یادگیری ماشین یا ماشین لرنینگ، زیرشاخهای از هوش مصنوعی و متمرکز بر توسعه مدلها و الگوریتمهایی است که به کامپیوتر امکان میدهند از دادهها یاد گرفته و بدون آنکه از طریق برنامهنویسی به آن فرمان داده شود و تنها از طریق تجربیات پیشین، عملکرد خود را در کاربردهای مختلف بهبود بخشد. به بیان سادهتر، یادگیری ماشین با فرا گرفتن الگوهای موجود در دادهها، به سیستمها یاد میدهد چگونه مانند انسان فکر کنند. در این مطلب از مجله فرادرس، با انواع یادگیری ماشین آشنا شده و به اهمیت آن در ادامه مسیر فعالیت در این حوزه پی میبریم. در حقیقت یادگیری ماشین نوعی سیستم آموزشی است که از تجربیات گذشته درس گرفته و با گذشت زمان پیشرفت میکند. با استفاده از انواع روش های یادگیری ماشین، میتوانیم اطلاعات و رویدادهای بسیاری را پیشبینی کرده و به نتایج ارزشمندی دست پیدا کنیم.
در این مطلب از مجله فرادرس، پس از ارائه شرح کلی از انواع یادگیری ماشین، چهار گروه اصلی روشهای یادگیری ماشین را با طرح مثالی کاربردی بررسی میکنیم. سپس با رایجترین روشهای این چهار گروه از انواع یادگیری ماشین آشنا شده و مزایا، معایب و کاربردهای هر کدام را تشریح میکنیم. در انتهای این مطلب نیز به چند نمونه از سوالات متداول این حوزه پاسخ میدهیم.
انواع یادگیری ماشین چیست؟
هر یک از روشهای انواع یادگیری ماشین، ویژگیها و کاربردهای خاصی دارد. به عنوان برخی از انواع روشهای یادگیری ماشین میتوان به موارد زیر اشاره کرد:
- «یادگیری ماشین نظارت شده» (Supervised Machine Learning)
- «یادگیری ماشین نظارت نشده» (Unsupervised Machine Learning)
- «یادگیری ماشین نیمه نظارت شده» (Semi-Supervised Machine Learning)
- «یادگیری تقویتی» (Reinforcement Learning)

در ادامه، به شرح انواع یادگیری ماشین فهرست شده در لیست بالا پرداخته و توضیح جامعی از هر کدام ارائه میدهیم.
یادگیری ماشین نظارت شده چیست؟
به فرایندی که در آن مدل با «مجموعهدادهای برچسبگذاری شده» (Labelled Dataset) آموزش ببیند، «یادگیری نظارت شده» (Supervised Learning) گفته میشود. مجموعهدادههای برچسبگذاری شده، هم پارامترهای ورودی و هم خروجی را شامل میشوند و الگوریتمهای یادگیری نظارت شده، نقاط داده ورودی را با خروجیهای مرتبط تطبیق میدهند. در یادگیری نظارت شده هر دو مجموعهداده «آموزشی» (Training) و «اعتبارسنجی» (Validation) برچسبگذاری شده هستند.
مثال یادگیری ماشین نظارت شده
فرض کنید قرار است «دستهبند تصویری» (Image Classifier) بسازید که بتواند میان تصاویر سگها و گربهها تمایز قائل شود. اگر از مجموعهدادهای برچسبگذاری شده برای آموزش الگوریتم یادگیری ماشین خود استفاده کنید، مدل یاد میگیرد تصاویر مختلف سگها و گربهها را در گروههایی متفاوت دستهبندی کند. پس از فرایند آموزش و هنگام آزمایش سیستم، زمانی که تصویری جدیدی از سگ یا گربه به آن داده شود، مدل یادگیری ماشین از آموختههای خود برای پیشبینی پاسخ بهره میبرد. مثالی از یادگیری نظارت شده که نحوه کارکرد یک مدل «دستهبندی تصویر» (Image Classification) را نشان میدهد. یادگیری نظارت شده به دو روش زیر تقسیم میشود:
- «دستهبندی» (Classification)
- «رگرسیون» (Regression)
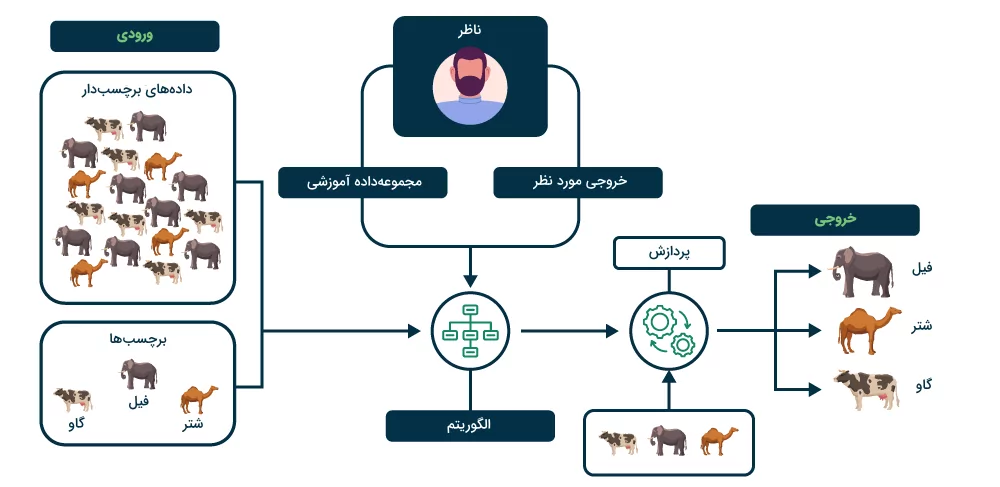
در ادامه، دو روش دستهبندی و رگرسیون را توضیح میدهیم.
دستهبندی
متغیرهای هدف یا همان برچسبهای نهایی در مسائل دستهبندی، ماهیتی «دستهای» (Categorical) داشته و در غالب کلاسهایی قابل شمارش و گسسته به مدل یادگیری ماشین ارائه میشوند. دستهبندی ایمیلهای عادی از اسپم، پیشبینی هوا و پیشبینی خطر بیماری قلبی یک بیمار، از جمله مثالهای مسائل «دستهبندی» (Classification) هستند. الگوریتمهای دستهبندی یاد میگیرند چگونه میان ویژگیهای ورودی و کلاسهای از پیش تعریف شده ارتباط برقرار کنند. از جمله الگوریتمهای دستهبندی میتوان به موارد زیر اشاره کرد:
رگرسیون
برخلاف مسائل دستهبندی، در «رگرسیون» (Regression) مقادیر خروجی پیوسته بوده و با مقادیر عددی به نمایش گذاشته میشوند. پیشبینی قیمت خانه بر اساس اندازه، موقعیت مکانی و امکانات یا پیشبینی میزان فروش یک محصول خاص نمونههایی از مسائل رگرسیون هستند. الگوریتمهای رگرسیون ویژگیهای ورودی را با مقادیر عددی پیوسته تطبیق میدهند. در زیر برخی از انواع رایج رگرسیون را فهرست کردهایم:

مزایای یادگیری ماشین نظارت شده
از جمله مزایای روشهای یادگیری نظارت شده میتوان به موارد زیر اشاره کرد:
- از آنجایی که آموزش مدلهای نظارت شده با دادههای برچسبدار انجام میشود، دقت عملکرد نهایی بالا خواهد بود.
- فرایند تصمیمگیری در مدلهای نظارت شده اغلب قابل درک و تفسیر است.
- بهمنظور ذخیره زمان و منابع، میتوان از مدلهای نظارت شده و از پیش آموزش دیده در کاربردهای متفاوت دیگری نیز استفاده کرد.
معایب یادگیری ماشین نظارت شده
یادگیری ماشین نظارت شده معایبی نیر دارد که چند نمونه از آنها را فهرست کردهایم:
- یادگیری نظارت شده در تشخیص الگوها با محدودیت مواجه است و شاید نتواند الگوهای نا آشنا و جدیدی را که در مجموعه آموزشی وجود نداشتهاند بهدرستی پیشبینی کند.
- پیچیدگی زمانی و هزینه زیاد ناشی از دادههای برچسبگذاری شده، یکی دیگر از معایب یادگیری نظارت شده است.
- از عملکرد ضعیف در تعمیم آموختهها به دادههای جدید یا همان «عمومیسازی» (Generalization) به عنوان نمونهای دیگر از معیاب یادگیری نظارت شده یاد میشود.
کاربردهای یادگیری ماشین نظارت شده
یادگیری ماشین نظارت شده در کابردهای متنوعی مورد استفاده قرار میگیرد:
- «دستهبندی تصویر» (Image Classification): شناسایی اشیاء، چهرهها و دیگر ویژگیهای موجود در تصاویر.
- «پردازش زبان طبیعی» (Natural Language Processing): استخراج اطلاعاتی همچون احساسات، موجودیتها و روابط از متن.
- «تشخیص گفتار» (Speech Recognition): تبدیل زبان محاوره به متن.
- «سیستمهای توصیهگر» (Recommendation Systems): ارائه پیشنهادات شخصیسازی شده به کاربران.
- «تحلیلهای پیشگویانه» (Predictive Analytics): پیشبینی خروجیهایی مانند میزان فروش، نرخ بازگشت مشتری و قیمت سهام.
- «تشخیص پزشکی» (Medical Diagnosis): شناسایی انواع بیماری و دیگر شرایط پزشکی.
- «تشخیص کلاهبرداری» (Fraud Detection): کشف و تشخیص تراکنشهای جعلی.
- «اتومبیلهای خودران» (Autonomous Vehicles): در لحظه واکنش نشان دادن و تشخیص موانع جاده.
- «تشخیص ایمیلهای اسپم» (Email Spam Detection): جداسازی ایمیلهای عادی از اسپم.
- «کنترل کیفیت در تولید» (Quality Control in Manufacturing): ارزیابی کیفیت محصول و معایب آن.
- «رتبهبندی اعتبار» (Credit Scoring): ارزیابی احتمال عدم پرداخت به موقع وام توسط فرد وام گیرنده.
- «بازی» (Gaming): تشخیص کاراکترها، بررسی رفتار بازیکنان و ساخت «کاراکترهای غیر بازیکن» (Non-Player Characters | NPCs).
- «خدمات مشتریان» (Customer Support): خودکارسازی وظایف مرتبط با خدمات مشتریان.
- «پیشبینی آبوهوا» (Weather Forecasting): پیشبینی دما، میزان بارش و دیگر پارامترهای هواشناختی.
- «تجزیه و تحلیل ورزشی» (Sports Analytics): بررسی عملکرد بازیکنان، پیشبینی نتیجه و بهینهسازی استراتژیهای بازی.
یادگیری ماشین نظارت نشده چیست؟
از جمله انواع یادگیری ماشین که در آن مدل، الگوها و روابط را از طریق دادههای بدون برچسب کشف میکند، «یادگیری نظارت نشده» (Unsupervised Learning) میگویند. نحوه کارکرد این روش با یادگیری نظارت شده متفاوت است و دادههای ورودی شامل خروجیهای برچسبگذاری شده نمیشوند. هدف اصلی یادگیری نظارت شده شناسایی الگوهای پنهان، شباهتها یا طبقهبندی مجموعهداده به گونهایست که در کابردهایی همچون «بازیابی داده» (Data Exploration)، «مصورسازی» (Visualization)، «کاهش ابعاد» (Dimensionality Reduction) و سایر موارد مشابه قابل استفاده باشد.
مثال یادگیری ماشین نظارت نشده
مجموعهدادهای را تصور کنید که شامل اقلام خریداری شده شما از فروشگاه است. تکنیک «خوشهبندی» (Clustering) که یکی از انواع روش های یادگیری ماشین نظارت نشده است، در این مسئله به کار آمده و با طبقهبندی الگوهای خرید یکسان میان شما و سایرین، بدون نیاز به پاسخ یا برچسبهای از پیش تعیین شده، مشتریهای بالقوه را شناسایی میکند. کسبوکارها با کمک این اطلاعات، جامعه هدف خود را پیدا کرده و نمونههای پرت یا به اصطلاح Outliers را جدا میکنند. انواع یادگیری ماشین نظارت نشده از دو گروه زیر تشکیل میشود:
- روش «خوشهبندی» (Clustering)
- روش «انجمنی» (Association)
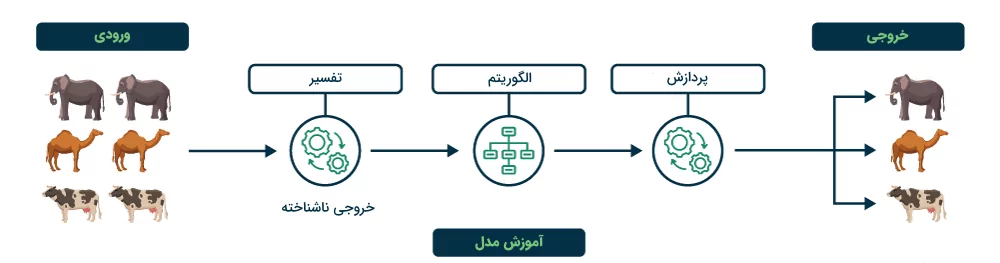
هر یک از این روشها کاربرد خاص خود را داشته که در ادامه به شرح هر کدام میپردازیم.
روش خوشهبندی
فرایند طبقهبندی نقاط داده بر اساس میزان شباهت آنها در به اصطلاح تعدادی خوشه را ، روش «خوشهبندی» (Clustering) مینامند. در این روش، بدون نیاز به نمونههای برچسبگذاری شده، الگوها و روابط ارزشمند میان دادهها شناسایی و کشف میشوند. در فهرست زیر برخی از رایجترین انواع روش خوشهبندی را ملاحظه میکنید:
- الگوریتم «خوشهبندی K میانگین» (K-Means Clustering)
- الگوریتم خوشهبندی Mean-shift
- الگوریتم DBSCAN
- «تحلیل مؤلفه اصلی» (Principal Component Analysis | PCA)
- «تحلیل مؤلفه مستقل» (Independent Component Analysis | ICA)
روش انجمنی
از جمله انواع یادگیری ماشین نظارت نشده که وظیفه آن کشف روابط میان نمونههای یک مجموعهداده است. در روش انجمنی، قواعدی برای تخمین احتمال وجود یک نمونه بر اساس نمونهای دیگر تعریف میشوند. به عنوان چند مورد از انواع روش های یادگیری ماشین انجمنی، میتوان به الگوریتمهای زیر اشاره کرد:
- الگوریتم «اپریوری» (Apriori)
- الگوریتم Eclat
- الگوریتم FP-growth
مزایای یادگیری ماشین نظارت نشده
انواع یادگیری ماشین نظارت نشده مزایایی دارد که در زیر تعدادی از آنها را فهرست کردهایم:
- یادگیری نظارت نشده به کشف الگوهای پنهان و روابط مختلف میان دادهها کمک میکند.
- از یادگیری نظارت نشده در کاربردهایی مانند «بخشبندی مشتریان» (Customer Segmentation)، «تشخیص ناهنجاری» (Anomaly Detection) و بازیابی داده استفاده میشود.
- در یادگیری نظارت شده نیازی به دادههای برچسبگذاری شده نیست؛ از همینرو، مرحله برچسبگذاری دادهها کنار گذاشته میشود.

معایب یادگیری ماشین نظارت نشده
به عنوان برخی از معایب روش های یادگیری نظارت نشده میتوان به موارد زیر اشاره کرد:
- ممکن است سنجش کیفیت خروجی مدل یادگیری ماشین، بدون استفاده از برچسب دشوار باشد.
- درک نحوه کارکرد روش خوشهبندی چندان راحت نیست و تفسیرپذیری بالایی ندارد.
- یادگیری نظارت نشده از تکنیکهایی همچون «خودرمزگذار» (Autoencoder) و کاهش ابعاد تشکیل شده است که بهمنظور استخراج ویژگی از دادههای خام مورد استفاده قرار میگیرند.
کاربردهای یادگیری ماشین نظارت نشده
یادگیری نظارت نشده کاربردهای فراوانی دارد؛ از جمله:
- خوشهبندی: گروهبندی نقاط داده مشابه در خوشههای یکسان.
- تشخیص ناهنجاری: شناسایی نمونههای پرت یا ناهنجاریهای موجود در مجموعهداده.
- کاهش ابعاد: حفظ اطلاعات ضروری همزمان با کاهش ابعاد دادهها.
- سیستمهای توصیهگر: پیشنهاد محصول، فیلم یا محتوایی مطابق با سلیقه و اولویتهای کاربران.
- «مدلسازی موضوعی» (Topic Modeling): کشف موضوعات نهفته در مجموعه اسناد.
- «تخمین چگالی» (Density Estimation): مورد استفاده در تخمین چگالی مجموعهداده.
- فشردهسازی ویدئو و تصویر: کاهش حافظه ذخیرهسازی مورد نیاز محتوای چندرسانهای.
- «پیشپردازش داده» (Data Preprocessing): موثر در اعمالی همچون «پاکسازی داده» (Data Cleaning)، «جانهی» (Imputation)، بررسی «مقادیر ناموجود» (Missing Values) و «مقیاسبندی داده» (Data Scaling).
- «تحلیل سبد بازار» (Market Basket Analysis): کشف پیوستگی میان محصولات.
- «تجزیه و تحلیل دادههای حوزه ژنومشناسی» (Genomic Data Analysis): شناسایی ژنهایی که الگوی مشابهی دارند.
- «قطعهبندی تصویر» (Image Segmentation): قطعهبندی تصاویر به بخشهایی معنیدار.
- شناسایی جوامع در شبکههای اجتماعی: کشف و شناسایی جوامع یا گروههایی با علایق و ارتباطات یکسان.
- بررسی رفتار مشتری: پردهبرداری از الگوها و اطلاعات ارزشمند برای بازاریابی و توصیه محصول بهتر.
- پیشنهاد محتوا: دستهبندی و نشانهگذاری محتوا برای پیشنهاد آسانتر محصولات مشابه به کاربران.
- «تحلیل داده اکتشافی» (Exploratory Data Analysis | EDA): آشنایی بیشتر با مجموعهداده، پیش از تعریف مسئله هدف.
یادگیری ماشین نیمه نظارت شده
همانطور که از اسمش پیداست، یادگیری ماشین نیمه نظارت شده به نوعی میانگین دو روش نظارت شده و نظارت نشده است و در نتیجه هم از دادههای برچسبگذاری شده و هم بدون برچسب استفاده میکند. بیشترین کاربرد یادگیری نیمه نظارت شده هنگامی است که جمعآوری دادههای برچسبگذاری شده هزینهبر بوده و به منابع زیادی نیاز باشد. زمانی استفاده از این روش پیشنهاد میشود که بخش کوچکی از مجموعهداده برچسبگذاری شده و سایر نمونهها بدون برچسب هستند. میتوان ابتدا با روشهای نظارت نشده برچسبها را پیشبینی کرد و سپس از برچسبهای حاصل شده در الگوریتمهای نظارت شده استفاده کرد. دادههای تصویری بهخاطر ضعف در برچسبگذاری کامل نمونهها، از جمله رایجترین کاربردهای یادگیری نیمه نظارت شده هستند.

مثال یادگیری ماشین نیمه نظارت شده
فرض کنید میخواهیم مدلی برای ترجمه زبان طراحی کنیم. آمادهسازی ترجمههای برچسبگذاری شده برای همه جفت عبارتها به منابع محاسباتی زیادی نیاز دارد. در این مثال، یادگیری نیمه نظارت شده از دادههای بدون برچسب و برچسبدار یاد گرفته و عملکرد خود را بهبود میبخشد. روشی که باعث پیشرفت قابل توجهی در کیفیت سرویسهای ترجمه زبانی شده است.
انواع یادگیری ماشین نیمه نظارت شده
انواع روش های یادگیری ماشین نیمه نظارت شده بسیاری وجود داشته که در ادامه، برخی از رایجترین آنها را فهرست کردهایم:
- یادگیری نیمه نظارت شده «مبتنیبر گراف» (Graph-Based): در این روش از گراف برای نمایش ارتباط میان نقاط داده استفاده میشود؛ سپس از طریق گراف، برچسبها از دادههای برچسبگذاری شده به نقاط داده بدون برچسب بسط داده میشوند.
- روش «انتشار برچسب» (Label Propagation): در روش انتشار برچسب، بر اساس شباهت میان نقاط داده، برچسبها از دادههای برچسبدار به دادههای بدون برچسب بسط داده میشوند.
- روش «همآموزی» (Co-training): در این روش، دو مدل یادگیری ماشین با زیرمجموعههای بدون برچسبِ متفاوتی آموزش داده شده و سپس هر کدام خروجیهای دیگری را برچسبگذاری میکند.
- روش «خودآموزی» (Self-training): خودآموزی یکی از انواع روش های یادگیری ماشین نیمه نظارت شده است که تنها یک مدل را ابتدا با دادههای برچسبدار آموزش داده و از همان مدل برای پیشبینی برچسب دادههای بدون برچسب استفاده میکند.
- «شبکههای مولد تخاصمی» (Generative Adversarial Networks | GANs): نوعی الگوریتم یادگیری عمیق که در ساخت دادههای مصنوعی از آن استفاده میشود. شبکه مولد تخاصمی از دو بخش «مولد» (Generator) و «متمایزگر» (Discriminator) تشکیل شده است و با آموزش دادن این دو شبکه عصبی، میتواند دادههای بدون برچسب مورد نیاز یادگیری نیمه نظارت شده را تولید کند.

مزایای یادگیری ماشین نیمه نظارت شده
در فهرست زیر، دو نمونه از مهمترین مزایای یادگیری نیمه نظارت شده را ملاحظه میکنید:
- در مقایسه با یادگیری نظارت شده و از آنجایی که با هر دو نمونه داده برچسبدار و بدون برچسب آموزش میبیند، قابلیت تعمیم یا عمومیسازی بیشتری دارد.
- گستره وسیعی از انواع داده را شامل میشود.
معایب یادگیری ماشین نیمه نظارت شده
یادگیری نیمه نظارت شده نیز با معایبی همراه است؛ از جمله:
- پیادهسازی الگوریتمهای نیمه نظارت شده نسبت به سایر روشها پیچیدهتر است.
- در یادگیری نیمه نظارت شده، همچنان به نسبتی از دادههای برچسبدار نیاز است که شاید همیشه در دسترس نباشند.
- دادههای بدون برچسب ممکن است در عملکرد مدل تاثیر منفی بگذارند.
کاربردهای یادگیری ماشین نیمه نظارت شده
در ادامه تعدادی از رایجترین کاربردهای یادگیری نیمه نظارت شده را فهرست کردهایم:
- دستهبندی تصویر و «تشخیص اشیاء» (Object Recognition): بهبود دقت مدلهای یادگیری ماشین از طریق ترکیب مجموعهای کوچک از تصاویر برچسب گذاری شده با مجموعهای بزرگ از تصاویر بدون برچسب.
- پردازش زبان طبیعی: ارتقاء عملکرد مدلهای زبانی با ترکیب نسبتی کم از متون برچسبدار با حجم زیادی از متون بدون برچسب.
- تشخیص گفتار: بهبود دقت مدلهای تشخیص گفتار با بهرهگیری از تعداد محدودی از دادههای ضبط شده و نسبت بیشتری از محتوای صوتی بدون برچسب.
- سیستمهای توصیهگر: بالا بردن عملکرد سیستمهای توصیهگر شخصیسازی شده از طریق مجموعه «تعاملات کاربر با اقلام» (User-Item Interactions) برچسبگذاری شده و دادههای رفتاری که برچسب ندارند.
- خدمات درمانی و «تصویربرداری پزشکی» (Medical Imaging): بهرهگیری از مجموعه کوچک تصاویر پزشکی برچسبگذاری شده همراه با مجموعهداده بزرگ تصاویر بدون برچسب، برای افزایش کیفیت تصاویر پزشکی در تجزیه و تحلیل علائم بیماری.

یادگیری ماشین تقویتی
الگوریتم «یادگیری تقویتی» (Reinforcement Learning) از جمله انواع یادگیری ماشین است که با ایجاد «عمل» (Action) و کشف «خطا» (Error) به تعامل با محیط میپردازد. آزمون، خطا و تاخیر، سه ویژگی اصلی یادگیری تقویتی را تشکیل میدهند. در این تکنیک، عملکرد مدل با استفاده از سیستم «بازخورد پاداش» (Feedback Reward) بهطور مداوم بهتر میشود. اتومبیلهای خودران شرکت گوگل یا ربات «آلفاگو» (AlphaGo) مثالهایی از الگوریتمهای یادگیری تقویتی هستند. آلفاگو رباتی است که با انسانها و حتی خودش رقابت کرده و به تدریح عملکرد خود را در بازی «گو» (Go) ارتقاء میدهد. هر بار که داده جدیدی مشاهده شود، مدل یادگیری ماشین از آن یاد گرفته و اطلاعات جدیدی به مجموعه آموزشی اضافه میکند. در نتیجه هر چه بیشتر یاد بگیرد، بهتر آموزش دیده و به تجربهاش افزوده میشود. در لیست زیر، به چند نمونه از رایجترین الگوریتمهای یادگیری تقویتی اشاره شده است:
- الگوریتم Q-Learning: الگوریتمی فاقد مدل که با تطبیق دادن هر «شرایط» (State) به «عمل» (Action) متناظر، تابعی به نام Q را یاد میگیرد.
- الگوریتم SARSA: در این روش نیز مانند Q-Learning، تابعی به نام Q یاد گرفته میشود. گرچه برخلاف الگوریتم یادگیری Q، روش SARSA تابع Q را بهجای عمل بهینه، برای عمل انجام شده بهروزرسانی میکند.
- «یادگیری Q عمیق» (Deep Q-Learning): این الگوریتم ترکیبی از الگوریتم Q-Learning و یادگیری عمیق است. روشی که از شبکه عصبی به عنوان تابع Q استفاده میکند. مزیت شبکه عصبی در یادگیری الگوهای پیچیده میان شرایط و عمل خلاصه میشود.

مثال یادگیری ماشین تقویتی
موقعیتی را در نظر بگیرید که قصد دارید «عاملی هوشمند» (AI Agent) را برای انجام بازی مانند شطرنج آموزش دهید. عامل هوشمند در محیط حرکت کرده و بر همین اساس، بازخوردهایی مثبت یا منفی دریافت میکند.
انواع یادگیری ماشین تقویتی
انواع روش های یادگیری ماشین تقویتی به دو گروه «تقویت مثبت» (Positive Reinforcement) و «تقویت منفی» (Negative Reinforcement) تقسیم میشوند که در ادامه این مطلب از مجله فرادرس، شرح مختصری از هر کدام ارائه میدهیم.
تقویت مثبت
روش تقویت مثبت را میتوان با ویژگیهای زیر تعریف کرد:
- پاداش دادن به عامل هوشمند برای انجام عملی خاص.
- تشویق عامل به تکرار رفتار. مانند جایزه دادن به سگ برای نشستن، در تقویت مثبت نیز به ازای هر پاسخ درست، به عامل امتیاز مثبت داده میشود.
تقویت منفی
نوع یادگیری تقویت منفی از طریق ویژگیهای زیر قابل تعریف است:
- حذف محرکهای نامطلوب برای ارزش دادن به نوعی از رفتار.
- تنبیه کردن عامل بهمنظور جلوگیری از تکرار عمل. مانند خاموش کردن آژیر هنگام فشردن یک دکمه، عامل هوشمند نیز با تکمیل کاری که به آن محول شده، از امتیاز منفی جلوگیری میکند.
مزایای یادگیری ماشین تقویتی
از جمله مزایای یادگیری تقویتی میتوان به موارد زیر اشاره کرد:
- وجود تصمیمگیری مستقل و مناسبی که مانند رباتهای هوشمند، دنبالهای از تصمیمات را یاد میگیرد.
- مناسب برای اهدف بلندمدتی که دستیابی به آنها دشوار است.
- قابل استفاده در حل مسائل پیچیدهای که از طریق تکنیکهای رایج قابل حل نیستند.

معایب یادگیری ماشین تقویتی
برخی از معیاب یادگیری ماشین تقویتی را در زیر فهرست کردهایم:
- آموزش عاملهای هوشمند ممکن است از نظر زمانی و محاسباتی هزینهبر باشد.
- استفاده از یادگیری تقویتی برای حل مسائل ساده پیشنهاد نمیشود.
- نیاز به دادههای زیاد و در نتیجه منابع قدرتمند، گاهی یادگیری تقویتی را به گزینهای ناکارآمد تبدیل میکند.
کابردهای یادگیری ماشین تقویتی
موارد زیر تنها چند نمونه از کاربردهای یادگیری تقویتی هستند:
- بازیهای کامپیوتری: با استفاده از یادگیری ماشین تقویتی میتوان نحوه انجام بازیهای کامپیوتری، حتی از نوع پیچیده و سخت آن را به عاملهای هوشمند آموزش داد.
- رباتیک: خودکارسازی کارهای روزمره با آموزش دادن رباتها.
- «وسایل نقلیه خودران» (Autonomous Vehicles): کمک به اتومبیلهای خودران برای جابهجایی و تصمیمگیری.
- سیستمهای توصیهگر: بهبود عملکرد الگوریتمهای توصیهگر از طریق یادگیری اولویتهای کاربری.
- خدمات درمانی: بهینهسازی طرح درمان و اکتشافات دارویی.
- پردازش زبان طبیعی: قابل استفاده در «سیستمهای مکالمهای» (Dialogue Systems) و چتباتها.
- امور مالی و تجارت: بهبود دقت «معاملات الگوریتمی» (Algorithmic Trading).
- زنجیره تأمین و «مدیریت انبار» (Inventory Management): بهینهسازی فرایندهای مورد استفاده در زنجیره تأمین.
- مدیریت انرژی: بهینهسازی مصرف انرژی.
- هوش مصنوعی در بازیهای کامپیوتری: ساخت NPC یا کاراکترهای غیر بازیکن هوشمند و تعاملی در بازیهای ویدئویی.
- «دستیار شخصی» (Personal Assistant): بهبود کارکرد دستیارهای شخصی.
- «واقعیت مجازی» (Virtual Reality | VR) و «واقعیت افزوده» (Augmented Reality | AR): خلق تجربیات تعاملی و جالب توجه.
- «کنترل صنعتی» (Industrial Control): بهینهسازی عملیاتهای صنعتی.
- آموزش و پرورش: ساخت سیستمهای یادگیری تطبیقپذیر.
- کشاورزی: افزایش کارآمدی فرایندهای کشاورزی.
سوالات متداول
پس از آشنایی با انواع یادگیری ماشین، حال زمان خوبی است تا در این بخش به تعدادی از پرسشهای متداول در این زمینه پاسخ دهیم.
یادگیری نظارت شده با چه چالشهایی روبهرو است؟
«عدم توازن کلاسی» (Class Imbalance)، کمبود دادههای برچسبگذاری شده با کیفیت و مشکل «بیشبرازش» (Overfitting) که موجب عملکرد ضعیف مدل نسبت به دادههای جدید میشود، چند نمونه از چالشهای یادگیری نظارت شده هستند.
یادگیری نظارت شده در چه زمینهای کاربرد دارد؟
از انواع یادگیری ماشین نظارت شده در موضوعاتی همچون تحلیل ایمیلهای اسپم، «تشخیص تصویر» (Image Recognition) و «تجزیه و تحلیل احساسات» (Sentiment Analysis) استفاده میشود.
چه چشماندازی برای آینده یادگیری ماشین قابل تصور است؟
میتوان متصور شد که انواع یادگیری ماشین قرار است نقش چشمگیری در زمینههایی مانند پیشبینی و تحلیل آبوهوا، سیستمهای درمانی و مدلسازی خودکار ایفا کنند.

بهطور کلی انواع یادگیری ماشین به چند دسته تقسیم میشوند؟
انواع روش های یادگیری ماشین را میتوان در سه گروه کلی یادگیری نظارت شده، یادگیری نظارت نشده و یادگیری تقویتی دستهبندی کرد.
چه الگوریتم هایی در یادگیری ماشین بیشترین استفاده را دارند؟
الگوریتمهایی که در فهرست زیر آوردهایم، چند نمونه از الگوریتمهای مورد استفاده در یادگیری ماشین هستند:
- رگرسیون خطی
- رگرسیون لجستیک
- ماشین بردار پشتیبان یا SVM
- الگوریتم K-نزدیکترین همسایه یا KNN
- درخت تصمیم
- جنگل تصادفی
- «شبکههای عصبی مصنوعی» (Artificial Neural Networks | ANNs)
الگوریتمهای یادگیری ماشین زیادی وجود دارند و روز به روز نیز به تعداد آنها اضافه میشود. با این حال، مواردی که در فهرست بالا به آنها اشاره کردیم، برخی از رایجترینهای این زمینه هستند.
جمعبندی
هر یک از انواع روش های یادگیری ماشین اهداف مختص به خود را داشته و همه در بهبود عملکرد نهایی مدلهای یادگیری سهیم هستند. همانطور که در این مطلب از مجله فرادرس خواندیم، یادگیری ماشین انواع مختلفی داشته که بسته به نوع مسئله و مجموعهدادهها، در کاربردهای متنوعی مورد استفاده قرار میگیرند. تاثیر انواع یادگیری ماشین به اندازهایست که باعث تحول حوزههایی مانند علم داده شده و امکان مدیریت پایگاههای داده حجیم و بزرگ را برای ما مهیا ساخته است.
source