«شناسایی الگو» (Pattern Recognition)، شاخهای از علوم کامپیوتر است که به یافتن الگوها در دادهها میپردازد. این الگوها میتوانند به صورت قوانین منظمی در دادهها مانند همبستگیها، روندها یا به صورت ویژگیهای خاصی در آنها ظاهر شوند. شناسایی الگو در طیف گستردهای از کابردها از جمله پردازش تصویر، تشخیص گفتار، بیومتریک، تشخیص پزشکی و شناسایی تقلب استفاده میشود و یک زمینه مطالعاتی در حال رشد با طیف وسیعی از کاربردها است. ما در این مطلب از مجله فرادرس به این موضوع میپردازیم که شناسایی الگو چیست و چگونه کار میکند و در پایان به کاربردها و مزیتهای آن اشارهای خواهیم داشت.


شناسایی الگو چیست؟
شناسایی الگو، زمینهای از علوم کامپیوتر است که به یافتن خودکار الگوها و قوانین در دادهها میپردازد. این حوزه به عنوان یکی از زیرشاخههای یادگیری ماشین و هوش مصنوعی شناخته میشود و در کاربردهای متنوعی از جمله پردازش تصویر، شناسایی گفتار و تشخیص پزشکی مورد استفاده قرار میگیرد. تفکر اصلی پشت شناسایی الگو این است که مدل و الگوریتمهای ریاضی را به گونهای آموزش دهیم تا بتواند الگوها را در دادهها شناسایی کنند. این فرآیند با ارائه یک مجموعهداده آموزشی به مدلمان آغاز میشود که این مجموعه داده شامل ورودیها و خروجیهای متناظر با آن ورودیها است. ورودیها، نمونههایی از دادههای مورد بررسی و خروجیها، نشاندهنده الگوهای مرتبط با این ورودیها هستند.
برای مثال، اگر بخواهیم به مدلی آموزش دهیم که چگونه چهرهها را تشخیص دهد، مجموعه داده آموزشی، شامل تصاویر چهرهها – ورودی – و برچسبهای متناظر با هر چهره – خروجی – خواهد بود. برچسبهای تصاویر چهره میتوانند مشخص کننده نام یا شناسه فرد در تصویر باشند. بنابراین، اگر مدلی برای شناسایی چهرهها بر روی مجموعه دادهای از تصاویر با برچسبها آموزش ببیند، میتواند برای تشخیص چهرهها در یک جمعیت استفاده شود. همچنین مدل شناسایی گفتار میتواند برای تحلیل یک پیام صوتی به کار برود که در این صورت برای مثال، با ارائه پیامی به سیستم مورد نظر، اطلاعات متنی پیام را در اختیار کاربر قرار میدهد.
شناسایی الگو در علم داده
در دنیای علم داده، الگوها بسته به نوع و هدفی که از تحلیل داده داریم در انواع مختلفی مشاهده میشوند که عبارتند از:
- «الگوهای متوالی» (Sequential Patterns): به دنبالهای از رویدادها اشاره دارند و نظمی در دادههای متوالی را نشان میدهند. برای مثال، در دنبالههای خرید محصولات – که هنگام تحلیل دادههای مربوط به خرید محصولات مشاهده میشود – دنبالهای از قواعد در روند خرید محصولات وجود دارد. با شناسایی و درک این الگوهای متوالی، تحلیلگران میتوانند نگرشهایی نسبت به رفتار مصرفکننده، ترجیحات، یا روندهای مرتبط با فرآیند خرید را دریافت کنند.
- «الگوهای مکانی» (Spatial Pattern): به نظم و ترتیب موجود در توزیع دادهها در فضا و مکان گفته میشود. به عنوان مثال، این الگوها ممکن است مرتبط با توسعه یا شیوع بیماری در شهر باشند.
- «الگوهای زمانی» (Temporal Pattern): شامل تغییرات متناوب یا روندهای دورهای و همچنین «ناهنجاریها» (Anomalies) در دادههای سری زمانی هستند که شناسایی این الگوها میتواند بر اساس الگوهای زمانی گذشته و با هدف پیشبینی مقادیر آینده، برای مثال، تحلیل نوسانات بازار سهام انجام شود.
- «الگوهای ارتباطی» ( Association Patterns): ارتباط بین رویدادهای مشخصی را نشان میدهند. به عبارت دیگر، این الگوها همزمانی بین رخدادها را بیان میکنند. برای مثال، در حوزه بازاریابی و فروش میتوان متوجه شد که برخی از مشتریان به دنبال محصولات مشابه یا مکمل با محصولات خریداری شده خود هستند. این الگو نشاندهنده ارتباط بین خرید یک محصول و احتمال خرید محصولات مشابه است که شناسایی آنها میتواند به بهبود استراتژیهای فروش کمک کند. بنابراین،شرکتها میتوانند نیازها و ترجیحات مشتریان را بهتر شناسایی کنند و خدمات و محصولات مناسبتری را ارائه دهند.
- «الگوهای خوشهبندی» (Clustering Patterns): دادهها را بر اساس شباهت به یکدیگر گروهبندی میکنند که میتواند با هدف یافتن دادههای مشابه، تقسیمبندی دادهها، شناسایی ناهنجاریها و کشف الگوها انجام پذیرد.
شناسایی الگو چگونه کار می کند؟
شناسایی الگو فرآیندی است که در آن الگوها یا ساختارهای موجود در دادهها شناسایی و طبقهبندی یا «طبقهبندی» (Classification) میشوند.
این فرآیند شامل استخراج ویژگیهای معنیدار از دادهها و استفاده از آنها برای تصمیمگیری و پیشبینی است. در ادامه مراحل شناسایی الگو را آوردهایم.
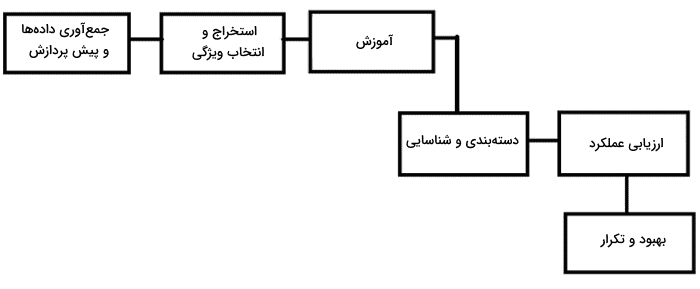
جمع آوری داده ها و پیش پردازش
این مرحله شامل جمعآوری دادههای مربوط به مسئله است که میخواهید الگوها را در آن شناسایی کنید که این دادهها ممکن است از منابع مختلفی مانند حسگرها، پایگاههای داده، اسناد متنی یا تصاویر بهدست بیاید. قبل از ورود به مرحله شناسایی، اغلب نیاز است که مرحله پیشپردازش انجام گیرد که این مرحله شامل پاکسازی، نرمالسازی یا تبدیل دادهها -به منظور کاهش بعد یا حذف دادههای شامل نویز است – که این کار اطمینان حاصل میکند که دادهها با کیفیت مناسب و سازگار با روشهای تحلیلی هستند.
استخراج و انتخاب ویژگی
استخراج ویژگی یکی از مراحل مهم در شناسایی الگو است که به انتخاب ویژگیهای مهم و تمایزدهنده از دادهها میپردازد. این ویژگیها باید در عین اینکه ابعاد دادهها را به حداقل میرسانند، اطلاعات حاصل از آنها بهترین توصیف را از الگوها ارائه دهند.
روشهای استخراج ویژگی متنوع و بسته به نوع داده و مسئله مورد نظر متفاوت هستند. برخی از روشهای معمول عبارتند از:
- «اندازهگیریهای آماری» (Statistical Measures)
- «تحلیل فرکانسی» (Frequency Analysis)
- «تبدیل موجک» (Wavelet Transforms)
- تولید «توصیفگرهای تصویری» (Image Descriptors)

در برخی موارد، دادههای خام ممکن است شامل تعداد زیادی ویژگی باشند که به اندازه یکسان اطلاعات مفید و مناسبی برای شناسایی الگو ارائه نمیدهند. در این موارد، نیاز است که با حذف نویز و حذف موارد تکراری، زیرمجموعهای از ویژگیها انتخاب شود. این کار موجب افزایش خاصیت تمایزپذیری ویژگیهای استخراج شده میشود و در نتیجه به افزایش کارایی محاسباتی، کاهش ابعاد و افزایش عملکرد سیستم شناسایی الگو کمک میکند.
مرحله آموزش
در این مرحله، مدل با استفاده از دادههای برچسبگذاری شده آموزش میبیند که الگوها قبلا در مجموعهداده آموزشی با استفاده از روشی شناسایی شدهاند. الگوریتم یادگیری، ارتباط بین ویژگیهای دادهها و برچسبهای آنها را یاد میگیرد. این فرایند میتواند به دو صورت نظارتشده یا بدون نظارت انجام شود. در یادگیری نظارتشده، برچسبها از قبل برای دادهها ارائه میشوند. در یادگیری بدون نظارت، الگوریتم الگوها و ساختارها را به صورت خودکار کشف میکند.
مرحله دسته بندی و شناسایی
پس از مرحله آموزش، سیستم شناسایی الگو توانایی دارد که الگوهای جدیدی که از قبل با آن سر و کار نداشته است را طبقهبندی کند یا تشخیص بدهد. مدل آموزش دیده، ویژگیهای دادههای جدید را استخراج کرده و بر اساس این ویژگیها، الگوها را طبقهبندی میکند. این طبقهبندی میتواند با استفاده از روشهای مختلفی مانند مدلهای آماری، درختهای تصمیم، ماشینهای بردار پشتیبان، شبکههای عصبی یا یادگیری عمیق انجام شود.
ارزیابی عملکرد
سیستم شناسایی الگو نیاز دارد که دقت و عملکرد خود را بسنجد یا به عبارتی در این مرحله توانایی سیستم در شناسایی صحیح الگوها مورد ارزیابی قرار میگیرد. معیارهای معمولی که به منظور ارزیابی سیستم مورد بررسی قرار میگیرند، شامل «دقت» (Accuracy)، «صحت و بازیابی» (Precision and Recall)، F-score و تحلیل «منحنی مشخصه عملکرد سیستم» ( ROC | Receiver operating characteristic) هستند. همچنین روشهای اعتبارسنجی مختلفی نظیر «اعتبار سنجی متقابل» (Cross Validation) و اعتبارسنجی متقابل k-fold (k-fold cross validation ) برای تخمینی قابل اعتماد از عمکرد سیستم، قبل از وارد شدن به محیط عملیاتی انجام میشوند.
بهبود و تکرار
در صورتی که عملکرد سیستم شناسایی الگو قابل قبول نباشد، میتوان به منظور بهبود آن، اقداماتی را انجام داد. در ادامه، اقدامات بیانشده را آوردهایم.
- بهبود روشهای استخراج ویژگی: روشهای استخراج ویژگی، دادههای خام را به ویژگیهایی تبدیل میکنند که برای الگوریتمهای یادگیری قابل پردازش باشند. اگر ویژگیهای استخراج شده مناسب نباشند، ممکن است الگوریتمهای یادگیری نتوانند الگوهای مطلوب را شناسایی کنند. بنابراین، میتوان با بهبود روشهای استخراج ویژگی، ویژگیهای بهتری استخراج کرد که منجر به بهبود عملکرد سیستم شناسایی الگو شود.
- اصلاح الگوریتمهای یادگیری: الگوریتمهای یادگیری، با استفاده از دادههای آموزشی، الگوها را یاد میگیرند. اگر الگوریتمهای یادگیری مناسب نباشند، ممکن است نتوانند الگوهای مطلوب را یاد بگیرند. بنابراین، میتوان با اصلاح الگوریتمهای یادگیری، الگوریتمهای بهتری طراحی کرد که منجر به بهبود عملکرد سیستم شناسایی الگو شود.
- جمعآوری دادههای بیشتر: دادههای آموزشی، نقش مهمی در عملکرد سیستم شناسایی الگو دارند. اگر دادههای آموزشی کافی نباشند، الگوریتمهای یادگیری ممکن است نتوانند الگوهای مطلوب را یاد بگیرند. بنابراین، میتوان با جمعآوری دادههای بیشتر، مجموعه دادههای آموزشی را افزایش داد که منجر به بهبود عملکرد سیستم شناسایی الگو شود.
در شناسایی الگو، انتخاب روشها و الگوریتمها به عوامل مختلفی از جمله، ویژگیهای داده، پیچیدگی الگوها و کاربرد مورد نظر بستگی دارد. به طور کلی، پیشرفتهای حاصل در حوزه یادگیری ماشین، یادگیری عمیق و هوش مصنوعی، تأثیر قابل توجهی بر حوزه شناسایی الگو داشتهاند. این پیشرفتها امکان ایجاد سیستمهای شناسایی الگو پیچیده و دقیقتری را فراهم کردهاند که قادر به تشخیص الگوهای پیچیده در دادههای مختلف هستند.
انواع مدل های شناسایی الگو
تا اینجا یادگرفتیم که شناسایی الگو چیست و مراحل اجرای یک الگوریتم شناسایی الگو به صورت کلی شامل چه مواردی میشود. حال،چند الگوریتم یادگیری ماشین را که در حوزه شناسایی الگو به کار میروند را به همراه توضیح مختصری، در ادامه آوردهایم.
برخی از مدلهای متداول شناسایی الگو به شرح زیر هستند.
- «k نزدیکترین همسایه» ( k-NN | k-Nearest Neighbours): الگوریتم K نزدیکترین همسایه، الگوها را بر اساس مقایسه آنها با دادههای آموزشی برچسبخورده طبقهبندی میکند. به این ترتیب، برچسبی را که تعداد بیشتری از دادههای همسایه دارا هستند، را به الگوی مربوطه اختصاص میدهد.
- «ماشین بردار پشتیبان» ( SVM |Supprt Vector Machine): ماشین بردار پشتیبان الگوریتم قدرتمندی است که برای مسائل رگرسیون و طبقهبندی به کار میرود. در مسائل طبقهبندی این الگوریتم به دنبال ایجاد «ابرصفحه» (Hyperplanes) برای جداسازی طبقههای دادهها است. علاوه مسئله طبقهبندی، SVM به صورت موثر نیز در مسائل رگرسیون کاربرد دارد. در این حالت، این الگوریتم سعی میکند یک ابرصفحه را به گونهای پیدا کند که تا حد ممکن به دادههای آموزشی منطبق شوند. به این ترتیب، SVM میتواند با دقت و کارایی بالا در مسائل مختلف مانند طبقهبندی و پیشبینی مورد استفاده قرار گیرد.
- «درخت تصمیم» (Decision Tree): درختان تصمیم، از یک ساختار درختی برای طبقهبندی الگوها استفاده میکنند. این درخت از گرههای تصمیم و گرههای برگ تشکیل شده است. گرههای تصمیم، شرایطی را بر روی ویژگیها اعمال میکنند تا داده را به دو زیرمجموعه تقسیم کنند. این تقسیمبندی به صورت متوالی انجام میشود تا زمانی که به گرههای برگ برسیم. گرههای برگ، برچسبهای نهایی طبقه را نشان میدهند.
- «جنگل تصادفی» (Random Forest): یکی از روشهای «یادگیری جمعی» (Ensemble Learning) است که از چندین درخت تصمیم برای بهبود دقت و جلوگیری از «بیشبرازش» (Overfitting) استفاده میکند. این الگوریتم یک جنگل از درختان تصمیم ایجاد میکند و از برایند پیشبینیهای صورت گرفته به منظور تصمیمگیری نهایی برای مسئله طبقهبندی استفاده میکند.
- «شبکههای عصبی» (Neural Networks): شبکههای عصبی، به ویژه ساختارهای یادگیری عمیق، در شناسایی الگوها بسیار موفق بودهاند. این شبکهها از لایههایی به وجود آمده از نورونهای مصنوعی تشکیل شده است که از طریق فرآیند آموزش، الگوهای پیچیده را با تنظیم وزنهای نورونها یاد میگیرند. «شبکههای عصبی پیچشی» (Convolutional Neural Networks) از شبکههای پرکاربردی است که برای وظایف شناسایی تصویر، نظیر تشخیص اشیاء، تفکیک الگوها، تشخیص چهره، و طبقهبندی تصاویر مورد استفاده قرار میگیرند.
- «بیز ساده» (Naive Bayes): بیز ساده یکی از الگوریتمهای یادگیری ماشین است که برای طبقهبندی دادهها استفاده میشود. این الگوریتم بر اساس قضیه بیز عمل کرده و فرض میکند که ویژگیهای تعریف شده برای هر داده مستقل از یکدیگر هستند. الگوریتم بیز ساده برای پیشبینی برچسب دادهها، ابتدا با استفاده از مجموعهداده آموزشی احتمال وقوع هر طبقه را به صورت جداگانه محاسبه میکند. سپس، برای هر طبقه، احتمال وقوع هر ویژگی محاسبه میشود. با استفاده از نتایج همین محاسبات و به کمک قضیه بیز، میتوان احتمال تخصیص یک نمونهداده به هر یک از طبقههای تعریف شده در مسئله مورد نظر را بهدست آورد که در اینصورت طبقه هر داده پیشبینی میشود.
- «تحلیل مولفههای اصلی» (Principal Component Analysis): یکی از روشهای کاهش ابعاد است که برای تبدیل دادههای با ابعاد بالاتر به ابعاد پایینتر، مورد استفاده قرار میگیرد. این روش، محورهایی را شناسایی میکند که دادهها در آن بیشترین واریانس را نشان میدهند. این محورها که بیشترین مقدارهای ویژه به آنها اختصاص یافتهاند و نسبت به یکدیگر «متعامد» (Orthogonal) هستند، «مولفههای اصلی» (Principal Components) نامیده میشوند. با انتقال فضای ویژگی به محورهای شناسایی شده، میتوان دادهها را در فضایی با ابعاد پایینتر نمایش داد.
الگوریتمهایی که در بالا به آن اشاره داشتیم تنها چند نمونه از روشهایی هستند که در زمینه شناسایی الگو مورد استفاده قرار میگیرند هر الگوریتم نقاط قوت و ضعف خود را دارد، و انتخاب الگوریتم بستگی به ماهیت مسئله و ویژگیهای ذاتی مجموعه داده نظیر میزان نویز، چگونگی توزیع، ابعاد و غیره بستگی دارد.
کابردهای شناسایی الگو
شناسایی الگو در حوزههای متعددی کاربرد دارد که در ادامه چند نمونه را بیان کردیم.
- «بیومتریک»(Biometrics:): شناسایی الگو در سیستمهای بیومتریک بر اساس الگوهای منحصر به فرد فیزیولوژیکی یا رفتاری با هدف شناسایی و احراز هویت افراد صورت میگیرد. این سیستمها به طور معمول شامل شناسایی اثرانگشت،عنبه چشم، تشخیص چهره، صدا و شناسایی امضا هستند که این وظایف با هدف کنترل دسترسی، تأیید هویت و برررسیهای پزشکی قانونی انجام میشوند.
- تشخیص پزشکی: شناسایی الگو در تصویربرداری پزشکی میتواند برای طیف گستردهای از کاربردها از جمله تحلیل الگوها در تصاویر پزشکی مانند تصاویر رادیولوژی، امآرای و سیتی اسکن با هدف تشخیص خودکار ناهنجاریها، تومورها یا پیشبینی بیماریها استفاده شود.
- تولید و کنترل کیفیت:شناسایی الگو همچنین در فرآیندهای تولید برای کنترل کیفیت، تشخیص عیوب و بررسی و ارزیابی محصولات نهایی بهکار میرود. این امر شامل تحلیل الگوها در تصاویر، دادههای حسگر یا پارامترهای فرآیند برای شناسایی انحرافات از الگوهای مورد انتظار و اطمینان از کیفیت و انطباق محصول با استانداردهای صنعت میشود.
- «بیوانفورماتیک» (Bioinformatics): روشهای شناسایی الگو در تحلیل دادههای زیستی، مانند توالیهای DNA، ساختار پروتئینها و غیره، کاربردهای زیادی دارند. این روشها میتوانند به شناسایی ژنها، پیشبینی ساختار پروتئینی، کشف دارو و درک فرایندهای زیستی کمک کنند.
- تحلیل بازارهای مالی: در بازارهای مالی، شناسایی الگو برای یافتن الگوهای موجود در دادههای بازار سهام، نرخ تبادل ارز یا شاخصهای معاملاتی استفاده میشود. این امر میتواند به تحلیل فنی، پیشبینی روند بازار و تصمیمگیری در مسائل سرمایهگذاری کمک کند.
- نظارت محیطی: شناسایی الگو در سیستمهای نظارت محیطی برای تحلیل الگوها در دادههای حسگر و شناسایی تغییرات یا ناهنجاریهای محیطی بهکار میرود که در اموری مانند پیشبینی آبوهوا، نظارت آلودگی و سیستمهای هشدار زودهنگام در مواقع بلایای طبیعی کمک میکند.

موارد بیان شده در بالا تنها چند نمونه از کاربردهای شناسایی الگو هستند. شناسایی الگو در حوزههای مختلف از جمله رباتیک، بازیهای رایانهای، کشاورزی، سیستمهای توصیه و غیره نیز بهکار میرود.
مزایای شناسایی الگو چیست؟
شناسایی الگو در تحلیل دادهها و فرایندهای تصمیمگیری مزایای زیادی دارد. در ادامه به چند مورد اصلی از این مزایا اشاره میکنیم.
جستجو و بازیابی کارامد
روشهای شناسایی الگو امکان جستجو و بازیابی بهینه الگوهای خاص در دادههای بزرگ در زمان مناسبی فراهم میکنند و وظایفی نظیر بازیابی اطلاعات یا بازیابی مبتنی بر محتوای تصویر را تسهیل میکنند.
پردازش آنی
پیشرفتهای اخیر در زمینه شناسایی الگو، امکان پردازش بیدرنگ یا نزدیک به آن را، به ویژه برای «جریاندادهها» (data streams) را ایجاد کرده است. این امر امکان شناسایی الگوها در زمانهای حیاتی و تصمیمگیریهای سریع را فراهم میکند.
انتخاب ویژگی
روشهای شناسایی الگو به ما کمک میکنند ویژگیهای مهم و اطلاعاتی را که برای تشخیص بهینه و دقیق الگوها لازم است، شناسایی کنیم که به این فرایند انتخاب ویژگی میگویند. روشهای انتخاب ویژگی در شناسایی الگو شامل چند دسته اصلی هستند که در ادامه به آن اشاره میکنیم.
روشهای مبتنی بر فیلتر
روشهای«فیلتر» (Filter)، ویژگیهای مهم را بر اساس معیارهای آماری انتخاب میکنند. این روشها از الگوریتم طبقهبندیکننده مستقل هستند و به همین دلیل، مجموعه ویژگیهای انتخاب شده توسط آنها بر روی مدلهای مختلف تعمیمپذیری بیشتری دارند و بر روی هیچ الگوریتم طبقهبندی خاصی تنظیم نمیشود که البته، همین امر میتواند منجر به کاهش دقت مدل شود.یکی از مزایای اصلی روشهای فیلتر، کاهش بار محاسباتی نسبت به سایر روشهای انتخاب ویژگی است که این امر باعث میشود دادهها را بتوان به ابعاد بالاتری تعمیم داد. عیب این رویکرد این است که ممکن است ویژگیهای مناسب برای مدل انتخاب نشوند زیرا مدل در جریان کار نیست و نمیتواند تأثیر ویژگیها را در عملکرد مدل ارزیابی کند. شکل زیر طرح کلی این روش را بیان می کند.

در ادامه، نمونههایی از این دسته از روشها را اشاره میکنیم.
- انتخاب ویژگی با «آزمون تی» (T test): این آزمون روشی آماری برای مقایسه میانگین دو گروه از دادهها است و برای ارزیابی تفاوت در میانگین یک ویژگی خاص بین دو طبقه استفاده شود.
- انتخاب ویژگی با روش «تحلیل واریانس» (ANOVA | Analysis of Variance): یکی از روشهای آماری است که برای بررسی میانگین دو یا چند گروه استفاده میشود که از نظر آماری متفاوت هستند.
- انتخاب ویژگی با اطلاعات متقابل (Mutual Information): این روش آماری، میزان ارتباط بین دو متغیر را اندازهگیری میکند. انتخاب ویژگی، از این روش برای اندازهگیری میزان ارتباط بین هر ویژگی و متغیر هدف (خروجی) استفاده میکند. ویژگیهایی که وابستگی متقابل بیشتری با متغیر هدف دارند، برای تخمین خروجی مناسبتر هستند.
روشهای مبتنی بر بستهبندی
روشهای «بستهبندی» (Wrapper)، از عملکرد یک الگوریتم طبقهبندیکننده به عنوان معیاری برای انتخاب زیرمجموعهای از ویژگی ها استفاده میکند. در این روش یکی از الگوریتمهای طبقهبندی آموزش داده میشود و زیر مجموعهای از بهترین ویژگیها با استفاده از آن ارزیابی میشود. روشهای بستهبندی به صورت ضمنی به وابستگیهای بین ویژگیها و «تکرارها» (Redundancies) حین انتخاب زیرمجموعه بهترین ویژگیها توجه میکنند. این دسته از روشهای بستهبندی به دلیل استفاده از مدل در فرآیند انتخاب ویژگی، از نظر محاسباتی سنگین هستند. با این حال، از لحاظ رویکرد انتخاب ویژگی بسیار خوب عمل میکنند و زیرمجموعهای از ویژگیهایی را انتخاب میکنند که دقت مدل را به طور قابل توجهی بهبود بخشد. شکل زیر، مراحل اجرای روش را نشان میدهد.

برخی از نمونههای رایج روشهای بستهبندی را در ادامه بیان میکنیم.
- «انتخاب ویژگی رو به جلو» (Forward Selection): انتخاب رو به جلو یک روش تکراری است که با انتخاب یک ویژگی آغاز میشود. در هر تکرار، ویژگیای را انتخاب میکنیم که بیشترین تأثیر را بر بهبود نتایج مدل داشته باشد. این روند تا زمانی که اضافه کردن ویژگی جدید باعث بهبود عملکرد مدل نشود ادامه مییابد.
- «حذف رو به عقب» (Backward Elmination): حذف رو به عقب روشی است که با تمام ویژگیهای موجود شروع میشود و در هر تکرار، کماهمیتترین ویژگی را حذف میکند. این فرآیند تا زمانی که حذف ویژگی منجر به بهبود عملکرد مدل نشود، تکرار میشود.
روشهای تعبیه شده
«روشهای تعبیه شده» (Embedded)، ترکیبی از ویژگیهای روشهای فیلتر و مدل هستند و به عنوان راه حلی میانی در نظر گرفته میشوند. در این روشها به جای استفاده از مدلی مجزا به منظور ارزیابی زیر مجموعهای از ویژگیها، انتخاب زیرمجموعه ویژگی را به عنوان بخشی از فرآیند یادگیری مدل انجام میدهند. به عبارت دیگر، در روشهای تعبیه شده، انتخاب ویژگی و آموزش مدل به طور همزمان انجام میشود. طرح کلی روش تعبیه شده در شکل زیر نشان داده شده است.

برخی از نمونههای محبوب این دسته از روشها را در ادامه اشاره میکنیم.
- انتخاب ویژگی با استفاده از مدلهای «منظمسازی» (Regularization): در این دسته از روشها، از مدلهای مدلهای منظمسازی نظیر «رگرسیون لاسو» (Lasso regression) یا «رگرسیون ستیغی» (Ridge Regression) برای انتخاب ویژگی استفاده میشوند. روشهای منظمسازی معمولاً با طبقهبندیکنندههای خطی – به عنوان مثال، SVM، رگرسیون لجستیک – همراه هستند و ضرایب ویژگیهایی که تأثیر کمی بر دقت بالای مدل دارند را کاهش میدهند یا جریمه میکنند.
- الگوریتمهای مبتنی بر درخت تصمیم: الگوریتمهایی مانند درخت تصمیم و جنگل تصادفی، به صورت ذاتی در هنگام آموزش، انتخاب ویژگی انجام میدهند. این الگوریتمها در هر مرحله از پیمایش درخت، ویژگیهایی را انتخاب میکنند که بیشترین اطلاعات را برای تصمیمگیری درست ارائه میدهند.
مقیاسپذیری
تجزیه و تحلیل دادههای حجیم با استفاده از شبکههای عصبی، امکان شناسایی الگوها در مجموعه دادههای بزرگ و پیچیده را فراهم میکند و آنها را به برنامههای کاربردی دنیای واقعی با حجم زیادی از دادهها مقیاسپذیر کنند.

تا این قسمت از مطلب آموختیم شناسایی الگو چیست و چگونه کار میکند، سپس با انواع مدلها و و با برخی از مزایای قابلتوجهی که این شاخه در حوزه تحلیل داده داشته است آشنا شدیم. حال با توجه به مطالبی که آموختهایم، ممکن است این سوال پیش بیاید که تفاوت یادگیری ماشین با شناسایی الگو چیست. در ادامه به این موضوع میپردازیم.
تفاوت بین یادگیری ماشین و شناسایی الگو چیست؟
به بیان ساده، یادگیری ماشین، شاخهای وسیع در علم هوش مصنوعی است که شامل انواع روشها برای ایجاد الگوریتمها و مدلهایی است که قابلیت یادگیری از دادهها را دارند. اما، شناسایی الگو زیرشاخهای از یادگیری ماشین است که که بر روی تشخیص و تفسیر الگوها تمرکز دارد که این امور معمولا با روشهای یادگیری ماشین صورت میپذیرد. البته، روشها و الگوریتمهای مختلفی ممکن است در این فرایند به کار روند که تنها به یادگیری ماشین محدود نشوند.
سوالات رایج
تا این قسمت از مطلب، مروری داشتیم بر اینکه شناسایی الگو چیست و چگونه کار میکند. سپس، با برخی از الگوریتمهای محبوب در این حوزه آشنا شدیم و همچنین، مزایای استفاده از الگوریتم شناسایی الگو را بیان کردیم. اکنون میخواهیم برخی از سوالات رایج مرتبط با شناسایی الگو را مورد بررسی قرار دهیم.
رویکرد آماری در شناسایی الگو چیست؟
«رویکرد آماری برای شناسایی الگو» ( SPR | Statistical Pattern Recognition)، زمینهای از تجزیهوتحلیل دادهها است که از مدلها و الگوریتمهای ریاضی برای شناسایی الگوها در مجموعهدادههای بزرگ استفاده میکند. این رویکرد میتواند برای کارهای مختلفی مانند شناسایی دستخط یا گفتار، طبقهبندی اشیاء در تصاویر و پردازش زبان طبیعی استفاده شود.
مثال ساده شناسایی الگو چیست؟
از نمونههای کاربردی شناسایی الگو میتوان به شناسایی و احراز هویت، تشخیص پلاک خودرو، تحلیل اثر انگشت، تشخیص چهره و احراز هویت مبتنی بر صدا اشاره کرد.
بهترین روش شناسایی الگو چیست؟
شبکههای عصبی عمیق به عنوان یکی از بهترین و پیشرفتهترین روشها برای این کار شناخته میشود. این روش میتواند از الگوهای پیچیده و غیرخطی یاد بگیرد و الگو و اطلاعات مفیدی را از دادهها استخراج کند.
جمعبندی
«شناسایی الگو» (Pattern Recognition) در علم هوش مصنوعی به عنوان یکی از زمینههای مهم مطالعاتی شناخته میشود که با هدف شناسایی و تفسیر الگوها و ساختارهای مفهومی از حجم زیادی از دادهها انجام میشود.
ما در این مطلب از مجله فرادرس آموختیم که شناسایی الگو چیست و مراحل گام به گام یک الگوریتم شناسایی الگو را شرح دادیم. در ادامه برخی از مدلهای مورد استفاده در این زمینه را معرفی و به اختصار توضیح دادیم و در نهایت به کابردها و مزایای استفاده از سیستم شناسایی الگو در مسائل مختلف پرداختیم. به طور کلی، شناسایی الگو قابلیت استفاده در هر نوع صنعتی را دارا است، زیرا در هر کجا که داده وجود داشته باشد شباهتی هم میان دادهها پیدا میشود. بنابراین، بررسی امکان پیادهسازی این فناوری در کابردهای مختلف برای افزایش کارایی آنها منطقی است.
source