
1# evaluate logistic regression model on raw data
2from numpy import mean
3from numpy import std
4from sklearn.datasets import make_classification
5from sklearn.model_selection import cross_val_score
6from sklearn.model_selection import RepeatedStratifiedKFold
7from sklearn.linear_model import LogisticRegression
8import time
9# define dataset
10X, y = make_classification(n_samples=1000, n_features=20, n_informative=10, n_redundant=10, random_state=7)
11
12# define the model
13model = LogisticRegression()
14
15# evaluate model
16cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
17t0 = time.time()
18n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
19t1 = time.time()
20
21# report performance
22print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
23print('Time: %.3f' % (t1 - t0))با اجرای مثال بالا، الگوریتم رگرسیون لجستیک مجموعه داده خام با تمام ۲۰ ویژگی را ارزیابی میکند و در زمان ۱.۵۸ به دقت حدود ۸۲ درصد میرسد که در ادامه خروجی آن را ملاحظه میکنید:
Accuracy: 0.824 (0.034) Time: 1.581
استفاده از روش کاهش ابعاد میتواند هم میزان حجم محاسباتی الگوریتمهای یادگیری ماشین را کاهش دهد و هم ممکن است در افزایش میزان دقت عملکرد مدل تاثیرگذار باشد. در ادامه، قطعه کدی را ملاحظه میکنید که با استفاده از روش PCA دادههای آموزشی مثال قبل را که ۲۰ بعدی بودند، به ۱۰ بعد کاهش دادیم:
1# evaluate pca with logistic regression algorithm for classification
2from numpy import mean
3from numpy import std
4from sklearn.datasets import make_classification
5from sklearn.model_selection import cross_val_score
6from sklearn.model_selection import RepeatedStratifiedKFold
7from sklearn.pipeline import Pipeline
8from sklearn.decomposition import PCA
9from sklearn.linear_model import LogisticRegression
10import time
11
12# define dataset
13X, y = make_classification(n_samples=1000, n_features=20, n_informative=10, n_redundant=10, random_state=7)
14
15# define the pipeline
16steps = [('pca', PCA(n_components=10)), ('m', LogisticRegression())]
17model = Pipeline(steps=steps)
18
19# evaluate model
20cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
21t0 = time.time()
22n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
23t1 = time.time()
24
25# report performance
26print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
27print('Time: %.3f' % (t1 - t0))خروجی قطعه کد بالا را در ادامه ملاحظه میکنید:
Accuracy: 0.824 (0.034) Time: 0.553
همانطور که دیده میشود، استفاده از روش کاهش بعد PCA در افزایش میزان دقت الگوریتم لجستیک رگرسیون تاثیری نداشته اما زمان یادگیری مدل را به طور چشمگیری کاهش داده است.
الگوریتم SDV برای کاهش بعد
از دیگر روشهای یادگیری نظارت نشده، روش «تجزیه مقادیر منفرد» (Singular Value Decomposition | SVD) است که از آن برای کاهش ابعاد دادهها استفاده میشود. این روش کاهش بعد مناسب دادههایی است که از مقدار زیادی عدد صفر تشکیل شدهاند. به منظور استفاده از این الگوریتم میتوان همانند روش PCA از کتابخانه Sklearn پایتون استفاده کرد. در ادامه، قطعه کدی ارائه شده است که نحوه استفاده از روش SVD را برای کاهش ابعاد دادهها و دستهبندی آنها با استفاده از الگوریتم لجستیک رگرسیون نشان میدهد:
1from numpy import mean
2from numpy import std
3from sklearn.datasets import make_classification
4from sklearn.model_selection import cross_val_score
5from sklearn.model_selection import RepeatedStratifiedKFold
6from sklearn.pipeline import Pipeline
7from sklearn.decomposition import TruncatedSVD
8from sklearn.linear_model import LogisticRegression
9import time
10
11# define dataset
12X, y = make_classification(n_samples=1000, n_features=20, n_informative=10, n_redundant=10, random_state=7)
13
14# define the pipeline
15steps = [('svd', TruncatedSVD(n_components=10)), ('m', LogisticRegression())]
16model = Pipeline(steps=steps)
17
18# evaluate model
19cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
20t0 = time.time()
21n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
22t1 = time.time()
23
24# report performance
25print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
26print('Time: %.3f' % (t1 - t0))خروجی قطعه کد بالا در ادامه ملاحظه میشود. بر اساس نتایج ارائه شده میبینیم که الگوریتم SVD زمان یادگیری مدل را تا حدی کاهش داده است اما برای مثال حاضر، در مقایسه با الگوریتم PCA در کاهش زمان به خوبی عمل نمیکند.
Accuracy: 0.824 (0.034) Time: 1.382
الگوریتم آنالیز تشخیصی خطی برای کاهش بعد
الگوریتم آنالیز تشخیصی خطی یا LDA از دیگر روشهای یادگیری نظارت نشده است که برای کاهش ابعاد دادهها کاربرد دارد. با استفاده از این روش میتوان ابعاد دادهها را بین بازه 1 تا C-1 کاهش داد که عدد C تعداد کلاسهای مسئله دستهبندی را نشان میدهد.
به عنوان مثال، اگر الگوریتم دستهبند شما قرار است دادهها را در ۳ کلاس جای دهد، میتوان دادهها به ابعاد یک بعدی یا دو بعدی تغییر شکل داد. در ادامه، قطعه کدی از پایتون را ملاحظه میکنید که نحوه استفاده از الگوریتم LDA را به منظور کاهش ابعاد دادهها نشان میدهد تا بتوان از دادههای جدید با ابعاد کمتر را برای آموزش دستهبند لجستیک رگرسیون استفاده کرد:
1# evaluate lda with logistic regression algorithm for classification
2from numpy import mean
3from numpy import std
4from sklearn.datasets import make_classification
5from sklearn.model_selection import cross_val_score
6from sklearn.model_selection import RepeatedStratifiedKFold
7from sklearn.pipeline import Pipeline
8from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
9from sklearn.linear_model import LogisticRegression
10import time
11
12# define dataset
13X, y = make_classification(n_samples=1000, n_features=20, n_informative=10, n_redundant=10, random_state=7)
14
15# define the pipeline
16steps = [('lda', LinearDiscriminantAnalysis(n_components=1)), ('m', LogisticRegression())]
17model = Pipeline(steps=steps)
18
19# evaluate model
20cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
21t0 = time.time()
22n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
23t1 = time.time()
24
25# report performance
26print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
27print('Time: %.3f' % (t1 - t0))خروجی قطعه کد بالا را در ادامه ملاحظه میکنید. با استفاده از الگوریتم LDA زمان آموزش مدل به طور چشمگیری کاهش پیدا کرد اما در دقت عملکرد مدل تاثیر زیادی حاصل نشده است:
Accuracy: 0.825 (0.034) Time: 0.253
الگوریتم Isomap Embedding برای کاهش بعد داده در یادگیری ماشین
روش Isomap از دیگر روشهای یادگیری نظارت نشده برای کاهش ابعاد دادهها محسوب میشود. در این روش، از دادههایی که ابعاد بالایی دارند، دادههای جدید با ابعاد کم ساخته میشود. به هنگام استفاده از این الگوریتم، میتوان تعداد ابعاد دادهها را مشخص کرد تا الگوریتم دادههای اصلی را به ابعاد جدید تغییر دهد. در ادامه، قطعه کدی از زبان برنامه نویسی پایتون را ملاحظه میکنید که از این الگوریتم برای کاهش بعد دادهها استفاده شده است. سپس، این دادههای جدید با ابعاد پایین برای آموزش مدل لجستیک رگرسیون برای دستهبندی دادهها به کار رفتهاند:
1# evaluate isomap with logistic regression algorithm for classification
2from numpy import mean
3from numpy import std
4from sklearn.datasets import make_classification
5from sklearn.model_selection import cross_val_score
6from sklearn.model_selection import RepeatedStratifiedKFold
7from sklearn.pipeline import Pipeline
8from sklearn.manifold import Isomap
9from sklearn.linear_model import LogisticRegression
10
11# define dataset
12X, y = make_classification(n_samples=1000, n_features=20, n_informative=10, n_redundant=10, random_state=7)
13
14# define the pipeline
15steps = [('iso', Isomap(n_components=10)), ('m', LogisticRegression())]
16model = Pipeline(steps=steps)
17
18# evaluate model
19cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
20n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
21
22# report performance
23print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))خروجی قطعه کد بالا در ادامه ملاحظه میشود. همانطور که میبینید، الگوریتم کاهش بعد Isomap با فشردهسازی دادهها باعث شده است که دقت عملکرد مدل لجستیک رگرسیون بیشتر شود:
Accuracy: 0.888 (0.029)
الگوریتم اپریوری در یادگیری ماشین
تا به اینجای مطلب، به این موضوع پرداختیم که یادگیری نظارت نشده چیست و برخی از مهمترین الگوریتمهای خوشهبندی و کاهش بعد این رویکرد از یادگیری ماشین را شرح دادیم. در این بخش، به نحوه پیادهسازی سومین روش یادگیری نظارت نشده، یعنی قوانین همبستگی دادهها، میپردازیم. یکی از معروفترین الگوریتمهای قوانین همبستگی، الگوریتم «اپریوری» (Apriori) است که سه پارامتر مهم دارد:
- «پشتیبانی» (Support): این پارامتر نشان دهنده این است که یک مجموعه آیتم در کل دادهها چند بار ظاهر میشود. به عبارتی، این پارامتر درصد تراکنشهایی از خرید مشتریان است که شامل آیتمهای خاص هستند. مقدار پشتیبانی بالاتر نشاندهنده رایجتر بودن مجموعه آیتمها در مجموعه داده است. برای مثال، در نظر بگیرید مجموعه دادهای از تراکنشهای مشتریان در یک فروشگاه مواد غذایی داریم. اگر مقدار پشتیبانی آیتمهای «سیب و موز» برابر با ۲۰ درصد باشد، بدین معنا است که ۲۰ درصد از تمام تراکنشهای خرید مشتریان شامل آیتمهای سیب و موز هستند.
- «اطمینان» (Confidence): این پارامتر نشان دهنده احتمال ظاهر شدن یک آیتم با آیتم دیگر است. به بیان واضحتر، با استفاده از این پارامتر میتوان این احتمال را محاسبه کرد که اگر آیتم A در یک تراکنش ظاهر شود، آیتم B نیز ظاهر شود. مقدار اطمینان بالاتر نشان دهنده حتمال بیشتر خرید دو آیتم با هم است. برای مثال، اگر میزان اطمینان برای قانون «اگر سیب -> آنگاه موز» ۷۵ درصد باشد، به این معنی است که ۷۵ درصد از تراکنشهای شامل خرید سیب، میوه موز را نیز دارند.
- «ارتقا» (Lift): این پارامتر نشان دهنده میزان قویی بودن ارتباط بین دو آیتم است. این مقدار را با مقایسه «فراوانی» (Frequency) مشاهده شده از رخداد همزمان آیتمها نسبت به فراوانی مورد انتظار در صورت مستقل بودن هر یک از آیتمها اندازهگیری میشود. مقدار این پارامتر هر چقدر زیاد باشد، نشان دهنده احتمال بیشتر رخ دادن دو آیتم با هم است در مقایسه با آنچه انتظار میرود. برای مثال، اگر مقدار پارامتر ارتقا برای قانون «اگر سیبها -> آنگاه موز» برابر با عدد ۵ باشد، به این معنی است که احتمال خرید موز اگر سیب بخرید، پنج برابر بیشتر از احتمال خرید موز بدون خرید سیب است.
حال میتوانیم یک مثال برنامه نویسی برای پیادهسازی الگوریتم اپریوری ارائه دهیم. برای این مثال، از سه کتابخانه پایتون به صورت زیر استفاده میکنیم:
1import pandas as pd
2import numpy as np
3from mlxtend.frequent_patterns import apriori, association_rulesبرای دادههای آموزشی، از سایت Kaggle استفاده کردیم و مجموعه دادهای از محصولات فروشگاه [+] را برای آموزش مدل اپریوری انتخاب کردیم. با دستور زیر، بخشی از دادهها را میتوانیم ملاحظه کنیم:
1df = pd.read_csv('GroceryStoreDataSet.csv', names = ['products'], sep = ',')
2df.head()خروجی قطعه کد بالا در ادامه نشان داده شده است:

میتوان با قطعه کد زیر، دادههای آموزشی را درون یک ساختمان داده «لیست» (List) ذخیره کرد:
1data = list(df["products"].apply(lambda x:x.split(",") ))
2dataخروجی قطعه کد بالا را در ادامه ملاحظه میکنید:
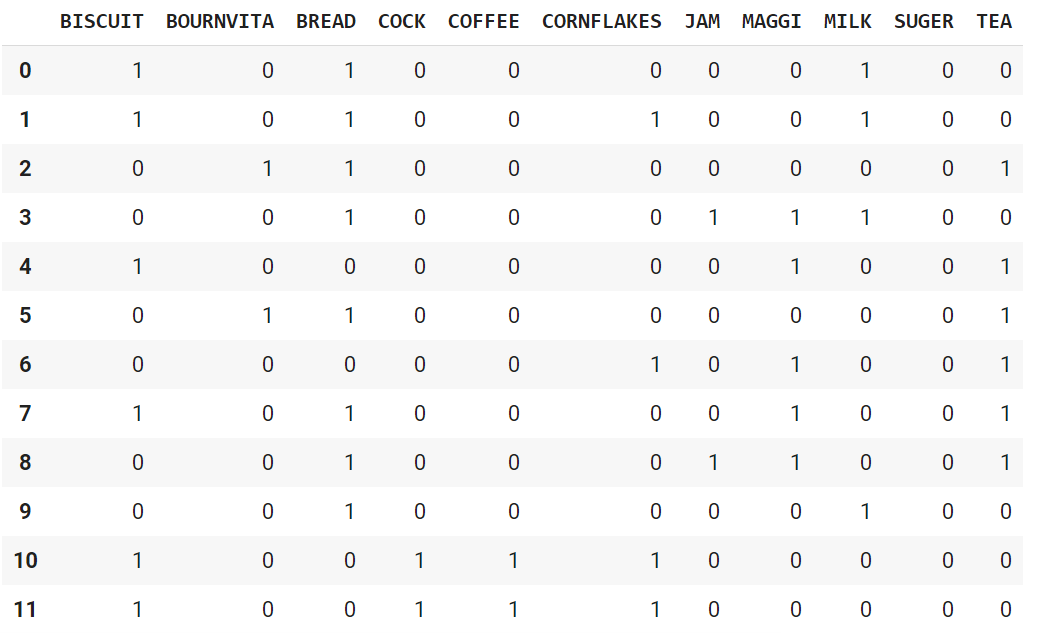
[['MILK', 'BREAD', 'BISCUIT'], ['BREAD', 'MILK', 'BISCUIT', 'CORNFLAKES'], ['BREAD', 'TEA', 'BOURNVITA'], ['JAM', 'MAGGI', 'BREAD', 'MILK'], ['MAGGI', 'TEA', 'BISCUIT'], ['BREAD', 'TEA', 'BOURNVITA'], ['MAGGI', 'TEA', 'CORNFLAKES'], ['MAGGI', 'BREAD', 'TEA', 'BISCUIT'], ['JAM', 'MAGGI', 'BREAD', 'TEA'], ['BREAD', 'MILK'], ['COFFEE', 'COCK', 'BISCUIT', 'CORNFLAKES'], ['COFFEE', 'COCK', 'BISCUIT', 'CORNFLAKES'], ['COFFEE', 'SUGER', 'BOURNVITA'], ['BREAD', 'COFFEE', 'COCK'], ['BREAD', 'SUGER', 'BISCUIT'], ['COFFEE', 'SUGER', 'CORNFLAKES'], ['BREAD', 'SUGER', 'BOURNVITA'], ['BREAD', 'COFFEE', 'SUGER'], ['BREAD', 'COFFEE', 'SUGER'], ['TEA', 'MILK', 'COFFEE', 'CORNFLAKES']]
&
nb
sp;
برای این که دادهها به لحاظ ابعاد یکسانسازی شوند، میتوان آنها را به بردارهایی با اعداد صفر و یک تبدیل کرد. در قطعه کد زیر، نحوه تغییر دادهها را ملاحظه میکنید:
1#Let's transform the list, with one-hot encoding
2from mlxtend.preprocessing import TransactionEncoder
3a = TransactionEncoder()
4a_data = a.fit(data).transform(data)
5df = pd.DataFrame(a_data,columns=a.columns_)
6df = df.replace(False,0)
7df = df.replace(True,1)
8dfخروجی قطعه کد بالا در تصویر زیر نشان داده شده است:
قدم بعدی استفاده از مدل اپریوری است. در این بخش میتوانید حداقل مقدار پارامتر پشتیبانی را تعیین کنید که در این مثال، این پارامتر با مقدار ۲۰ درصد (۰.۲) مقداردهی شده است:
1#set a threshold value for the support value and calculate the support value.
2df = apriori(df, min_support = 0.2, use_colnames = True, verbose = 1)
3dfدر تصویر زیر، خروجی قطعه کد بالا را ملاحظه میکنید:

در این گام، مقدار پارامتر اطمینان را مشخص میکنید که نشان میدهد اگر محصول X خریداری شد، احتمال خرید محصول Y معادل مقدار پارامتر اطمینان باشد. در قطعه کد زیر، مقدار این پارامتر برابر با ۶۰ درصد (۰.۶) انتخاب شده است:
1#Let's view our interpretation values using the Associan rule function.
2df_ar = association_rules(df, metric = "confidence", min_threshold = 0.6)
3df_arخروجی قطعه کد بالا را در ادامه ملاحظه میکنید:

سطر اول جدول بالا را میتوان به این صورت تفسیر کرد:
- احتمال خرید Suger برابر با ۳۰ درصد است.
- احتمال خرید Suger به همراه Bread برابر با ۶۵ درصد است.
- ۶۷ درصد افرادی که Suger میخرند، Bread هم میخرند.
- افرادی که Suger میخرند، احتمالا نسبت به افرادی که Suger خریداری نمیکنند، ۳ درصد Bread بیشتری مصرف میکنند.
جمعبندی
یادگیری ماشین یکی از مهمترین و پرکاربردترین شاخههای هوش مصنوعی محسوب میشود که با استفاده از روشهای آن میتوان بسیاری از امور مختلف را به ماشین محول کرد تا در سریعترین زمان و با دقت بالا وظایف مختلفی را انجام دهد. الگوریتمهای یادگیری ماشین به لحاظ نحوه یادگیری مسئله و دادههای آموزشی مورد نیاز به انواع مختلفی تقسیم میشوند که یکی از مهمترین رویکردهای یادگیری ماشین لرنینگ، یادگیری نظارت نشده است. در این مطلب از مجله فرادرس سعی داشتیم به این پرسش پاسخ دهیم که یادگیری نظارت نشده چیست و چه کاربردهایی دارد. به علاوه، به مزایا و معایب این رویکرد از ماشین لرنینگ اشاره کردیم و به معرفی پرکاربردترین الگوریتمهای آن پرداختیم. در انتهای مطلب نیز با ارائه مثالهای عملی از زبان برنامه نویسی پایتون، نحوه پیادهسازی این الگوریتمها را آموزش دادیم.
source