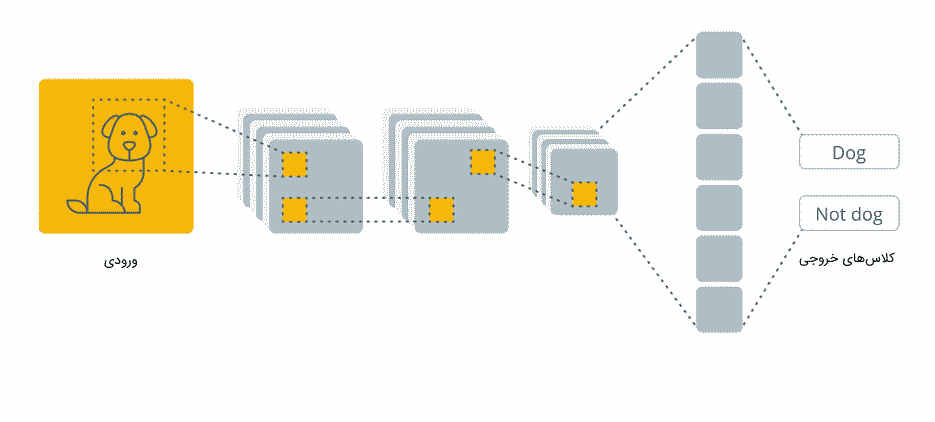
در چند دهه گذشته، یادگیری عمیق به دلیل توانایی در تجزیه و تحلیل دادههایی با حجم بالا، ابزار بسیار قدرتمندی به شمار میآید. یکی از محبوبترین شبکههای عصبی عمیق، به ویژه زمانی که صحبت از کاربرد «بینایی ماشین» (Computer Vision) میشود، «شبکه عصبی کانولوشن» (CNN | Convolutional) نام دارد که با عنوان ConvNet نیز شناخته میشود. همچنین، در مقالات فارسی گاهی اوقات به نام شبکههای پیچشی خطاب میشود. شبکههای عصبی کانولوشن با الهام از ساختار «قشر بینایی» (Visual Cortex) ارائه و بعدها بسیار محبوب شد. این شبکهها قابلیت تشخیص الگوها و ویژگیهای پیچیده در تصاویر را دارند و توانستهاند در زمینههای مختلفی از تشخیص چهره گرفته تا خودروهای خودران، به بهترین نحو ممکن عمل کنند. در این مطلب از مجله فرادرس به این پرسش پاسخ میدهیم که شبکه عصبی کانولوشن چیست و کمی با تاریخچه آن آشنا خواهیم شد. در ادامه، نیز، به معماری و نحوه عملکرد این شبکه بهطور کامل، خواهیم پرداخت. تصویر زیر نمایی کلی از شبکه عصبی کانولوشن نمایش میدهد که برای طبقهبندی تصویر مورد استفاده قرار گرفته است.
در دهه ۱۹۵۰، زمانی که هوش مصنوعی هنوز در مراحل اولیه خود به سر میبرد، محققان در تلاش بودند تا سیستمی بسازند که دادههای بصری را درک کند. این رشته علمی در سالهای بعد با نام بینایی ماشین شناخته شد. در سال ۲۰۱۲، بینایی ماشین با توسعه مدل شبکه عصبی کانولوشن AlexNet توسط گروهی از محققان، تحولی بزرگ را تجربه کرد. این مدل در مسابقه بینایی ماشین ImageNet با اختلاف قابل توجهی، به عنوان برنده، معرفی شد. این موفقیت، علاوه بر نشان دادن پیشرفت در زمینه بینایی ماشین، توانمندی شبکههای عصبی عمیق، به ویژه شبکههای کانولوشن را، در درک و پردازش دادههای بصری به اثبات رساند.
تاریخچه شبکه عصبی کانولوشن
آقای یان لکون، مدیر گروه تحقیقات هوش مصنوعی فیسبوک، پیشگام شبکههای عصبی کانولوشن است. او اولین شبکه عصبی کانولوشن به نام LeNet را در سال ۱۹۸۸ ارائه داد. LeNet برای انجام کارهایی نظیر تشخیص ارقام دستنویس مورد استفاده قرار میگرفت. در سال ۲۰۱۲، گروهی از محققان دانشگاه تورنتو مدل شبکه عصبی را توسعه دادند که توانست از بهترین الگوریتمهای شناسایی تصویر پیشی بگیرد. این مدل، در مسابقه بینایی ماشین ImageNet در همان سال ۲۰۱۲ با دقت بالای ۸۵ درصد برنده مسابقه شد و جالب این است که نایبقهرمان در این آزمون دقت ۷۴ درصد را کسب کرد. این مدل شبکه عصبی که توسط الکس کریژوفسکی به همراه ایلیا سوتسکور و جفری هینتون طراحی و بهنام AlexNet معروف شد که محبوبیت شبکههای عصبی کانولوشن در بین محققان هوش مصنوعی را بهدنبال داشت.
بعد از موفقیت AlexNet، محققان بسیاری به فعالیت در زمینه شبکههای عصبی عمیق و به ویژه شبکههای کانولوشن پرداختند. این پیشرفتها باعث توسعهٔ مدلها و الگوریتمهای بهتر و پیچیدهتری در حوزی بینایی ماشین شد. سپس، معماریهای جدیدی نظیر VGGNet GoogLeNet، و ResNet ارائه شدند که به بهبود عملکرد شبکهها در شناسایی الگوها کمک کردند.
شبکه عصبی کانولوشن چیست؟
شبکه عصبی کانولوشن نوعی از شبکههای عصبی عمیق است که بهطور معمول، برای تجزیه و تحلیل تصاویر استفاده میشود. ممکن است زمانی که صحبت از شبکههای عصبی شود، عملیات ضرب ماتریسها برایتان یادآور شود، اما این امر در مورد شبکههای کانولوشن یا همان ConvNet صدق نمیکند. به عبارتی دیگر یکی از ویژگیهای اصلی شبکههای عصبی کانولوشن استفاده از عملیات کانولوشن بهجای ضرب ماتریسی است. کانولوشن در ریاضیات، عملیاتی است که ۲ تابع را با هم ترکیب میکند تا تابعی جدید ایجاد کند. این تابع جدید نمایانگر تأثیر یکی از آن توابع بر دیگری است. به عبارتی دیگر، کانولوشن اثر یک سیگنال را در سیگنال دومی بررسی میکند. در ادامه، بدون اینکه نیاز باشد وارد جزئیات ریاضی عملگر کانولوشن بشویم، میخواهیم یاد بگیریم که شبکه عصبی کانولوشن چیست و چگونه کار میکند.
در سایر شبکههای عصبی مانند «پرسپترون چند لایه» (Multi Layer Perceptron | mlp) هر لایه شامل تعداد زیادی نورون است که هر نورون به نورونهای لایه بعدی متصل است و در انتها یک لایه «تمام متصل» (Fully Connected Layer) نتیجه پیشبینی را نشان میدهد. اما در شبکههای کانولوشن، نحوه اتصال و تنظیم نورونها به شیوهای متفاوت انجام میشود. شبکه ConvNet از تعدادی لایه کانولوشن تشکیل شده است که در هر لایه، فیلترها ویژگیهای تصویر را استخراج میکنند. این فیلترها بر روی تصویر حرکت میکنند و ویژگیهای مختلف را شناسایی میکنند.
هر فیلتر یا کرنل، یک ماتریس کوچک است که بر روی تصویر ورودی حرکت میکند و ویژگیهای خاصی از تصویر را استخراج میکند. ممکن است از روشهای کلاسیک پردازش تصویر به یاد داشته باشید که فیلترهایی برای تشخیص الگوهایی مانند لبه و غیره به صورت دستی طراحی میشوند. اما، لازم است بدانید که در شبکههای کانولوشن، سلولهای ماتریس فیلتر به صورت دستی طراحی نمیشوند. بلکه، وزن فیلترها به صورت خودکار در طول آموزش شبکه تنظیم میشوند تا ویژگیهای مهم تصویر را استخراج کنند. پیشتر به شبکه «پرسپترون چند لایه» (MLP) اشاره کردیم و تفاوت ساختاری «شبکه کانولوشن» (CNN) با MLP را تا حدودی شناختیم. حال، قبل از اینکه به شرح دقیق عملکرد شبکه کانولوشن بپردازیم، میخواهیم بدانیم که برتری شبکههای کانولوشن به شبکهای مانند MLP در وظایف بینایی ماشین در چیست.

تصاویر، مجموعهای از پیکسلها هستند که هر پیکسل بیانگر رنگ یا شدت نور در یک نقطه از تصویر هستند. میتوان تصاویر را به یک بردار، تبدیل و به پرسپترون چندلایه وارد کرد. اما این روش در مواردی که تصاویر، پیچیده و پیکسلهای آنها به یکدیگر وابسته هستند، کارایی مناسبی ندارد. برای مثال، تصویری با ابعاد ۴۳۲۰ × ۷۶۸۰، معادل ۳۳۱۷۷۶۰۰ پیکسل، برای یک پرسپترون چندلایه محاسبات زیادی نیاز دارد. در پرسپترون چندلایه، هر پیکسل به عنوان یک ویژگی جداگانه مدل میشود. بنابراین، تعداد پارامترهای شبکه به شدت زیاد خواهد شد. از سوی دیگر، شبکههای کانولوشن به جای استفاده از بردار فلت، از فیلترها برای استخراج ویژگیهای مختلف تصویر استفاده میکنند. این فیلترها بهطور خودکار، بر روی تصویر حرکت و ویژگیهای مختلفی را شناسایی میکنند. بنابراین، شبکههای کانولوشن به عنوان یک راهحل بهتر برای پردازش تصاویر با ابعاد بزرگ مطرح میشوند. این شبکهها از فیلترها برای استخراج ویژگیهای تصویر استفاده میکنند و موجب کاهش تعداد پارامترها میشوند.
همچنین، شبکه کانولوشن قادر به درک بهتر وابستگیهای مکانی و زمانی در تصویر هست. معماری ConvNet به دلیل کاهش تعداد پارامترها و قابلیت استفاده مجدد از فیلترها، بهبود قابل توجهی در پردازش تصاویر پیچیده دارد و از دقت بالاتری در پیشبینی طبقهها برخوردار است.
معماری شبکه کانولوشن
معماری شبکههای عصبی کانولوشن به گونهای طراحی شده است که ویژگیهای مهم تصویر را در سطوح مختلف استخراج میکند. این شبکهها از تعدادی لایه تشکیل شدهاند که هر یک وظایف خاص خود را دارند.
- «لایههای کانولوشن» (Convolutional Layers)
- «لایههای ادغام» (Pooling Layers)
- «لایههای تمام متصل» (Fully Connected Layers)

برای اینکه بتوانیم نحوه عملکرد شبکه عصبی کانولوشن را یاد بگیریم، باید به لایههای مختلف آن به صورت جداگانه نگاه کنیم. این کار به ما کمک میکند تا نقش و اهمیت هر لایه را درک کنیم.
لایه کانولوشن
در شبکههای عصبی کانولوشن، لایه کانولوشن نقش اصلی را در انجام محاسبات شبکه بر عهده دارد. این لایه با استفاده از فیلترهایی که الگوهای خاصی را در دادههای ورودی جستجو میکنند، ویژگیهای مهم را از تصاویر استخراج میکند. هر فیلتر، یک ماتریس کوچک از وزنها است که در سراسر تصویر حرکت کرده و حاصل ضرب داخلی بین وزنها و پیکسلهای مربوطه تصویر را محاسبه میکند. نتیجه این محاسبه، «نقشه ویژگی» (Feature Map) یا «نقشه فعالیت» (Activation Map) نامیده میشود. تصویر زیر مفاهیم گفته شده را به خوبی بیان میکند. تصویر زیر نحوه عملیات کانولوشن را نمایش میدهد.
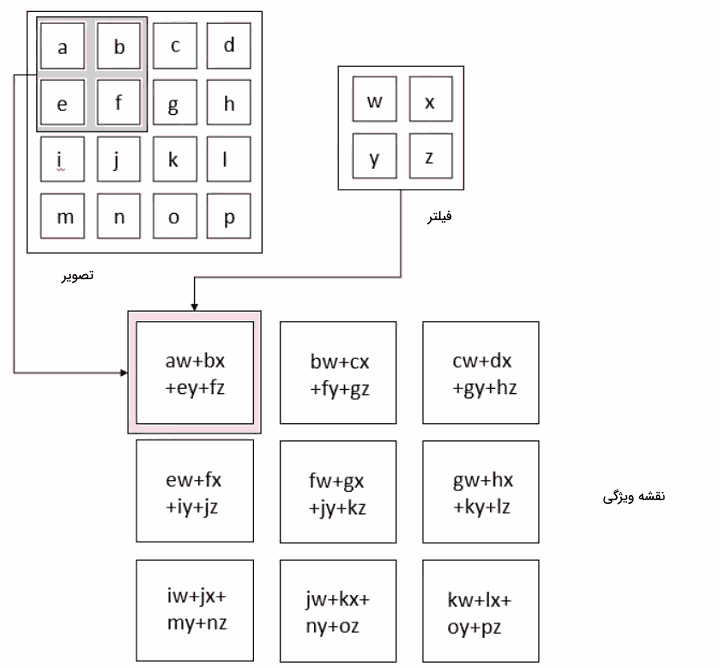
همانطور که از تصویر بالا مشخص است، هر عنصر از تنسور اول یا پیکسل تصویر با عنصر مربوطه از تنسور دوم یا کرنل، ضرب میشود. سپس، تمام مقادیر برای به دست آوردن نتیجه جمع میشوند. با حرکت دادن فیلتر در سراسر تصویر این عملیات تکرار میشود. تصویری که در ادامه، آوردهایم، چگونگی لغزش فیلتر در سراسر پیکسلهای «تصویر» (Image) و نتیجه محاسبات کانولوشن در قسمت مربوطه از «نقشه ویژگی» (Convolved Feature) را نشان میدهد.
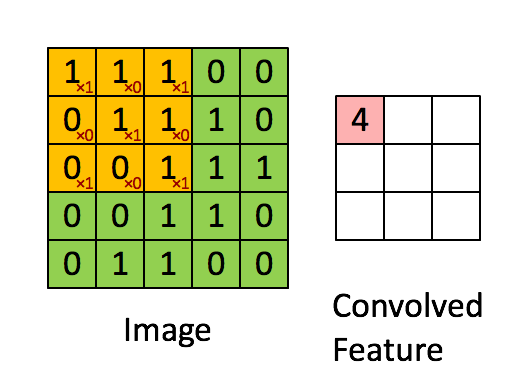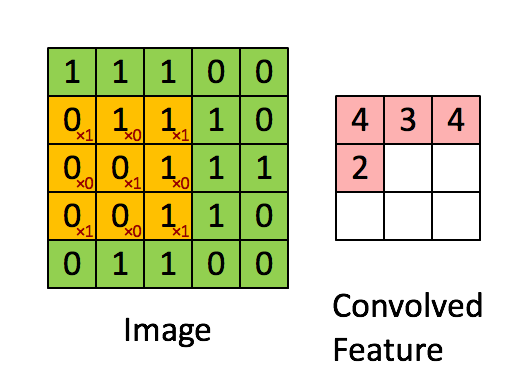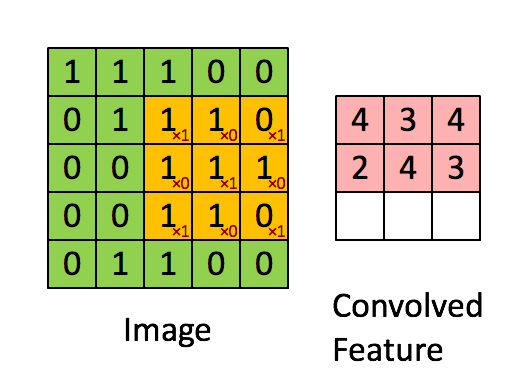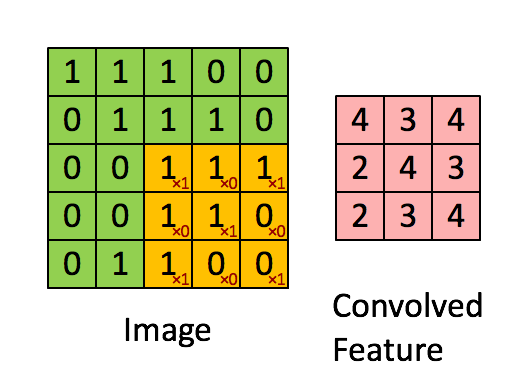
چگونگی عملکرد لایه کانولوشن عمدتاً بهطور عمده، توسط «هایپرپارامترهای» (Hyperparameters) اصلی زیر تعیین میشود.
- «اندازه کرنل» (Kernel size): این معیار همانطور که از نامش پیدا است، اندازه فیلتر را نشان میدهد. معمولا توصیه میشود که ابعاد فیلتر یا همان کرنل، کوچک و ترجیحا فرد، برای مثال، ۱، ۳، ۵ و ۷ باشد. لازم به ذکر است اندازه کرنل ۳×۳ بیشتر مورد استفاده قرار میگیرد.
- «گام» (Stride): پارامتر «stride» میزان جابهجایی پنجره کرنل در هر مرحله از کانولوشن را تعیین میکند. معمولاً این مقدار برابر با ۱ است تا تمام نقاط تصویر مورد بررسی قرار گیرند. با این حال، برای کاهش اندازه ورودی، میتوان این مقدار را افزایش داد.
- «پدینگ» (Padding): پدینگ روشی است که در حواشی تصویر پیکسلهایی با مقدار ۱ را درج کنیم. این عمل، با این هدف انجام میشود که هنگام اعمال فیلتر بر تصویر در عملیات کانولوشن، اندازه نقشه ویژگی ورودی و خروجی تغییر نکند.
- تعداد فیلترها: تعداد فیلترها در لایه کانولوشن، تعداد الگوها یا ویژگیهایی را که لایه به دنبال شناسایی آنها است، تعیین میکند.
بهطور کلی، اندازه خروجی لایه کانولوشن بر اساس چند معیار که در ادامه بیان میکنیم قابل تعیین است.
- اندازه ورودی
- اندازه فیلتر
- پدینگ
رابطه زیر، نحوه محاسبه اندازه خروجی با استفاده از موارد ذکر شده در بالا را نمایش میدهد.
$$H_{out} = 1 + frac{{H_{in}+(2.cdot pad)-K_{height}}}{s}$$
$$W_{out} = 1 + frac{{W_{in}+(2.cdot pad)-K_{width}}}{s}$$
در رابطه اول، $$H_{out}$$ و $$H_{in}$$، به ترتیب بیانگر ارتفاع نقشههای ویژگی ورودی و خروجی هستند. همچنین، pad، اندازه پدینگ – میزان افزودن صفر یا مقداری ثابت را به اطراف نقشه ویژگی ورودی – را نشان میدهد. پارامترهای $$ K_{height} $$ و $$s$$ به ترتیب طول «گام» (Stride) و ارتفاع کرنل را نمایشمیدهند. در رابطه دوم، همین پارامترها در مورد مقادیر عرضی آنها صدق میکند. بنابراین، با استفاده از روابط بالا میتوان ارتفاع و عرض نقشه ویژگی خروجی در لایه کانولوشن را محاسبه کرد. در اینجا مثالی برای درک بهتر مفهوم کانولوشن آوردهایم. فرض کنید تصویر ورودی با ابعاد ۶x۶ پیکسل داریم. برای عملیات کانولوشن، کرنلی با ابعاد ۳x۳ پیکسل و «گام»(Stride) برابر با ۱ در نظر میگیریم و پدینگ استفاده نمیکنیم. اندازه خروجی تصویر بعد از وارد شدن به لایه کانولوشن را می توان با استفاده از رابطه زیر محاسبه کرد.
$$ output_{size} = 1 + (input_{size} – kernel_{size} + (2 * padding)) / stride $$
با استفاده از مقادیر داده شده در مثال، می توانیم به نتیجه زیر دست یابیم.
$$ output_{size} = 1 + (6 – 3 + (2 * 0)) / 1 = 1 + (3 / 1) = 1 + 3 = 4 $$
بنابراین، تصویر خروجی دارای ابعاد ۴×۴ پیکسل خواهد بود.
در شبکههای عصبی کانولوشنی که تصاویری با بیش از یک کانال به عنوان ورودی دریافت میکنند، هر فیلتر باید با تعداد کانالهای ورودی مطابقت داشته باشد. این امر برای حفظ اطلاعات مکانی و ویژگیهای موجود در هر کانال از تصویر اهمیت دارد. برای مثال، در تصاویر RGB که ۳ کانال دارند – یک کانال برای هر یک از رنگهای رنگ قرمز، سبز و آبی است – هر فیلتر نیز باید ۳ بُعد داشته باشد و به ازای هر کانال، وزن متناظر را در خود ذخیره کند که در مرحله بعد، خروجی هر ۳ فیلتر با یکدیگر جمع میشوند. این امر برای حفظ اطلاعات مکانی و ویژگیهای موجود در هر کانال از تصویر اهمیت دارد. به تصویر زیر توجه کنید.
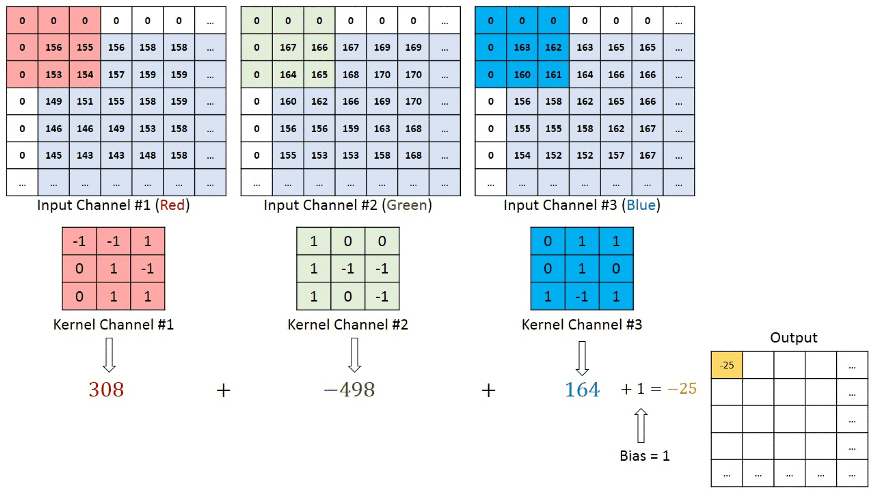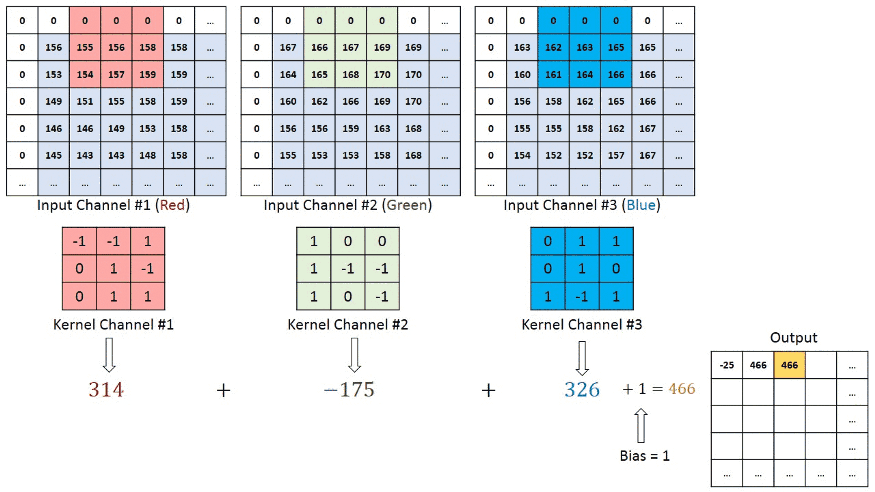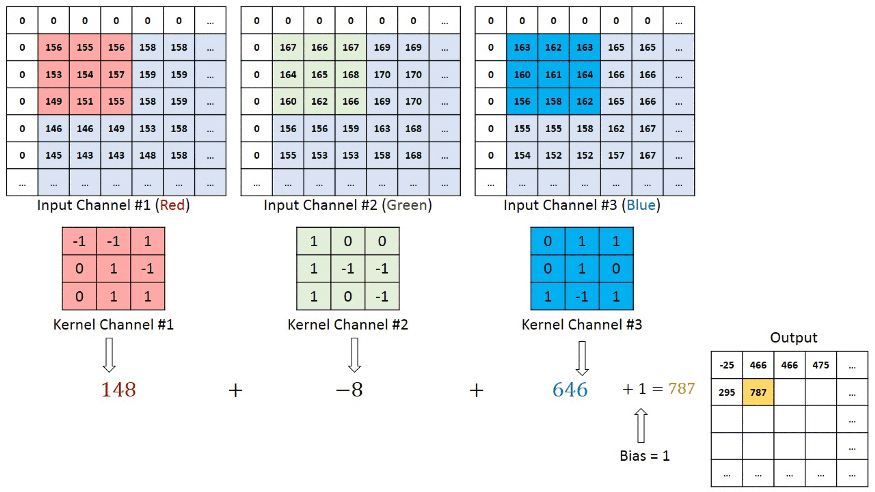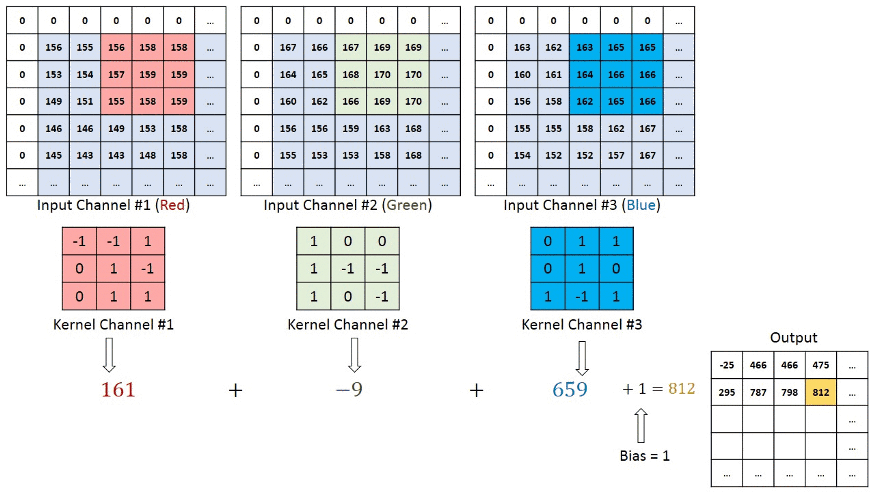
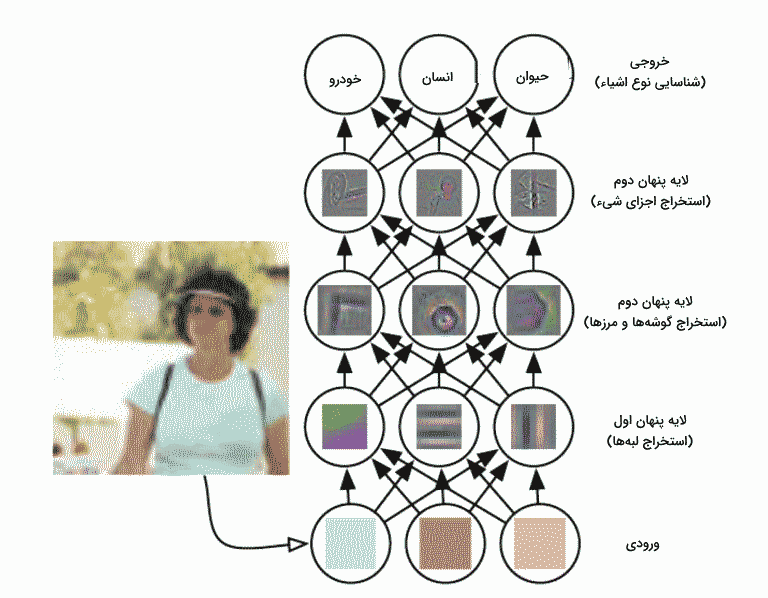
پس از هر عملیات کانولوشن، یک تابع فعالساز غیرخطی، مانند ReLU، به نقشه ویژگی خروجی اعمال میشود. این کار به مدل کمک میکند تا الگوهای پیچیده و غیرخطی را در دادهها شناسایی کند. بهطور کلی، هنگامی که داده ورودی، برای مثال، تصویر وارد شبکه کانولوشن میشود، از لایههای مختلف کانولوشن عبور میکند که هر لایه کانولوشن به نوبه خود وظایفی دارد. به عنوان مثال، لایه اول معمولا ویژگیهای سطح پایینتر مانند لبههای افقی یا قطری را استخراج میکند. خروجی این لایه به لایه بعد منتقل میشود که برای مثال، میتواند ویژگیهای پیچیدهتری مانند گوشهها یا لبههای ترکیبی را استخراج کند. به این ترتیب، هر چه لایهها را به سمت انتهای شبکه پیش برویم به ویژگیهای سطح بالاتری از تصویر دست پیدا میکنیم. ویژگیهای سطح بالا، ویژگیهای پیچیدهتری مانند، اشیاء، چهره و غیره را شناسایی میکند. تصویر زیر، روند پردازش یک تصویر ورودی توسط شبکه عصبی را نشان میدهد. در این روند، ابتدا ویژگیهای اولیه و سپس، ویژگیهایی پیچیدهتری از تصویر استخراج میشوند. در نهایت، ویژگیهای لایه آخر، برای طبقهبندی تصویر مورد استفاده قرار می گیرند.
لایه ادغام
لایههای «ادغام» (Pooling) در شبکههای کانولوشن به منظور کاهش اندازه نقشههای ویژگی و در نتیجه کاهش تعداد پارامترها مورد استفاده قرار میگیرد. علاوه بر این، استفاده از لایه ادغام یکی از بهترین روشها برای افزایش خاصیت «تعمیمپذیری»(Generalization) و پایین آوردن مشکل «بیش برازش» (Overfitting) است.
حال ببینیم فرایند ادغام چگونه صورت میگیرد. همانند لایههای کانولوشن، در فرایند ادغام نیز یک فیلتر بر روی پیکسلهای تصویر حرکت میکند. اما، همانند کرنلهای کانولوشن، این فیلترها وزن ندارند بلکه، فقط با ادغام ویژگیها خروجی مورد نظر حاصل میشود. در ادامه، ۲ نوع عملیات ادغام معرفی میشوند که بیشتر مورد استفاده قرار میگیرند.
- «ادغام بیشینه» (Max Pooling): در این نوع ادغام، یک پنجره مشخص (برای مثال، ۲x۲ یا ۳x۳) بر روی هر قسمت از نقشه ویژگی قرار میگیرد. سپس، مقدار بزرگترین عنصر آن پنجره به عنوان نماینده آن بخش در نقشه ویژگی جدید انتخاب میشود.
- «ادغام میانگین» (Average Pooling): در این حالت، مقدار میانگین اعضای هر پنجره با بخش متناظر در نقشه ویژگی جدید، جایگزین میشود.

یکی از مزایای لایه «ادغام» (Pooling) این است که نیازی به یادگیری پارامترها ندارد. با این حال، یکی از ایراداتش آن است که احتمال دارد برخی از جزئیات مهم در دادهها را از دست بدهد.
لایه تمام متصل
لایه «تمام متصل» (Fully Connected Layer) در انتهای معماری شبکه کانولوشن قرار میگیرد. در این لایه، نقشه ویژگی که تا اینجا به صورت ساختارهای ماتریسی ۲ یا ۳ بُعدی بوده است، به صورت برداری تک بُعدی یا به اصطلاح «مسطح» (Flatten) به یک یا چند لایه تمام متصل وارد میشود. هدف اصلی این لایه، تبدیل ویژگیهای سطح بالای تصویر به شکلی نهایی است که برای نمایش نتایج نهایی مناسب باشد. به عنوان مثال، لایه تمام متصل معمولاً در نقش طبقهبند استفاده میشود. در این لایه، از تابع فعالسازی Softmax برای طبقهبندی ورودیها استفاده میشود.
در ادامه، برخی از معماریهای معروف شبکههای عصبی کانولوشن را آوردهایم.
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
تا این قسمت از مطلب مجله فرادرس، یاد گرفتیم که شبکه عصبی کانولوشن چیست و شامل چه اجزایی است و به این ترتیب با نحوه عملکرد آن آشنا شدیم. در این بخش از مطلب به این موضوع میپردازیم که مزایا و معایب استفاده از شبکه عصبی کانولوشن چیست.
مزایا و معایب
استفاده از الگوریتمهای CNN در پردازش تصویر مزایا و معایبی دارد که به چند مورد از آنها میپردازیم.
مزایا
در ادامه، به برخی از مزایای شبکههای عصبی کانولوشن می پردازیم.
- عدم نیاز به نظارت انسانی در مرحله آموزش: این شبکهها با استفاده از مجموعه دادههای بزرگ میتوانند به صورت خودکار الگوها و اطلاعات مفید را از دادهها استخراج کنند و یاد بگیرند.
- دقت بالا: شبکههای کانولوشن تاکنون موفق بودهاند در زمینههای بسیاری ازجمله، «قطعهبندی» (Segmentation)، «شناسایی اشیا» (Object Recognition) و غیره نسبت به روشهای قدیمی، نظیر روشهای کلاسیک پردازش تصویر، به دقت بالاتری دست یابند.
- قابلیت تشخیص مناطق مورد نظر تصویر (Regions-of-Interest | ROI): CNNها برای تشخیص نواحی مورد نظر در تصویر یا توالیهای ویدیو، به دلیل قابلیت آنها در حفظ اطلاعات مکانی و زمانی مورد استفاده قرار میگیرند. به عنوان مثال، در تشخیص حرکت یا تحلیل رفتار اشیاء در ویدیوها، شبکههای کانولوشن میتوانند به خوبی عمل کنند.
- استفاده از سختافزارهای تخصصی: پیادهسازیهای سختافزاری مانند FPGA میتواند بهطور قابل توجهی نیاز به پردازنده و پهنای باند حافظه در پیادهسازی CNNها را کاهش دهند و در عین حال قدرت محاسباتی کافی را فراهم کند.
معایب
برخی از معایب استفاده از CNNها شامل موارد زیر هستند.
- نیاز به محاسبات زیاد: شبکههای کانولوشن برای اجرا نیاز به محاسبات زیادی دارند که این امر گاهی موجب میشود که در پردازش بلادرنگ به ویژه زمانی که از پردازندهای کم مصرف و کمهزینهتر استفاده میشود، عملکرد خوبی نداشته باشند.
- زمان آموزش طولانی و نیاز به دادههای حجیم: شبکههای کانولوشن به طور کلی نیاز به زمان آموزش طولانی و برای دستیابی به دقت بالا، نیاز به دادههای با حجم بالا دارند.
- وابستگی به سختافزار: CNNها معمولاً روی سختافزارهای قدرتمندی مانند پردازندههای گرافیکی (GPU) اجرا میشوند. این وابستگی به سختافزار، میتواند محدودیتهایی را برای استفاده از CNNها ایجاد کند. به عنوان مثال، ممکن است در دستگاههای کمتوان مانند تلفنهای هوشمند، عملکرد خوبی نداشته باشند.

سوالات متداول
در این قسمت از مطلب به سوالات پیرامون شبکههای عصبی کانولوشن میپردازیم.
شبکه عصبی کانولوشن چیست؟
در یادگیری عمیق، شبکه عصبی کانولوشن یا CNN نوعی از شبکههای عصبی عمیق است که بیشتر به تجزیه و تحلیل دادههای تصویری میپردازد. این شبکهها قابلیت تشخیص الگوها و ویژگیهای پیچیده در تصاویر را دارند و توانستهاند در زمینههای مختلفی از تشخیص چهره گرفته تا خودروهای خودران، به بهترین نحو ممکن عمل کنند.
مزیت اصلی استفاده از شبکه عصبی کانولوشن چیست؟
مزیت اصلی استفاده از CNN این است که برای دستهبندی تصاویر و شناسایی ویژگیهای مهم در تصاویر، نیازی به نظارت انسانی ندارد و در بسیاری از وظایف بینایی ماشین نسبت به روشهای قبلی به دقت بالایی دست یافته است.
لایه های مختلف شبکه عصبی کانولوشن چیست؟
شبکه عصبی کانولوشن معمولاً از سه نوع لایه کانولوشن، «ادغام» (Pooling) و تمام متصل تشکیل شده است.
جمعبندی
ما در این مطلب از مجله فرادرس، ابتدا به این موضوع پرداختیم که شبکه عصبی کانولوشن چیست و سپس بهطور مختصر، تاریخچه این دسته از شبکهها را مرور کردیم. در ادامه، معماری شبکهعصبی کانولوشن را معرفی کردیم و گفتیم شبکههای عصبی کانولوشن یا به عبارتی CNNها از ۳ لایه اصلی تشکیل شدهاند: لایههای کانولوشن، ادغام و تمام متصل. به این ترتیب، هر یک از این لایهها را توضیح دادیم. در انتها، مزایا و معایب شبکههای عصبی کانولوشن را بررسی و سوالات متداول پیرامون شبکه عصبی کانولوشن مطرح کردیم.
source